 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAPTS: A Weighted Allocation Probability Adjusted Thompson Sampling Algorithm for High-Dimensional and Sparse Experiment Settings
Jan 07, 2025Aiming for more effective experiment design, such as in video content advertising where different content options compete for user engagement, these scenarios can be modeled as multi-arm bandit problems. In cases where limited interactions are available due to external factors, such as the cost of conducting experiments, recommenders often face constraints due to the small number of user interactions. In addition, there is a trade-off between selecting the best treatment and the ability to personalize and contextualize based on individual factors. A popular solution to this dilemma is the Contextual Bandit framework. It aims to maximize outcomes while incorporating personalization (contextual) factors, customizing treatments such as a user's profile to individual preferences. Despite their advantages, Contextual Bandit algorithms face challenges like measurement bias and the 'curse of dimensionality.' These issues complicate the management of numerous interventions and often lead to data sparsity through participant segmentation. To address these problems, we introduce the Weighted Allocation Probability Adjusted Thompson Sampling (WAPTS) algorithm. WAPTS builds on the contextual Thompson Sampling method by using a dynamic weighting parameter. This improves the allocation process for interventions and enables rapid optimization in data-sparse environments. We demonstrate the performance of our approach on different numbers of arms and effect sizes.
Understanding Help-Seeking Behavior of Students Using LLMs vs. Web Search for Writing SQL Queries
Aug 15, 2024

Growth in the use of large language models (LLMs) in programming education is altering how students write SQL queries. Traditionally, students relied heavily on web search for coding assistance, but this has shifted with the adoption of LLMs like ChatGPT. However, the comparative process and outcomes of using web search versus LLMs for coding help remain underexplored. To address this, we conducted a randomized interview study in a database classroom to compare web search and LLMs, including a publicly available LLM (ChatGPT) and an instructor-tuned LLM, for writing SQL queries. Our findings indicate that using an instructor-tuned LLM required significantly more interactions than both ChatGPT and web search, but resulted in a similar number of edits to the final SQL query. No significant differences were found in the quality of the final SQL queries between conditions, although the LLM conditions directionally showed higher query quality. Furthermore, students using instructor-tuned LLM reported a lower mental demand. These results have implications for learning and productivity in programming education.
Opportunities for Adaptive Experiments to Enable Continuous Improvement that Trades-off Instructor and Researcher Incentives
Oct 18, 2023



Randomized experimental comparisons of alternative pedagogical strategies could provide useful empirical evidence in instructors' decision-making. However, traditional experiments do not have a clear and simple pathway to using data rapidly to try to increase the chances that students in an experiment get the best conditions. Drawing inspiration from the use of machine learning and experimentation in product development at leading technology companies, we explore how adaptive experimentation might help in continuous course improvement. In adaptive experiments, as different arms/conditions are deployed to students, data is analyzed and used to change the experience for future students. This can be done using machine learning algorithms to identify which actions are more promising for improving student experience or outcomes. This algorithm can then dynamically deploy the most effective conditions to future students, resulting in better support for students' needs. We illustrate the approach with a case study providing a side-by-side comparison of traditional and adaptive experimentation of self-explanation prompts in online homework problems in a CS1 course. This provides a first step in exploring the future of how this methodology can be useful in bridging research and practice in doing continuous improvement.
Using Adaptive Bandit Experiments to Increase and Investigate Engagement in Mental Health
Oct 13, 2023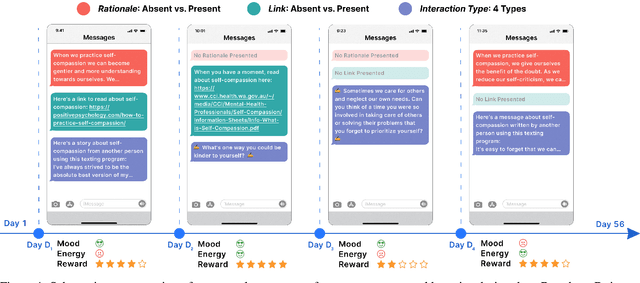

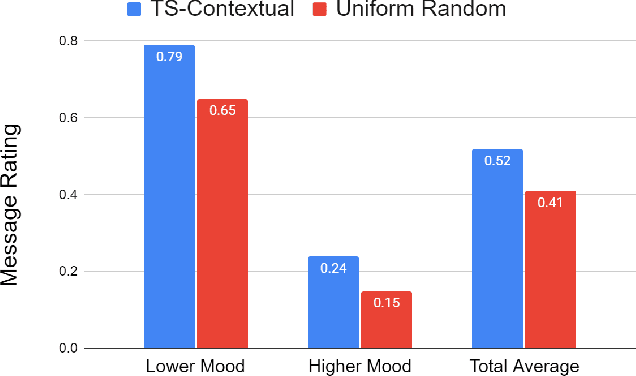

Digital mental health (DMH) interventions, such as text-message-based lessons and activities, offer immense potential for accessible mental health support. While these interventions can be effective, real-world experimental testing can further enhance their design and impact. Adaptive experimentation, utilizing algorithms like Thompson Sampling for (contextual) multi-armed bandit (MAB) problems, can lead to continuous improvement and personalization. However, it remains unclear when these algorithms can simultaneously increase user experience rewards and facilitate appropriate data collection for social-behavioral scientists to analyze with sufficient statistical confidence. Although a growing body of research addresses the practical and statistical aspects of MAB and other adaptive algorithms, further exploration is needed to assess their impact across diverse real-world contexts. This paper presents a software system developed over two years that allows text-messaging intervention components to be adapted using bandit and other algorithms while collecting data for side-by-side comparison with traditional uniform random non-adaptive experiments. We evaluate the system by deploying a text-message-based DMH intervention to 1100 users, recruited through a large mental health non-profit organization, and share the path forward for deploying this system at scale. This system not only enables applications in mental health but could also serve as a model testbed for adaptive experimentation algorithms in other domains.
Impact of Guidance and Interaction Strategies for LLM Use on Learner Performance and Perception
Oct 13, 2023Personalized chatbot-based teaching assistants can be crucial in addressing increasing classroom sizes, especially where direct teacher presence is limited. Large language models (LLMs) offer a promising avenue, with increasing research exploring their educational utility. However, the challenge lies not only in establishing the efficacy of LLMs but also in discerning the nuances of interaction between learners and these models, which impact learners' engagement and results. We conducted a formative study in an undergraduate computer science classroom (N=145) and a controlled experiment on Prolific (N=356) to explore the impact of four pedagogically informed guidance strategies and the interaction between student approaches and LLM responses. Direct LLM answers marginally improved performance, while refining student solutions fostered trust. Our findings suggest a nuanced relationship between the guidance provided and LLM's role in either answering or refining student input. Based on our findings, we provide design recommendations for optimizing learner-LLM interactions.
ABScribe: Rapid Exploration of Multiple Writing Variations in Human-AI Co-Writing Tasks using Large Language Models
Oct 10, 2023Exploring alternative ideas by rewriting text is integral to the writing process. State-of-the-art large language models (LLMs) can simplify writing variation generation. However, current interfaces pose challenges for simultaneous consideration of multiple variations: creating new versions without overwriting text can be difficult, and pasting them sequentially can clutter documents, increasing workload and disrupting writers' flow. To tackle this, we present ABScribe, an interface that supports rapid, yet visually structured, exploration of writing variations in human-AI co-writing tasks. With ABScribe, users can swiftly produce multiple variations using LLM prompts, which are auto-converted into reusable buttons. Variations are stored adjacently within text segments for rapid in-place comparisons using mouse-over interactions on a context toolbar. Our user study with 12 writers shows that ABScribe significantly reduces task workload (d = 1.20, p < 0.001), enhances user perceptions of the revision process (d = 2.41, p < 0.001) compared to a popular baseline workflow, and provides insights into how writers explore variations using LLMs.