 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouteLLM: Learning to Route LLMs with Preference Data
Jun 26, 2024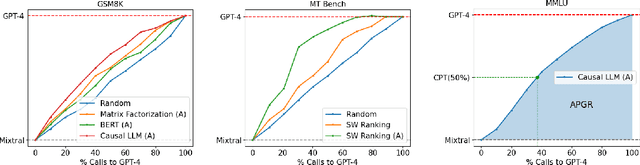
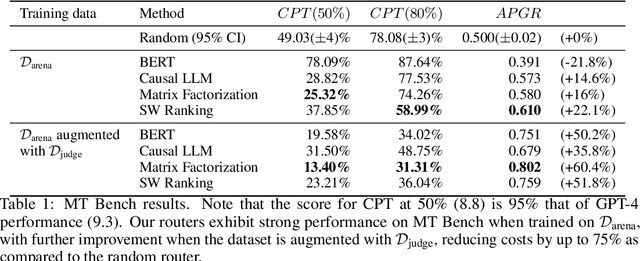
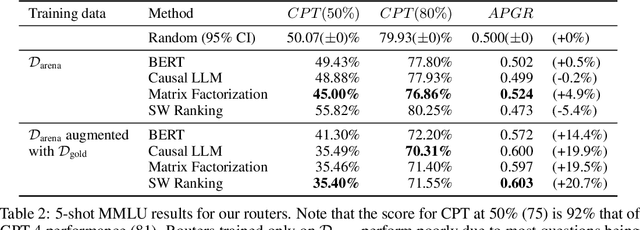
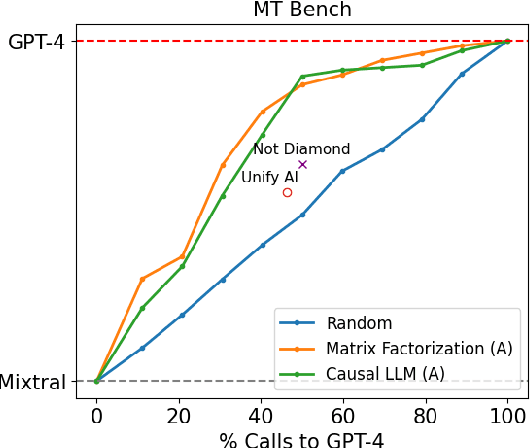
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Jack of All Tasks, Master of Many: Designing General-purpose Coarse-to-Fine Vision-Language Model
Dec 19, 2023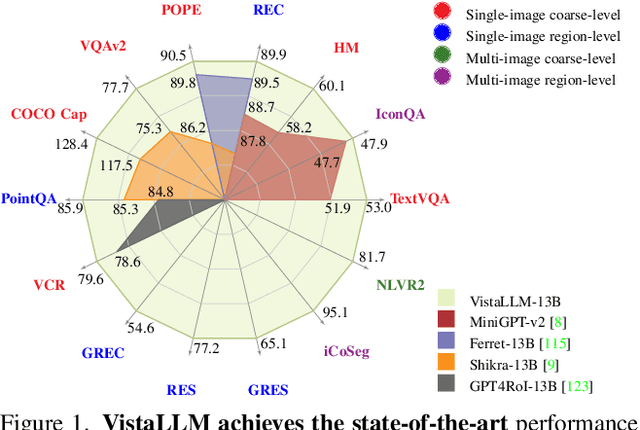
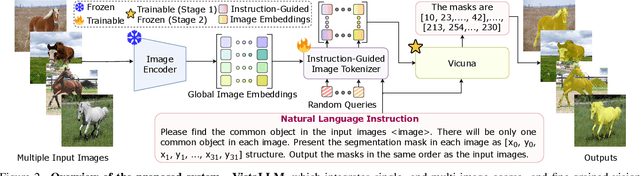

The ability of large language models (LLMs) to process visual inputs has given rise to general-purpose vision systems, unifying various vision-language (VL) tasks by instruction tuning. However, due to the enormous diversity in input-output formats in the vision domain, existing general-purpose models fail to successfully integrate segmentation and multi-image inputs with coarse-level tasks into a single framework. In this work, we introduce VistaLLM, a powerful visual system that addresses coarse- and fine-grained VL tasks over single and multiple input images using a unified framework. VistaLLM utilizes an instruction-guided image tokenizer that filters global embeddings using task descriptions to extract compressed and refined features from numerous images. Moreover, VistaLLM employs a gradient-aware adaptive sampling technique to represent binary segmentation masks as sequences, significantly improving over previously used uniform sampling. To bolster the desired capability of VistaLLM, we curate CoinIt, a comprehensive coarse-to-fine instruction tuning dataset with 6.8M samples. We also address the lack of multi-image grounding datasets by introducing a novel task, AttCoSeg (Attribute-level Co-Segmentation), which boosts the model's reasoning and grounding capability over multiple input images. Extensive experiments on a wide range of V- and VL tasks demonstrate the effectiveness of VistaLLM by achieving consistent state-of-the-art performance over strong baselines across all downstream tasks. Our project page can be found at https://shramanpramanick.github.io/VistaLLM/.
Llama 2: Open Foundation and Fine-Tuned Chat Models
Jul 19, 2023



In this work, we develop and release Llama 2, a collection of pretrained and fine-tuned large language models (LLMs) ranging in scale from 7 billion to 70 billion parameters. Our fine-tuned LLMs, called Llama 2-Chat, are optimized for dialogue use cases. Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models. We provide a detailed description of our approach to fine-tuning and safety improvements of Llama 2-Chat in order to enable the community to build on our work and contribute to the responsible development of LLMs.
Learning Easily Updated General Purpose Text Representations with Adaptable Task-Specific Prefixes
May 22, 2023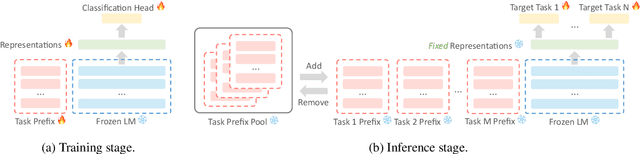


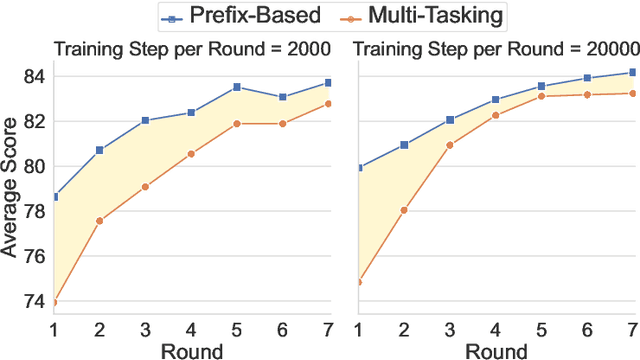
Many real-world applications require making multiple predictions from the same text. Fine-tuning a large pre-trained language model for each downstream task causes computational burdens in the inference time due to several times of forward passes. To amortize the computational cost, freezing the language model and building lightweight models for downstream tasks based on fixed text representations are common solutions. Accordingly, how to learn fixed but general text representations that can generalize well to unseen downstream tasks becomes a challenge. Previous works have shown that the generalizability of representations can be improved by fine-tuning the pre-trained language model with some source tasks in a multi-tasking way. In this work, we propose a prefix-based method to learn the fixed text representations with source tasks. We learn a task-specific prefix for each source task independently and combine them to get the final representations. Our experimental results show that prefix-based training performs better than multi-tasking training and can update the text representations at a smaller computational cost than multi-tasking training.
Residual Prompt Tuning: Improving Prompt Tuning with Residual Reparameterization
May 06, 2023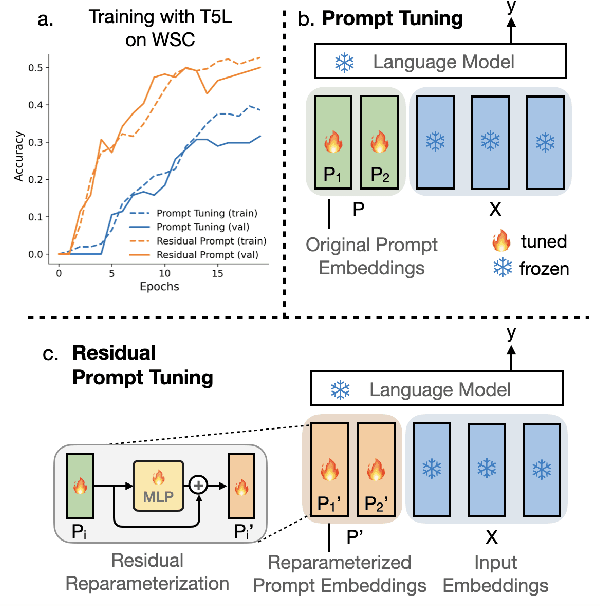
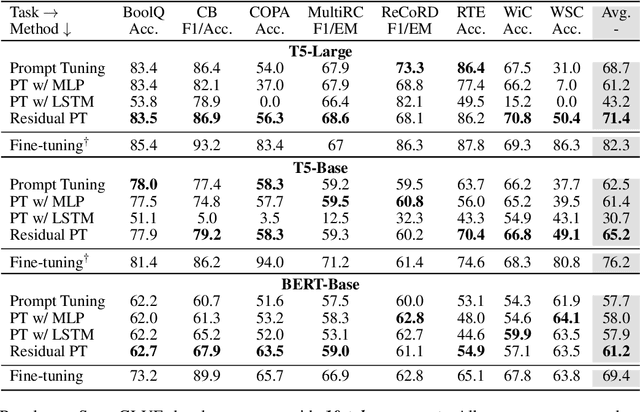

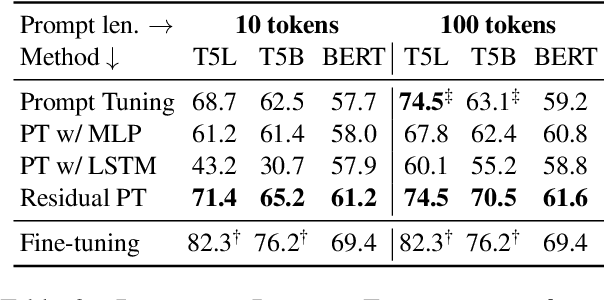
Prompt tuning is one of the successful approaches for parameter-efficient tuning of pre-trained language models. Despite being arguably the most parameter-efficient (tuned soft prompts constitute <0.1% of total parameters), it typically performs worse than other efficient tuning methods and is quite sensitive to hyper-parameters. In this work, we introduce Residual Prompt Tuning - a simple and efficient method that significantly improves the performance and stability of prompt tuning. We propose to reparameterize soft prompt embeddings using a shallow network with a residual connection. Our experiments show that Residual Prompt Tuning significantly outperforms prompt tuning on SuperGLUE benchmark. Notably, our method reaches +7 points improvement over prompt tuning with T5-Base and allows to reduce the prompt length by 10x without hurting performance. In addition, we show that our approach is robust to the choice of learning rate and prompt initialization, and is effective in few-shot settings.
Progressive Prompts: Continual Learning for Language Models
Jan 29, 2023



We introduce Progressive Prompts - a simple and efficient approach for continual learning in language models. Our method allows forward transfer and resists catastrophic forgetting, without relying on data replay or a large number of task-specific parameters. Progressive Prompts learns a new soft prompt for each task and sequentially concatenates it with the previously learned prompts, while keeping the base model frozen. Experiments on standard continual learning benchmarks show that our approach outperforms state-of-the-art methods, with an improvement >20% in average test accuracy over the previous best-preforming method on T5 model. We also explore a more challenging continual learning setup with longer sequences of tasks and show that Progressive Prompts significantly outperforms prior methods.
Uniform Masking Prevails in Vision-Language Pretraining
Dec 10, 2022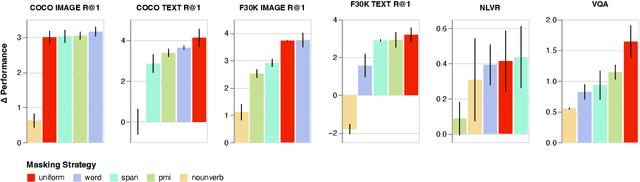


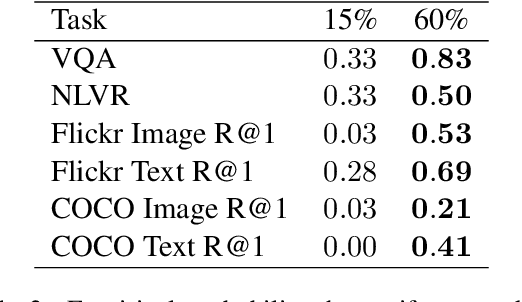
Masked Language Modeling (MLM) has proven to be an essential component of Vision-Language (VL) pretraining. To implement MLM, the researcher must make two design choices: the masking strategy, which determines which tokens to mask, and the masking rate, which determines how many tokens to mask. Previous work has focused primarily on the masking strategy while setting the masking rate at a default of 15\%. In this paper, we show that increasing this masking rate improves downstream performance while simultaneously reducing performance gap among different masking strategies, rendering the uniform masking strategy competitive to other more complex ones. Surprisingly, we also discover that increasing the masking rate leads to gains in Image-Text Matching (ITM) tasks, suggesting that the role of MLM goes beyond language modeling in VL pretraining.
Logical Satisfiability of Counterfactuals for Faithful Explanations in NLI
May 25, 2022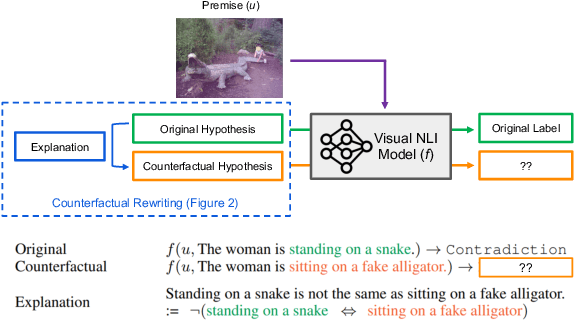


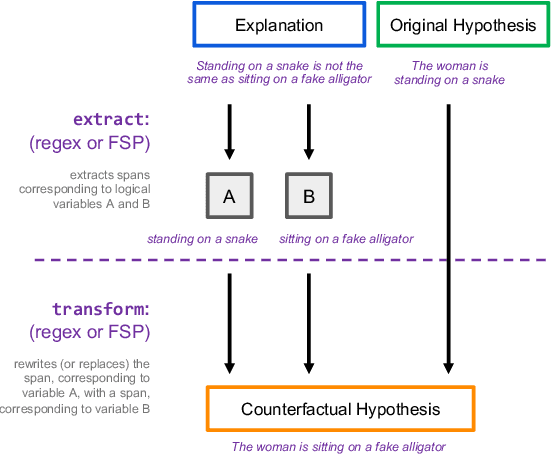
Evaluating an explanation's faithfulness is desired for many reasons such as trust, interpretability and diagnosing the sources of model's errors. In this work, which focuses on the NLI task, we introduce the methodology of Faithfulness-through-Counterfactuals, which first generates a counterfactual hypothesis based on the logical predicates expressed in the explanation, and then evaluates if the model's prediction on the counterfactual is consistent with that expressed logic (i.e. if the new formula is \textit{logically satisfiable}). In contrast to existing approaches, this does not require any explanations for training a separate verification model. We first validate the efficacy of automatic counterfactual hypothesis generation, leveraging on the few-shot priming paradigm. Next, we show that our proposed metric distinguishes between human-model agreement and disagreement on new counterfactual input. In addition, we conduct a sensitivity analysis to validate that our metric is sensitive to unfaithful explanations.
UniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
Oct 14, 2021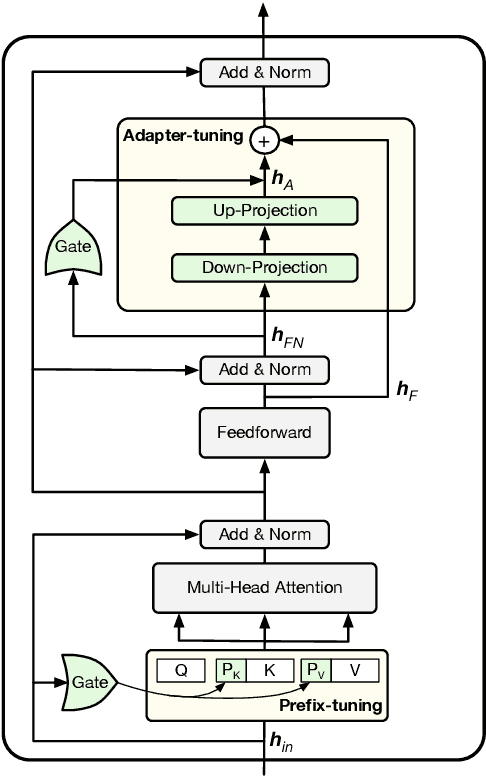
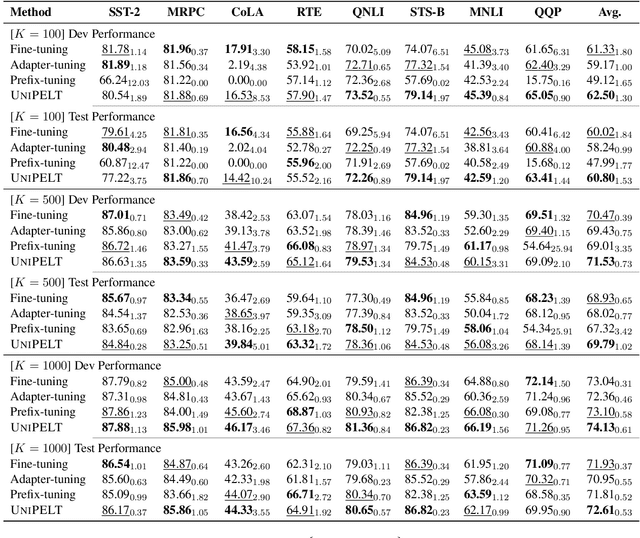
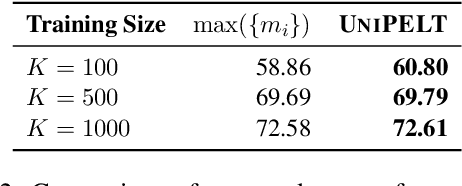
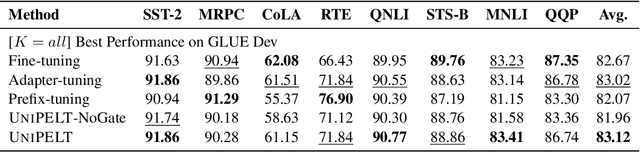
Conventional fine-tuning of pre-trained language models tunes all model parameters and stores a full model copy for each downstream task, which has become increasingly infeasible as the model size grows larger. Recent parameter-efficient language model tuning (PELT) methods manage to match the performance of fine-tuning with much fewer trainable parameters and perform especially well when the training data is limited. However, different PELT methods may perform rather differently on the same task, making it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and downstream tasks. In light of model diversity and the difficulty of model selection, we propose a unified framework, UniPELT, which incorporates different PELT methods as submodules and learns to activate the ones that best suit the current data or task setup. Remarkably, on the GLUE benchmark, UniPELT consistently achieves 1~3pt gains compared to the best individual PELT method that it incorporates and even outperforms fine-tuning under different setups. Moreover, UniPELT often surpasses the upper bound when taking the best performance of all its submodules used individually on each task, indicating that a mixture of multiple PELT methods may be inherently more effective than single methods.
Unsupervised Learning of Dense Visual Representations
Nov 11, 2020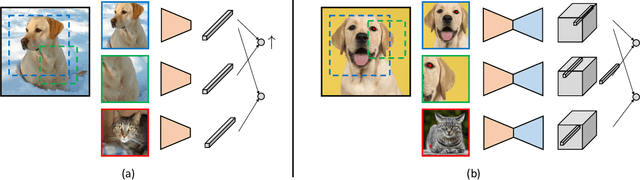


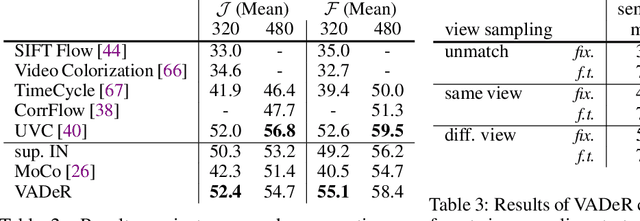
Contrastive self-supervised learning has emerged as a promising approach to unsupervised visual representation learning. In general, these methods learn global (image-level) representations that are invariant to different views (i.e., compositions of data augmentation) of the same image. However, many visual understanding tasks require dense (pixel-level) representations. In this paper, we propose View-Agnostic Dense Representation (VADeR) for unsupervised learning of dense representations. VADeR learns pixelwise representations by forcing local features to remain constant over different viewing conditions. Specifically, this is achieved through pixel-level contrastive learning: matching features (that is, features that describes the same location of the scene on different views) should be close in an embedding space, while non-matching features should be apart. VADeR provides a natural representation for dense prediction tasks and transfers well to downstream tasks. Our method outperforms ImageNet supervised pretraining (and strong unsupervised baselines) in multiple dense prediction tasks.