 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPELT: A Unified Framework for Parameter-Efficient Language Model Tuning
Paper and Code
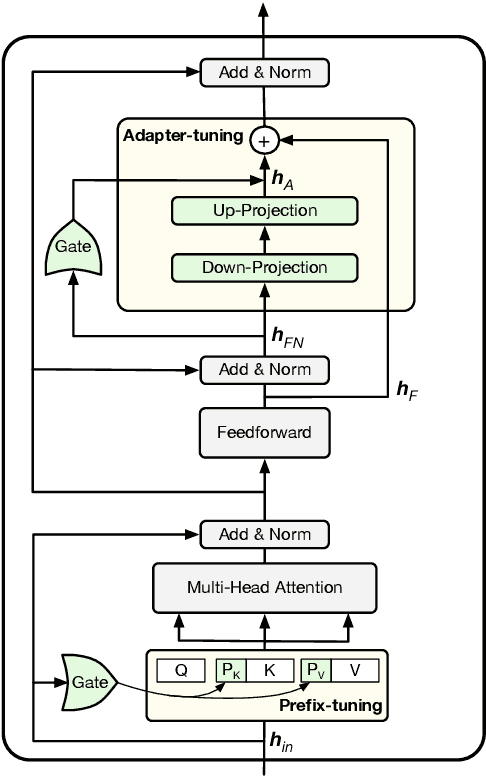
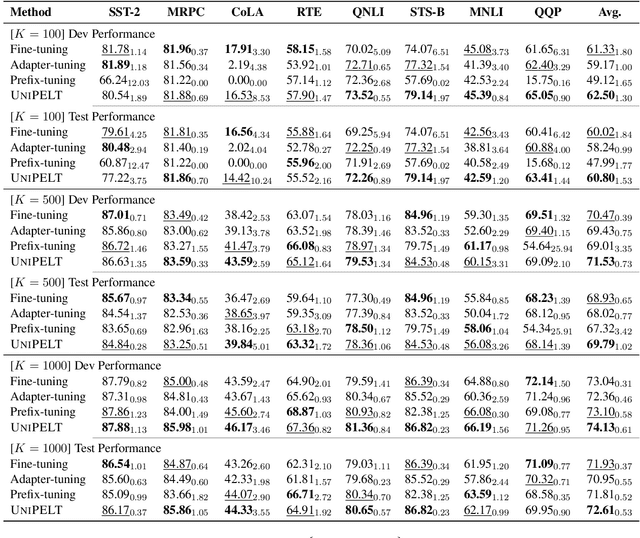
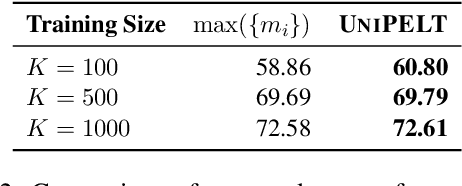
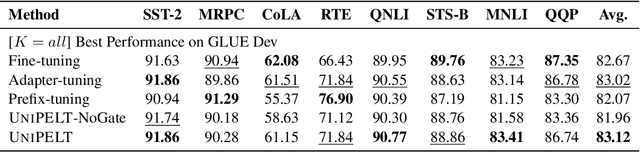
Conventional fine-tuning of pre-trained language models tunes all model parameters and stores a full model copy for each downstream task, which has become increasingly infeasible as the model size grows larger. Recent parameter-efficient language model tuning (PELT) methods manage to match the performance of fine-tuning with much fewer trainable parameters and perform especially well when the training data is limited. However, different PELT methods may perform rather differently on the same task, making it nontrivial to select the most appropriate method for a specific task, especially considering the fast-growing number of new PELT methods and downstream tasks. In light of model diversity and the difficulty of model selection, we propose a unified framework, UniPELT, which incorporates different PELT methods as submodules and learns to activate the ones that best suit the current data or task setup. Remarkably, on the GLUE benchmark, UniPELT consistently achieves 1~3pt gains compared to the best individual PELT method that it incorporates and even outperforms fine-tuning under different setups. Moreover, UniPELT often surpasses the upper bound when taking the best performance of all its submodules used individually on each task, indicating that a mixture of multiple PELT methods may be inherently more effective than single methods.