 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMA Policy Gradient: Taming Reinforcement Learning for LLMs with EMA Anchor and Top-k KL
Feb 04, 2026Reinforcement Learning (RL) has enabled Large Language Models (LLMs) to acquire increasingly complex reasoning and agentic behaviors. In this work, we propose two simple techniques to improve policy gradient algorithms for LLMs. First, we replace the fixed anchor policy during RL with an Exponential Moving Average (EMA), similar to a target network in deep Q-learning. Second, we introduce Top-k KL estimator, which allows for flexible interpolation between exact KL and sampled KL. We derive the stability conditions for using EMA anchor; moreover, we show that our Top-k KL estimator yields both unbiased KL values and unbiased gradients at any k, while bringing the benefits of exact KL. When combined with GRPO, the two techniques (EMA-PG) lead to a significant performance boost. On math reasoning, it allows R1-distilled Qwen-1.5B to reach 53.9% on OlympiadBench compared to 50.8% by GRPO. On agentic RL domains, with Qwen-3B base, EMA-PG improves GRPO by an average of 33.3% across 7 datasets of Q&A with search engines, including 29.7% $\rightarrow$ 44.1% on HotpotQA, 27.4% $\rightarrow$ 40.1% on 2WikiMultiHopQA. Overall, we show that EMA-PG is a simple, principled, and powerful approach to scaling RL for LLMs. Code: https://github.com/LunjunZhang/ema-pg
Report Cards: Qualitative Evaluation of Language Models Using Natural Language Summaries
Sep 01, 2024
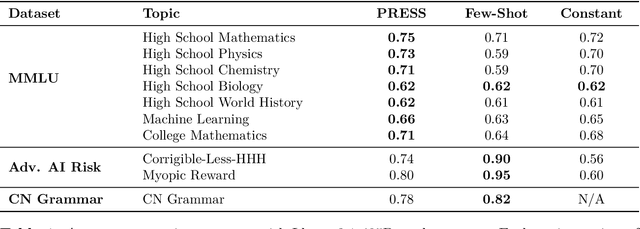
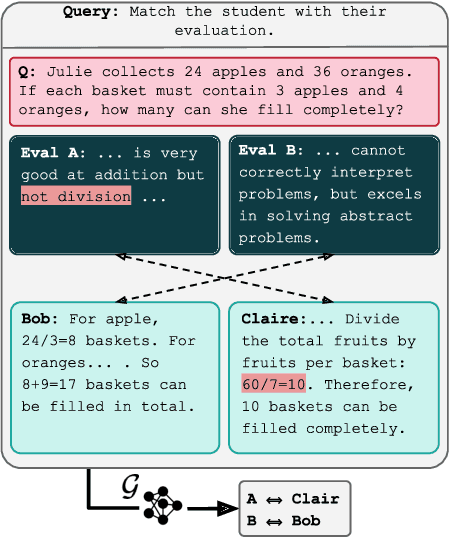
The rapid development and dynamic nature of large language models (LLMs) make it difficult for conventional quantitative benchmarks to accurately assess their capabilities. We propose report cards, which are human-interpretable, natural language summaries of model behavior for specific skills or topics. We develop a framework to evaluate report cards based on three criteria: specificity (ability to distinguish between models), faithfulness (accurate representation of model capabilities), and interpretability (clarity and relevance to humans). We also propose an iterative algorithm for generating report cards without human supervision and explore its efficacy by ablating various design choices. Through experimentation with popular LLMs, we demonstrate that report cards provide insights beyond traditional benchmarks and can help address the need for a more interpretable and holistic evaluation of LLMs.
Decomposed Prompting to Answer Questions on a Course Discussion Board
Jul 30, 2024We propose and evaluate a question-answering system that uses decomposed prompting to classify and answer student questions on a course discussion board. Our system uses a large language model (LLM) to classify questions into one of four types: conceptual, homework, logistics, and not answerable. This enables us to employ a different strategy for answering questions that fall under different types. Using a variant of GPT-3, we achieve $81\%$ classification accuracy. We discuss our system's performance on answering conceptual questions from a machine learning course and various failure modes.
* 6 pages. Published at International Conference on Artificial Intelligence in Education 2023. Code repository: https://github.com/brandonjaipersaud/piazza-qabot-gpt
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Using Large Language Models for Hyperparameter Optimization
Dec 07, 2023



This paper studies using foundational large language models (LLMs) to make decisions during hyperparameter optimization (HPO). Empirical evaluations demonstrate that in settings with constrained search budgets, LLMs can perform comparably or better than traditional HPO methods like random search and Bayesian optimization on standard benchmarks. Furthermore, we propose to treat the code specifying our model as a hyperparameter, which the LLM outputs, going beyond the capabilities of existing HPO approaches. Our findings suggest that LLMs are a promising tool for improving efficiency in the traditional decision-making problem of hyperparameter optimization.
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
Oct 10, 2023



There is growing evidence that pretraining on high quality, carefully thought-out tokens such as code or mathematics plays an important role in improving the reasoning abilities of large language models. For example, Minerva, a PaLM model finetuned on billions of tokens of mathematical documents from arXiv and the web, reported dramatically improved performance on problems that require quantitative reasoning. However, because all known open source web datasets employ preprocessing that does not faithfully preserve mathematical notation, the benefits of large scale training on quantitive web documents are unavailable to the research community. We introduce OpenWebMath, an open dataset inspired by these works containing 14.7B tokens of mathematical webpages from Common Crawl. We describe in detail our method for extracting text and LaTeX content and removing boilerplate from HTML documents, as well as our methods for quality filtering and deduplication. Additionally, we run small-scale experiments by training 1.4B parameter language models on OpenWebMath, showing that models trained on 14.7B tokens of our dataset surpass the performance of models trained on over 20x the amount of general language data. We hope that our dataset, openly released on the Hugging Face Hub, will help spur advances in the reasoning abilities of large language models.
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Sep 25, 2023



Recent advances in Language Model (LM) agents and tool use, exemplified by applications like ChatGPT Plugins, enable a rich set of capabilities but also amplify potential risks - such as leaking private data or causing financial losses. Identifying these risks is labor-intensive, necessitating implementing the tools, manually setting up the environment for each test scenario, and finding risky cases. As tools and agents become more complex, the high cost of testing these agents will make it increasingly difficult to find high-stakes, long-tailed risks. To address these challenges, we introduce ToolEmu: a framework that uses an LM to emulate tool execution and enables the testing of LM agents against a diverse range of tools and scenarios, without manual instantiation. Alongside the emulator, we develop an LM-based automatic safety evaluator that examines agent failures and quantifies associated risks. We test both the tool emulator and evaluator through human evaluation and find that 68.8% of failures identified with ToolEmu would be valid real-world agent failures. Using our curated initial benchmark consisting of 36 high-stakes tools and 144 test cases, we provide a quantitative risk analysis of current LM agents and identify numerous failures with potentially severe outcomes. Notably, even the safest LM agent exhibits such failures 23.9% of the time according to our evaluator, underscoring the need to develop safer LM agents for real-world deployment.
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft
Jun 05, 2023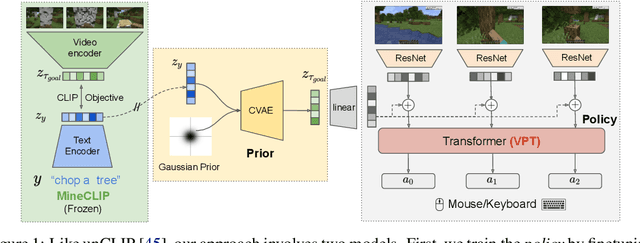



Constructing AI models that respond to text instructions is challenging, especially for sequential decision-making tasks. This work introduces an instruction-tuned Video Pretraining (VPT) model for Minecraft called STEVE-1, demonstrating that the unCLIP approach, utilized in DALL-E 2, is also effective for creating instruction-following sequential decision-making agents. STEVE-1 is trained in two steps: adapting the pretrained VPT model to follow commands in MineCLIP's latent space, then training a prior to predict latent codes from text. This allows us to finetune VPT through self-supervised behavioral cloning and hindsight relabeling, bypassing the need for costly human text annotations. By leveraging pretrained models like VPT and MineCLIP and employing best practices from text-conditioned image generation, STEVE-1 costs just $60 to train and can follow a wide range of short-horizon open-ended text and visual instructions in Minecraft. STEVE-1 sets a new bar for open-ended instruction following in Minecraft with low-level controls (mouse and keyboard) and raw pixel inputs, far outperforming previous baselines. We provide experimental evidence highlighting key factors for downstream performance, including pretraining, classifier-free guidance, and data scaling. All resources, including our model weights, training scripts, and evaluation tools are made available for further research.
Training on Thin Air: Improve Image Classification with Generated Data
May 24, 2023



Acquiring high-quality data for training discriminative models is a crucial yet challenging aspect of building effective predictive systems. In this paper, we present Diffusion Inversion, a simple yet effective method that leverages the pre-trained generative model, Stable Diffusion, to generate diverse, high-quality training data for image classification. Our approach captures the original data distribution and ensures data coverage by inverting images to the latent space of Stable Diffusion, and generates diverse novel training images by conditioning the generative model on noisy versions of these vectors. We identify three key components that allow our generated images to successfully supplant the original dataset, leading to a 2-3x enhancement in sample complexity and a 6.5x decrease in sampling time. Moreover, our approach consistently outperforms generic prompt-based steering methods and KNN retrieval baseline across a wide range of datasets. Additionally, we demonstrate the compatibility of our approach with widely-used data augmentation techniques, as well as the reliability of the generated data in supporting various neural architectures and enhancing few-shot learning.
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
May 22, 2023


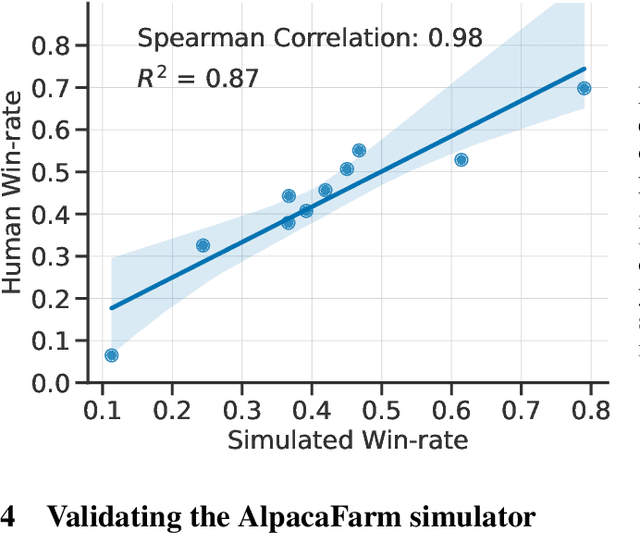
Large language models (LLMs) such as ChatGPT have seen widespread adoption due to their ability to follow user instructions well. Developing these LLMs involves a complex yet poorly understood workflow requiring training with human feedback. Replicating and understanding this instruction-following process faces three major challenges: the high cost of data collection, the lack of trustworthy evaluation, and the absence of reference method implementations. We address these challenges with AlpacaFarm, a simulator that enables research and development for learning from feedback at a low cost. First, we design LLM prompts to simulate human feedback that are 45x cheaper than crowdworkers and display high agreement with humans. Second, we propose an automatic evaluation and validate it against human instructions obtained on real-world interactions. Third, we contribute reference implementations for several methods (PPO, best-of-n, expert iteration, and more) that learn from pairwise feedback. Finally, as an end-to-end validation of AlpacaFarm, we train and evaluate eleven models on 10k pairs of real human feedback and show that rankings of models trained in AlpacaFarm match rankings of models trained on human data. As a demonstration of the research possible in AlpacaFarm, we find that methods that use a reward model can substantially improve over supervised fine-tuning and that our reference PPO implementation leads to a +10% improvement in win-rate against Davinci003. We release all components of AlpacaFarm at https://github.com/tatsu-lab/alpaca_farm.