 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming GenAI Policy to Prompting Instruction: An RCT of Scalable Prompting Interventions in a CS1 Course
Feb 17, 2026Despite universal GenAI adoption, students cannot distinguish task performance from actual learning and lack skills to leverage AI for learning, leading to worse exam performance when AI use remains unreflective. Yet few interventions teaching students to prompt AI as a tutor rather than solution provider have been validated at scale through randomized controlled trials (RCTs). To bridge this gap, we conducted a semester-long RCT (N=979) with four ICAP framework-based instructional conditions varying in engagement intensity with a pre-test, immediate and delayed post-test and surveys. Mixed methods analysis results showed: (1) All conditions significantly improved prompting skills, with gains increasing progressively from Condition 1 to Condition 4, validating ICAP's cognitive engagement hierarchy; (2) for students with similar pre-test scores, higher learning gain in immediate post-test predict higher final exam score, though no direct between-group differences emerged; (3) Our interventions are suitable and scalable solutions for diverse educational contexts, resources and learners. Together, this study makes empirical and theoretical contributions: (1) theoretically, we provided one of the first large-scale RCTs examining how cognitive engagement shapes learning in prompting literacy and clarifying the relationship between learning-oriented prompting skills and broader academic performance; (2) empirically, we offered timely design guidance for transforming GenAI classroom policies into scalable, actionable prompting literacy instruction to advance learning in the era of Generative AI.
Chronocept: Instilling a Sense of Time in Machines
May 12, 2025Human cognition is deeply intertwined with a sense of time, known as Chronoception. This sense allows us to judge how long facts remain valid and when knowledge becomes outdated. Despite progress in vision, language, and motor control, AI still struggles to reason about temporal validity. We introduce Chronocept, the first benchmark to model temporal validity as a continuous probability distribution over time. Using skew-normal curves fitted along semantically decomposed temporal axes, Chronocept captures nuanced patterns of emergence, decay, and peak relevance. It includes two datasets: Benchmark I (atomic facts) and Benchmark II (multi-sentence passages). Annotations show strong inter-annotator agreement (84% and 89%). Our baselines predict curve parameters - location, scale, and skewness - enabling interpretable, generalizable learning and outperforming classification-based approaches. Chronocept fills a foundational gap in AI's temporal reasoning, supporting applications in knowledge grounding, fact-checking, retrieval-augmented generation (RAG), and proactive agents. Code and data are publicly available.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Using Images to Find Context-Independent Word Representations in Vector Space
Nov 28, 2024



Many methods have been proposed to find vector representation for words, but most rely on capturing context from the text to find semantic relationships between these vectors. We propose a novel method of using dictionary meanings and image depictions to find word vectors independent of any context. We use auto-encoder on the word images to find meaningful representations and use them to calculate the word vectors. We finally evaluate our method on word similarity, concept categorization and outlier detection tasks. Our method performs comparably to context-based methods while taking much less training time.
Understanding Help-Seeking Behavior of Students Using LLMs vs. Web Search for Writing SQL Queries
Aug 15, 2024

Growth in the use of large language models (LLMs) in programming education is altering how students write SQL queries. Traditionally, students relied heavily on web search for coding assistance, but this has shifted with the adoption of LLMs like ChatGPT. However, the comparative process and outcomes of using web search versus LLMs for coding help remain underexplored. To address this, we conducted a randomized interview study in a database classroom to compare web search and LLMs, including a publicly available LLM (ChatGPT) and an instructor-tuned LLM, for writing SQL queries. Our findings indicate that using an instructor-tuned LLM required significantly more interactions than both ChatGPT and web search, but resulted in a similar number of edits to the final SQL query. No significant differences were found in the quality of the final SQL queries between conditions, although the LLM conditions directionally showed higher query quality. Furthermore, students using instructor-tuned LLM reported a lower mental demand. These results have implications for learning and productivity in programming education.
Using Adaptive Bandit Experiments to Increase and Investigate Engagement in Mental Health
Oct 13, 2023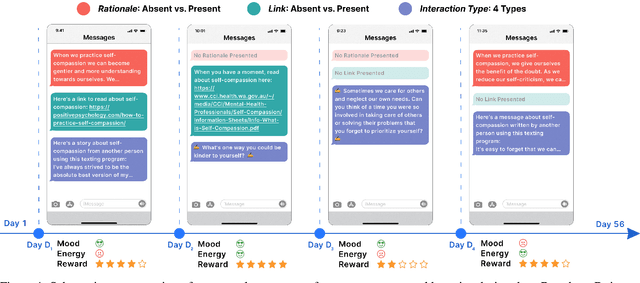

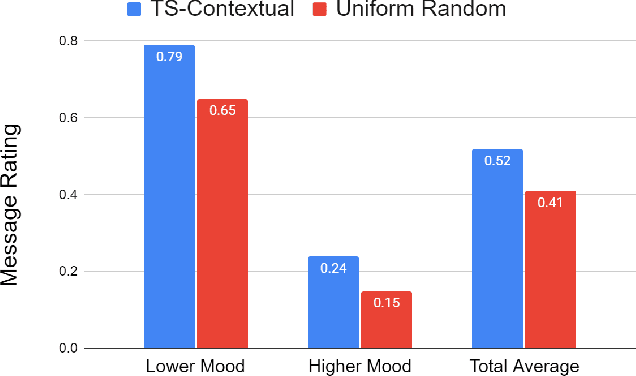

Digital mental health (DMH) interventions, such as text-message-based lessons and activities, offer immense potential for accessible mental health support. While these interventions can be effective, real-world experimental testing can further enhance their design and impact. Adaptive experimentation, utilizing algorithms like Thompson Sampling for (contextual) multi-armed bandit (MAB) problems, can lead to continuous improvement and personalization. However, it remains unclear when these algorithms can simultaneously increase user experience rewards and facilitate appropriate data collection for social-behavioral scientists to analyze with sufficient statistical confidence. Although a growing body of research addresses the practical and statistical aspects of MAB and other adaptive algorithms, further exploration is needed to assess their impact across diverse real-world contexts. This paper presents a software system developed over two years that allows text-messaging intervention components to be adapted using bandit and other algorithms while collecting data for side-by-side comparison with traditional uniform random non-adaptive experiments. We evaluate the system by deploying a text-message-based DMH intervention to 1100 users, recruited through a large mental health non-profit organization, and share the path forward for deploying this system at scale. This system not only enables applications in mental health but could also serve as a model testbed for adaptive experimentation algorithms in other domains.
Impact of Guidance and Interaction Strategies for LLM Use on Learner Performance and Perception
Oct 13, 2023Personalized chatbot-based teaching assistants can be crucial in addressing increasing classroom sizes, especially where direct teacher presence is limited. Large language models (LLMs) offer a promising avenue, with increasing research exploring their educational utility. However, the challenge lies not only in establishing the efficacy of LLMs but also in discerning the nuances of interaction between learners and these models, which impact learners' engagement and results. We conducted a formative study in an undergraduate computer science classroom (N=145) and a controlled experiment on Prolific (N=356) to explore the impact of four pedagogically informed guidance strategies and the interaction between student approaches and LLM responses. Direct LLM answers marginally improved performance, while refining student solutions fostered trust. Our findings suggest a nuanced relationship between the guidance provided and LLM's role in either answering or refining student input. Based on our findings, we provide design recommendations for optimizing learner-LLM interactions.
Is Shapley Explanation for a model unique?
Nov 23, 2021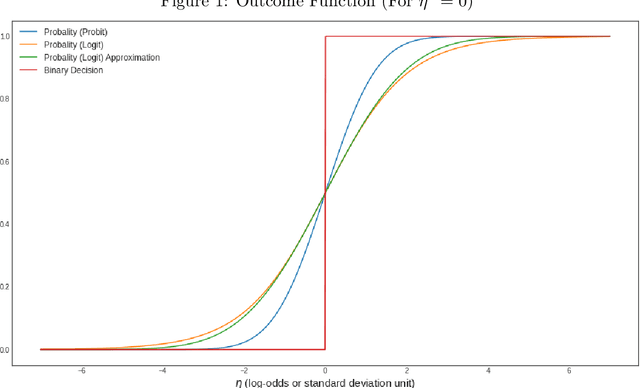
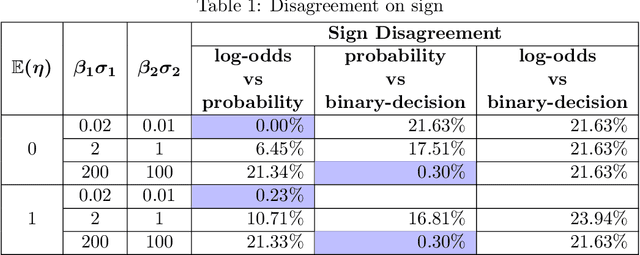
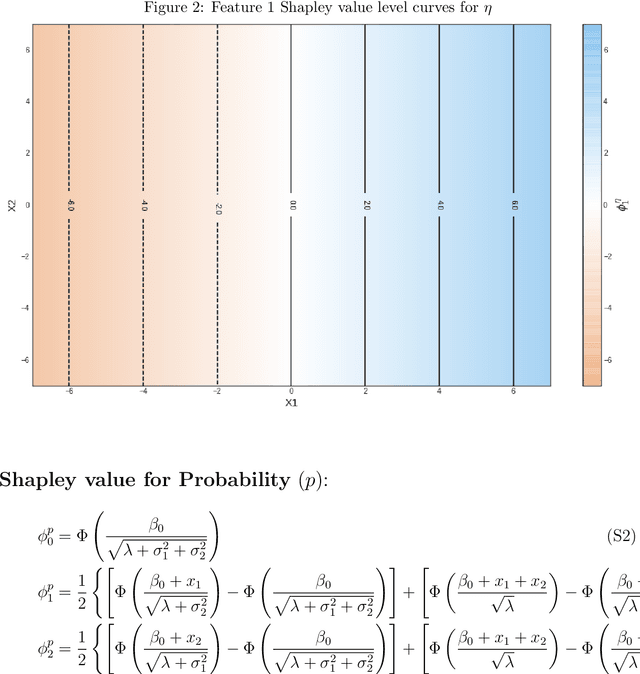
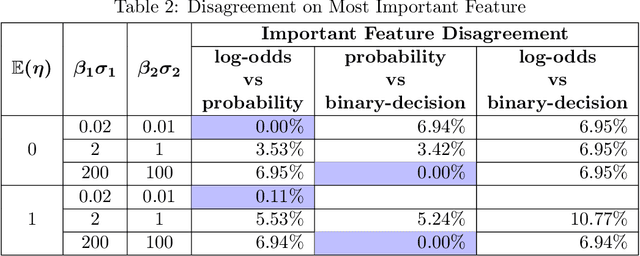
Shapley value has recently become a popular way to explain the predictions of complex and simple machine learning models. This paper is discusses the factors that influence Shapley value. In particular, we explore the relationship between the distribution of a feature and its Shapley value. We extend our analysis by discussing the difference that arises in Shapley explanation for different predicted outcomes from the same model. Our assessment is that Shapley value for particular feature not only depends on its expected mean but on other moments as well such as variance and there are disagreements for baseline prediction, disagreements for signs and most important feature for different outcomes such as probability, log odds, and binary decision generated using same linear probability model (logit/probit). These disagreements not only stay for local explainability but also affect the global feature importance. We conclude that there is no unique Shapley explanation for a given model. It varies with model outcome (Probability/Log-odds/binary decision such as accept vs reject) and hence model application.
Optimizing Oil and Gas Acquisitions Using Recommender Systems
Oct 07, 2021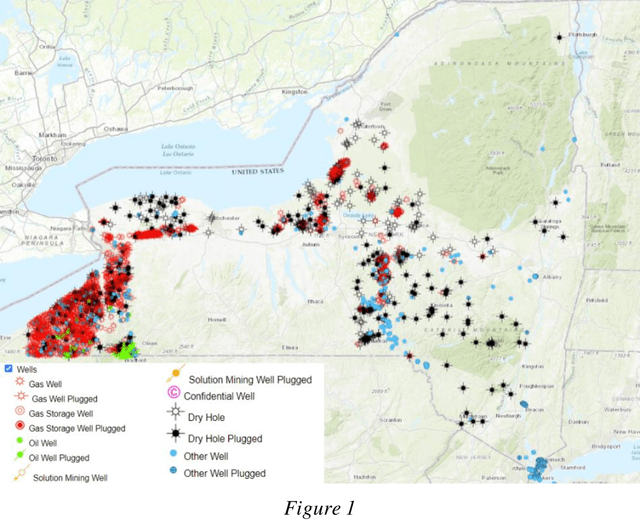
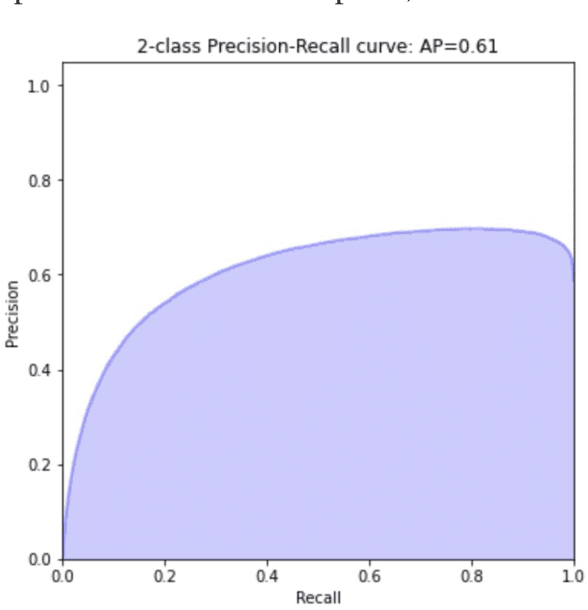
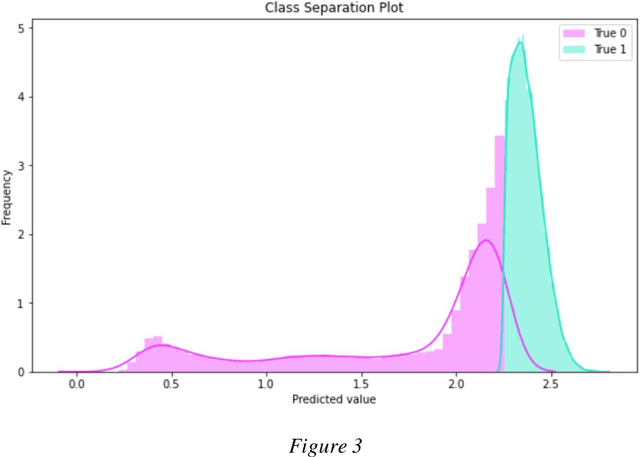
Well acquisition in the oil and gas industry can often be a hit or miss process, with a poor purchase resulting in substantial loss. Recommender systems suggest items (wells) that users (companies) are likely to buy based on past activity, and applying this system to well acquisition can increase company profits. While traditional recommender systems are impactful enough on their own, they are not optimized. This is because they ignore many of the complexities involved in human decision-making, and frequently make subpar recommendations. Using a preexisting Python implementation of a Factorization Machine results in more accurate recommendations based on a user-level ranking system. We train a Factorization Machine model on oil and gas well data that includes features such as elevation, total depth, and location. The model produces recommendations by using similarities between companies and wells, as well as their interactions. Our model has a hit rate of 0.680, reciprocal rank of 0.469, precision of 0.229, and recall of 0.463. These metrics imply that while our model is able to recommend the correct wells in a general sense, it does not match exact wells to companies via relevance. To improve the model's accuracy, future models should incorporate additional features such as the well's production data and ownership duration as these features will produce more accurate recommendations.