 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Verification: Scaling Test-Time Compute with Multiple Verifiers
Feb 27, 2025
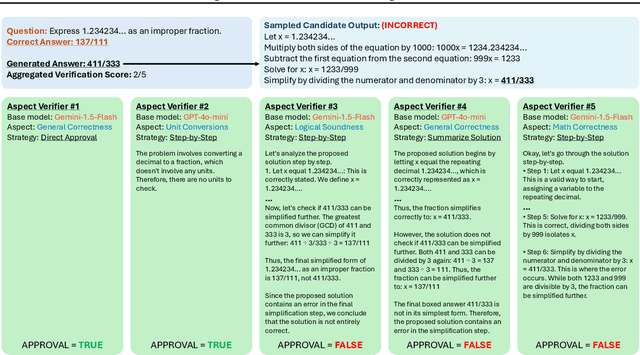


By utilizing more computational resources at test-time, large language models (LLMs) can improve without additional training. One common strategy uses verifiers to evaluate candidate outputs. In this work, we propose a novel scaling dimension for test-time compute: scaling the number of verifiers. We introduce Multi-Agent Verification (MAV) as a test-time compute paradigm that combines multiple verifiers to improve performance. We propose using Aspect Verifiers (AVs), off-the-shelf LLMs prompted to verify different aspects of outputs, as one possible choice for the verifiers in a MAV system. AVs are a convenient building block for MAV since they can be easily combined without additional training. Moreover, we introduce BoN-MAV, a simple multi-agent verification algorithm that combines best-of-n sampling with multiple verifiers. BoN-MAV demonstrates stronger scaling patterns than self-consistency and reward model verification, and we demonstrate both weak-to-strong generalization, where combining weak verifiers improves even stronger LLMs, and self-improvement, where the same base model is used to both generate and verify outputs. Our results establish scaling the number of verifiers as a promising new dimension for improving language model performance at test-time.
STEVE-1: A Generative Model for Text-to-Behavior in Minecraft
Jun 05, 2023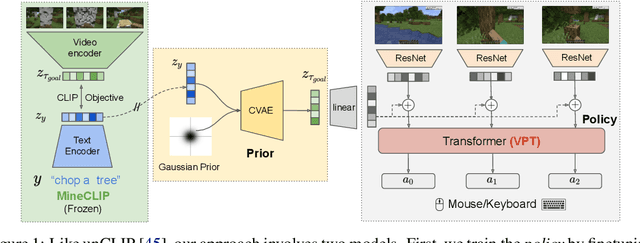



Constructing AI models that respond to text instructions is challenging, especially for sequential decision-making tasks. This work introduces an instruction-tuned Video Pretraining (VPT) model for Minecraft called STEVE-1, demonstrating that the unCLIP approach, utilized in DALL-E 2, is also effective for creating instruction-following sequential decision-making agents. STEVE-1 is trained in two steps: adapting the pretrained VPT model to follow commands in MineCLIP's latent space, then training a prior to predict latent codes from text. This allows us to finetune VPT through self-supervised behavioral cloning and hindsight relabeling, bypassing the need for costly human text annotations. By leveraging pretrained models like VPT and MineCLIP and employing best practices from text-conditioned image generation, STEVE-1 costs just $60 to train and can follow a wide range of short-horizon open-ended text and visual instructions in Minecraft. STEVE-1 sets a new bar for open-ended instruction following in Minecraft with low-level controls (mouse and keyboard) and raw pixel inputs, far outperforming previous baselines. We provide experimental evidence highlighting key factors for downstream performance, including pretraining, classifier-free guidance, and data scaling. All resources, including our model weights, training scripts, and evaluation tools are made available for further research.
Gram Barcodes for Histopathology Tissue Texture Retrieval
Nov 28, 2021
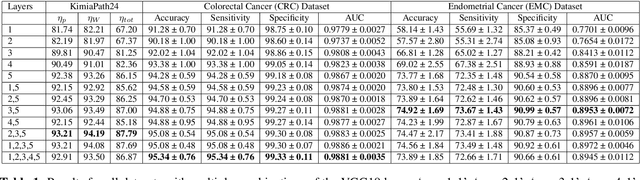
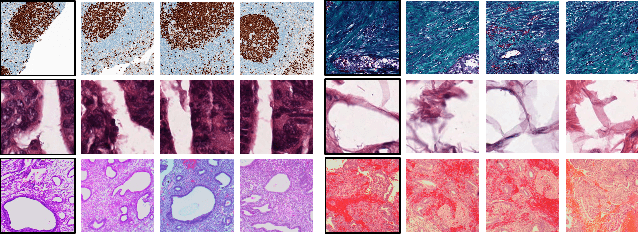
Recent advances in digital pathology have led to the need for Histopathology Image Retrieval (HIR) systems that search through databases of biopsy images to find similar cases to a given query image. These HIR systems allow pathologists to effortlessly and efficiently access thousands of previously diagnosed cases in order to exploit the knowledge in the corresponding pathology reports. Since HIR systems may have to deal with millions of gigapixel images, the extraction of compact and expressive image features must be available to allow for efficient and accurate retrieval. In this paper, we propose the application of Gram barcodes as image features for HIR systems. Unlike most feature generation schemes, Gram barcodes are based on high-order statistics that describe tissue texture by summarizing the correlations between different feature maps in layers of convolutional neural networks. We run HIR experiments on three public datasets using a pre-trained VGG19 network for Gram barcode generation and showcase highly competitive results.
Subtractive Perceptrons for Learning Images: A Preliminary Report
Sep 15, 2019
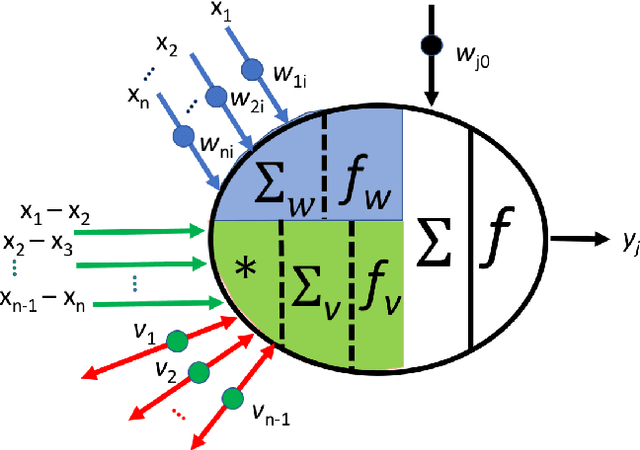
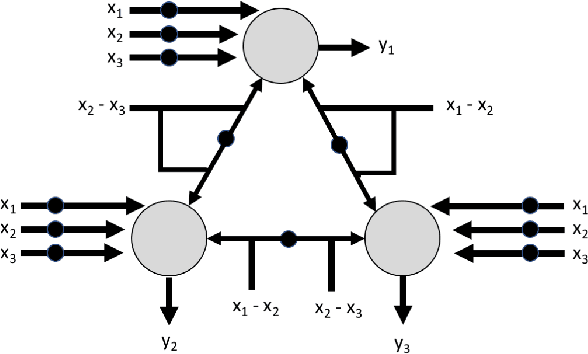
In recent years, artificial neural networks have achieved tremendous success for many vision-based tasks. However, this success remains within the paradigm of \emph{weak AI} where networks, among others, are specialized for just one given task. The path toward \emph{strong AI}, or Artificial General Intelligence, remains rather obscure. One factor, however, is clear, namely that the feed-forward structure of current networks is not a realistic abstraction of the human brain. In this preliminary work, some ideas are proposed to define a \textit{subtractive Perceptron} (s-Perceptron), a graph-based neural network that delivers a more compact topology to learn one specific task. In this preliminary study, we test the s-Perceptron with the MNIST dataset, a commonly used image archive for digit recognition. The proposed network achieves excellent results compared to the benchmark networks that rely on more complex topologies.