 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Help-Seeking Behavior of Students Using LLMs vs. Web Search for Writing SQL Queries
Aug 15, 2024

Growth in the use of large language models (LLMs) in programming education is altering how students write SQL queries. Traditionally, students relied heavily on web search for coding assistance, but this has shifted with the adoption of LLMs like ChatGPT. However, the comparative process and outcomes of using web search versus LLMs for coding help remain underexplored. To address this, we conducted a randomized interview study in a database classroom to compare web search and LLMs, including a publicly available LLM (ChatGPT) and an instructor-tuned LLM, for writing SQL queries. Our findings indicate that using an instructor-tuned LLM required significantly more interactions than both ChatGPT and web search, but resulted in a similar number of edits to the final SQL query. No significant differences were found in the quality of the final SQL queries between conditions, although the LLM conditions directionally showed higher query quality. Furthermore, students using instructor-tuned LLM reported a lower mental demand. These results have implications for learning and productivity in programming education.
Decomposed Prompting to Answer Questions on a Course Discussion Board
Jul 30, 2024We propose and evaluate a question-answering system that uses decomposed prompting to classify and answer student questions on a course discussion board. Our system uses a large language model (LLM) to classify questions into one of four types: conceptual, homework, logistics, and not answerable. This enables us to employ a different strategy for answering questions that fall under different types. Using a variant of GPT-3, we achieve $81\%$ classification accuracy. We discuss our system's performance on answering conceptual questions from a machine learning course and various failure modes.
* 6 pages. Published at International Conference on Artificial Intelligence in Education 2023. Code repository: https://github.com/brandonjaipersaud/piazza-qabot-gpt
Neural Guided Constraint Logic Programming for Program Synthesis
Oct 26, 2018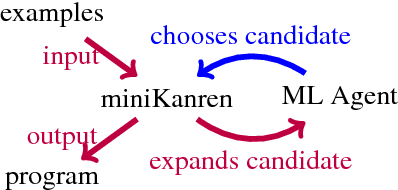
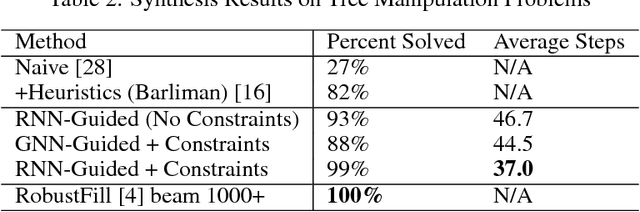
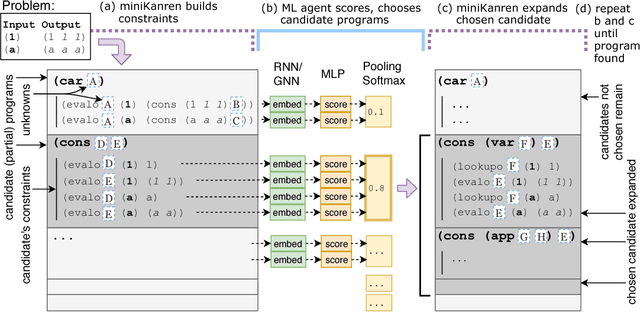
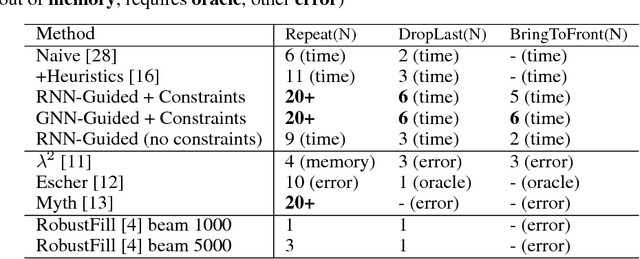
Synthesizing programs using example input/outputs is a classic problem in artificial intelligence. We present a method for solving Programming By Example (PBE) problems by using a neural model to guide the search of a constraint logic programming system called miniKanren. Crucially, the neural model uses miniKanren's internal representation as input; miniKanren represents a PBE problem as recursive constraints imposed by the provided examples. We explore Recurrent Neural Network and Graph Neural Network models. We contribute a modified miniKanren, drivable by an external agent, available at https://github.com/xuexue/neuralkanren. We show that our neural-guided approach using constraints can synthesize programs faster in many cases, and importantly, can generalize to larger problems.
Reviving and Improving Recurrent Back-Propagation
Aug 13, 2018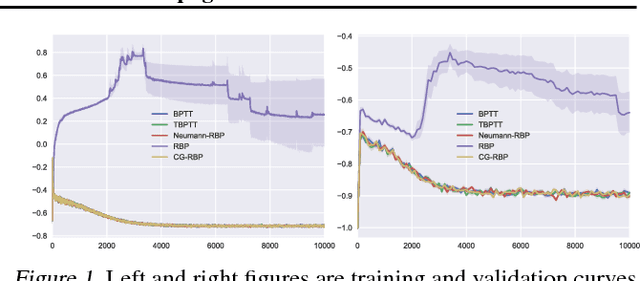
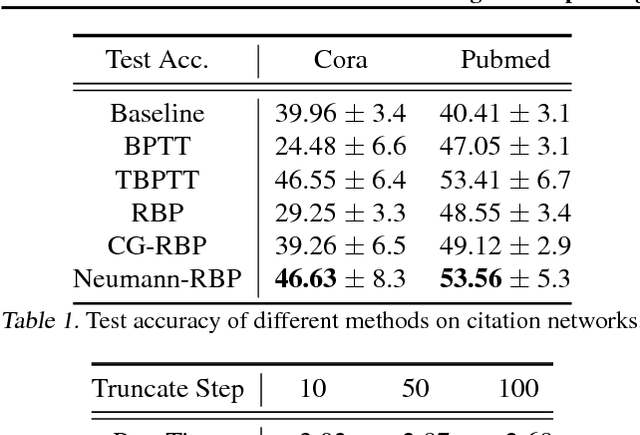
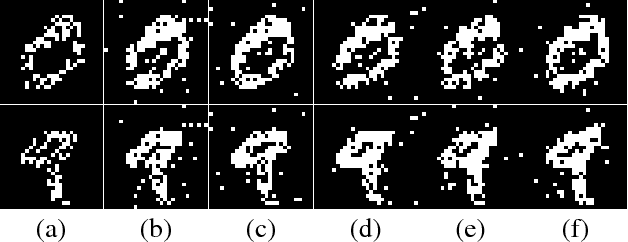

In this paper, we revisit the recurrent back-propagation (RBP) algorithm, discuss the conditions under which it applies as well as how to satisfy them in deep neural networks. We show that RBP can be unstable and propose two variants based on conjugate gradient on the normal equations (CG-RBP) and Neumann series (Neumann-RBP). We further investigate the relationship between Neumann-RBP and back propagation through time (BPTT) and its truncated version (TBPTT). Our Neumann-RBP has the same time complexity as TBPTT but only requires constant memory, whereas TBPTT's memory cost scales linearly with the number of truncation steps. We examine all RBP variants along with BPTT and TBPTT in three different application domains: associative memory with continuous Hopfield networks, document classification in citation networks using graph neural networks and hyperparameter optimization for fully connected networks. All experiments demonstrate that RBPs, especially the Neumann-RBP variant, are efficient and effective for optimizing convergent recurrent neural networks.
Inference in Probabilistic Graphical Models by Graph Neural Networks
May 25, 2018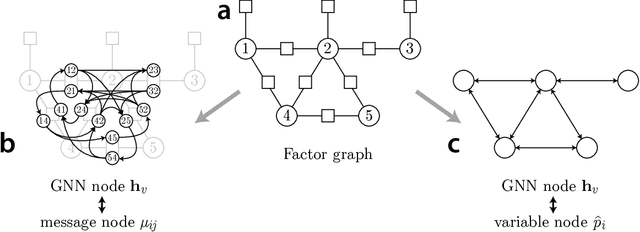
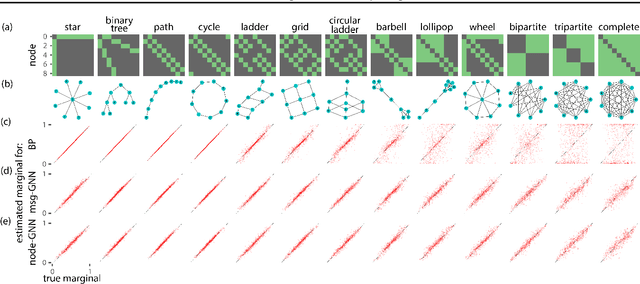
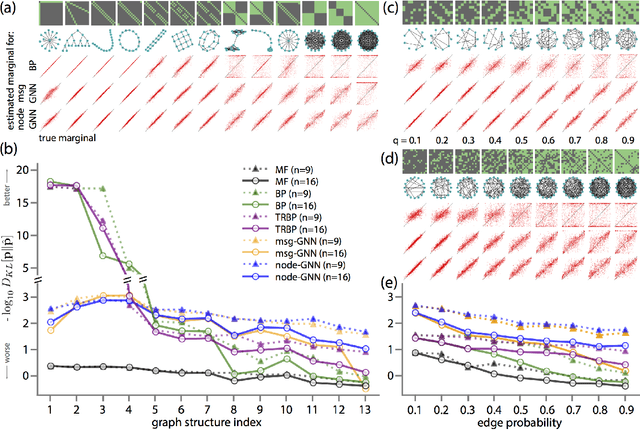
A fundamental computation for statistical inference and accurate decision-making is to compute the marginal probabilities or most probable states of task-relevant variables. Probabilistic graphical models can efficiently represent the structure of such complex data, but performing these inferences is generally difficult. Message-passing algorithms, such as belief propagation, are a natural way to disseminate evidence amongst correlated variables while exploiting the graph structure, but these algorithms can struggle when the conditional dependency graphs contain loops. Here we use Graph Neural Networks (GNNs) to learn a message-passing algorithm that solves these inference tasks. We first show that the architecture of GNNs is well-matched to inference tasks. We then demonstrate the efficacy of this inference approach by training GNNs on a collection of graphical models and showing that they substantially outperform belief propagation on loopy graphs. Our message-passing algorithms generalize out of the training set to larger graphs and graphs with different structure.
Learning deep structured active contours end-to-end
Mar 16, 2018
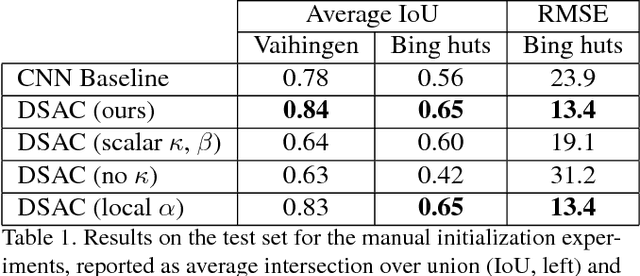
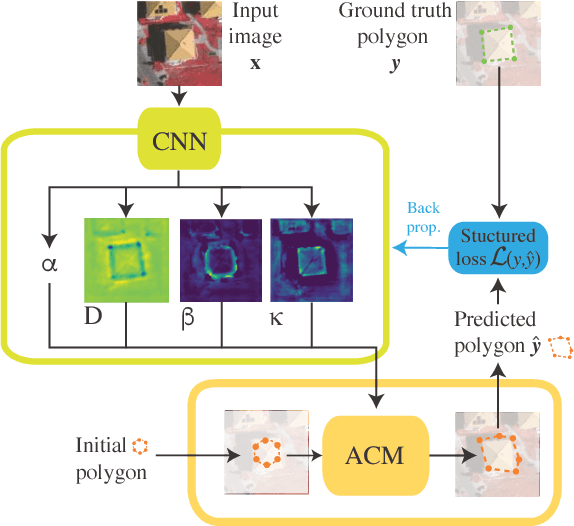
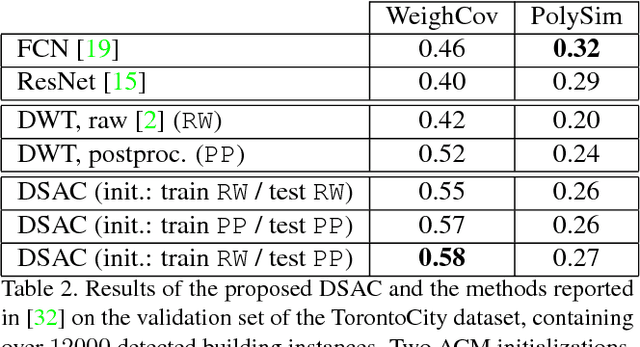
The world is covered with millions of buildings, and precisely knowing each instance's position and extents is vital to a multitude of applications. Recently, automated building footprint segmentation models have shown superior detection accuracy thanks to the usage of Convolutional Neural Networks (CNN). However, even the latest evolutions struggle to precisely delineating borders, which often leads to geometric distortions and inadvertent fusion of adjacent building instances. We propose to overcome this issue by exploiting the distinct geometric properties of buildings. To this end, we present Deep Structured Active Contours (DSAC), a novel framework that integrates priors and constraints into the segmentation process, such as continuous boundaries, smooth edges, and sharp corners. To do so, DSAC employs Active Contour Models (ACM), a family of constraint- and prior-based polygonal models. We learn ACM parameterizations per instance using a CNN, and show how to incorporate all components in a structured output model, making DSAC trainable end-to-end. We evaluate DSAC on three challenging building instance segmentation datasets, where it compares favorably against state-of-the-art. Code will be made available.