 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport Cards: Qualitative Evaluation of Language Models Using Natural Language Summaries
Paper and Code

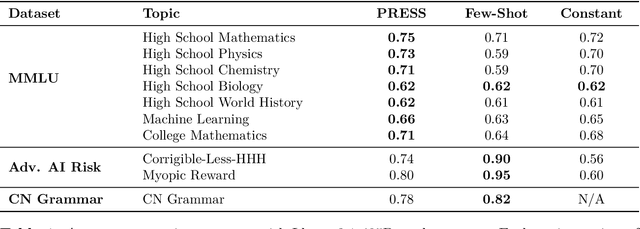
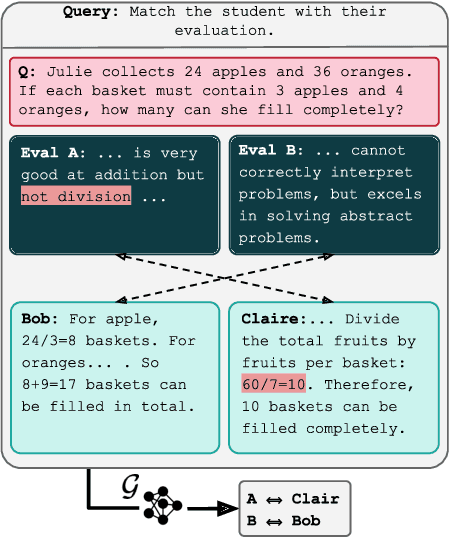
The rapid development and dynamic nature of large language models (LLMs) make it difficult for conventional quantitative benchmarks to accurately assess their capabilities. We propose report cards, which are human-interpretable, natural language summaries of model behavior for specific skills or topics. We develop a framework to evaluate report cards based on three criteria: specificity (ability to distinguish between models), faithfulness (accurate representation of model capabilities), and interpretability (clarity and relevance to humans). We also propose an iterative algorithm for generating report cards without human supervision and explore its efficacy by ablating various design choices. Through experimentation with popular LLMs, we demonstrate that report cards provide insights beyond traditional benchmarks and can help address the need for a more interpretable and holistic evaluation of LLMs.