 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlemma: An Open Language Model For Mathematics
Oct 16, 2023



We present Llemma, a large language model for mathematics. We continue pretraining Code Llama on the Proof-Pile-2, a mixture of scientific papers, web data containing mathematics, and mathematical code, yielding Llemma. On the MATH benchmark Llemma outperforms all known open base models, as well as the unreleased Minerva model suite on an equi-parameter basis. Moreover, Llemma is capable of tool use and formal theorem proving without any further finetuning. We openly release all artifacts, including 7 billion and 34 billion parameter models, the Proof-Pile-2, and code to replicate our experiments.
OpenWebMath: An Open Dataset of High-Quality Mathematical Web Text
Oct 10, 2023



There is growing evidence that pretraining on high quality, carefully thought-out tokens such as code or mathematics plays an important role in improving the reasoning abilities of large language models. For example, Minerva, a PaLM model finetuned on billions of tokens of mathematical documents from arXiv and the web, reported dramatically improved performance on problems that require quantitative reasoning. However, because all known open source web datasets employ preprocessing that does not faithfully preserve mathematical notation, the benefits of large scale training on quantitive web documents are unavailable to the research community. We introduce OpenWebMath, an open dataset inspired by these works containing 14.7B tokens of mathematical webpages from Common Crawl. We describe in detail our method for extracting text and LaTeX content and removing boilerplate from HTML documents, as well as our methods for quality filtering and deduplication. Additionally, we run small-scale experiments by training 1.4B parameter language models on OpenWebMath, showing that models trained on 14.7B tokens of our dataset surpass the performance of models trained on over 20x the amount of general language data. We hope that our dataset, openly released on the Hugging Face Hub, will help spur advances in the reasoning abilities of large language models.
ProofNet: Autoformalizing and Formally Proving Undergraduate-Level Mathematics
Feb 24, 2023We introduce ProofNet, a benchmark for autoformalization and formal proving of undergraduate-level mathematics. The ProofNet benchmarks consists of 371 examples, each consisting of a formal theorem statement in Lean 3, a natural language theorem statement, and a natural language proof. The problems are primarily drawn from popular undergraduate pure mathematics textbooks and cover topics such as real and complex analysis, linear algebra, abstract algebra, and topology. We intend for ProofNet to be a challenging benchmark that will drive progress in autoformalization and automatic theorem proving. We report baseline results on statement autoformalization via in-context learning. Moreover, we introduce two novel statement autoformalization methods: prompt retrieval and distilled backtranslation.
Explicit Knowledge Transfer for Weakly-Supervised Code Generation
Nov 30, 2022Large language models (LLMs) can acquire strong code-generation capabilities through few-shot learning. In contrast, supervised fine-tuning is still needed for smaller models to achieve good performance. Such fine-tuning demands a large number of task-specific NL-code pairs, which are expensive to obtain. In this paper, we attempt to transfer the code generation ability of an LLM to a smaller model with the aid of weakly-supervised data. More specifically, we propose explicit knowledge transfer (EKT), which uses the few-shot capabilities of a teacher LLM to create NL-code pairs that we then filter for correctness and fine-tune the student on. We evaluate EKT on the task of generating code solutions to math word problems from the GSM8k dataset. We find that EKT not only yields better performance than training with expert iteration, but also outperforms knowledge distillation, another form of knowledge transfer. A GPT-Neo 1.3B model trained using EKT with a GPT-J teacher achieves a 12.4% pass@100 on GSM8k, while the same student and teacher trained with knowledge distillation yield only a 3.7% pass@100. We also show that it is possible for a student model to outperform the teacher using EKT.
SummerTime: Text Summarization Toolkit for Non-experts
Sep 10, 2021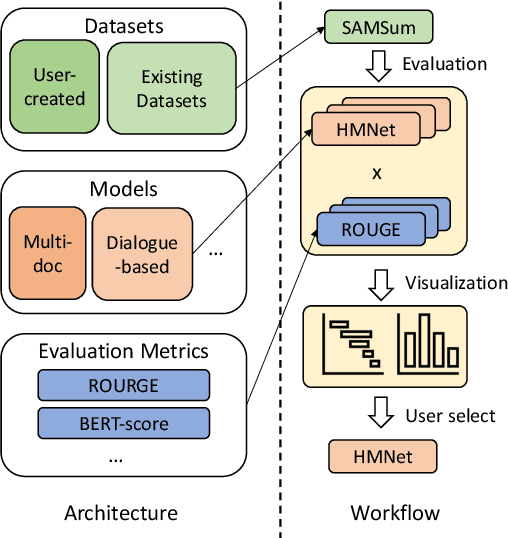
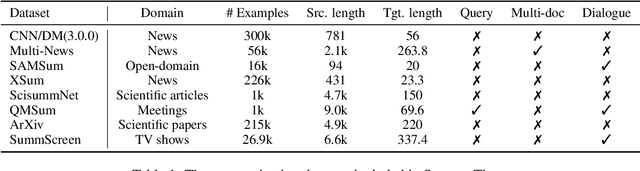

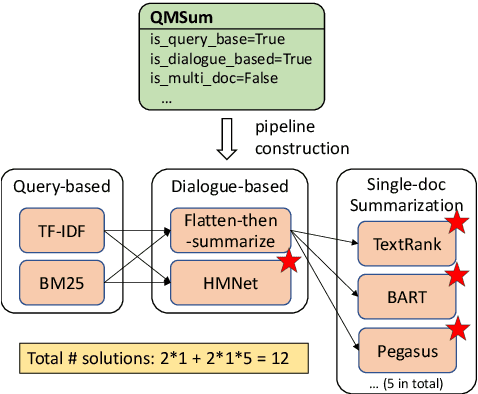
Recent advances in summarization provide models that can generate summaries of higher quality. Such models now exist for a number of summarization tasks, including query-based summarization, dialogue summarization, and multi-document summarization. While such models and tasks are rapidly growing in the research field, it has also become challenging for non-experts to keep track of them. To make summarization methods more accessible to a wider audience, we develop SummerTime by rethinking the summarization task from the perspective of an NLP non-expert. SummerTime is a complete toolkit for text summarization, including various models, datasets and evaluation metrics, for a full spectrum of summarization-related tasks. SummerTime integrates with libraries designed for NLP researchers, and enables users with easy-to-use APIs. With SummerTime, users can locate pipeline solutions and search for the best model with their own data, and visualize the differences, all with a few lines of code. We also provide explanations for models and evaluation metrics to help users understand the model behaviors and select models that best suit their needs. Our library, along with a notebook demo, is available at https://github.com/Yale-LILY/SummerTime.