 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying, measuring, and mitigating individual unfairness for supervised learning models and application to credit risk models
Nov 11, 2022



In the past few years, Artificial Intelligence (AI) has garnered attention from various industries including financial services (FS). AI has made a positive impact in financial services by enhancing productivity and improving risk management. While AI can offer efficient solutions, it has the potential to bring unintended consequences. One such consequence is the pronounced effect of AI-related unfairness and attendant fairness-related harms. These fairness-related harms could involve differential treatment of individuals; for example, unfairly denying a loan to certain individuals or groups of individuals. In this paper, we focus on identifying and mitigating individual unfairness and leveraging some of the recently published techniques in this domain, especially as applicable to the credit adjudication use case. We also investigate the extent to which techniques for achieving individual fairness are effective at achieving group fairness. Our main contribution in this work is functionalizing a two-step training process which involves learning a fair similarity metric from a group sense using a small portion of the raw data and training an individually "fair" classifier using the rest of the data where the sensitive features are excluded. The key characteristic of this two-step technique is related to its flexibility, i.e., the fair metric obtained in the first step can be used with any other individual fairness algorithms in the second step. Furthermore, we developed a second metric (distinct from the fair similarity metric) to determine how fairly a model is treating similar individuals. We use this metric to compare a "fair" model against its baseline model in terms of their individual fairness value. Finally, some experimental results corresponding to the individual unfairness mitigation techniques are presented.
Is Shapley Explanation for a model unique?
Nov 23, 2021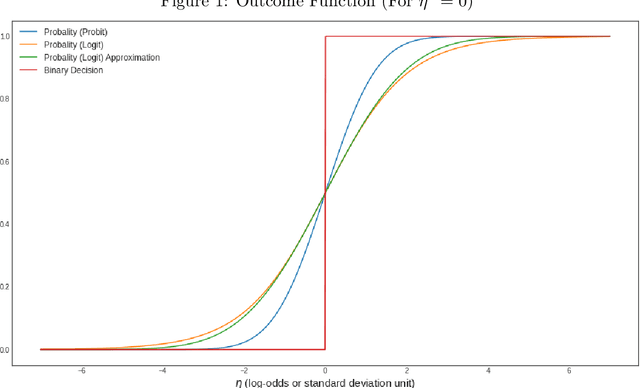
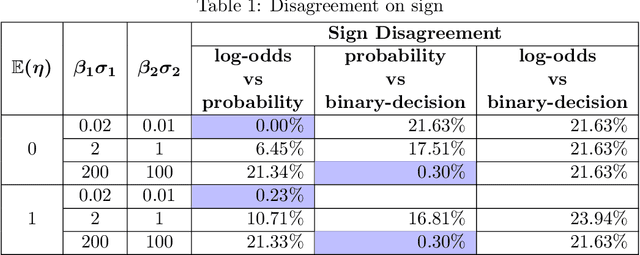
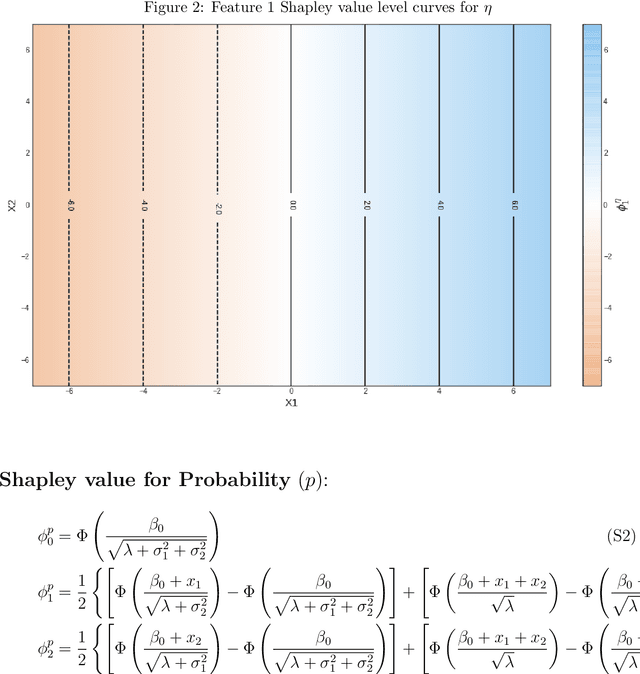
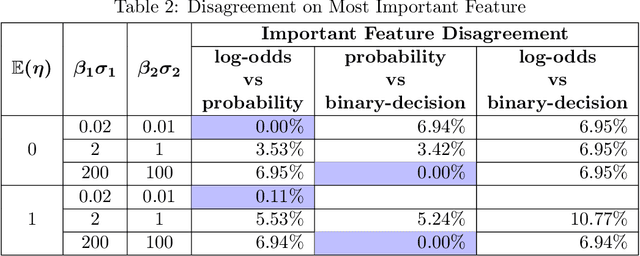
Shapley value has recently become a popular way to explain the predictions of complex and simple machine learning models. This paper is discusses the factors that influence Shapley value. In particular, we explore the relationship between the distribution of a feature and its Shapley value. We extend our analysis by discussing the difference that arises in Shapley explanation for different predicted outcomes from the same model. Our assessment is that Shapley value for particular feature not only depends on its expected mean but on other moments as well such as variance and there are disagreements for baseline prediction, disagreements for signs and most important feature for different outcomes such as probability, log odds, and binary decision generated using same linear probability model (logit/probit). These disagreements not only stay for local explainability but also affect the global feature importance. We conclude that there is no unique Shapley explanation for a given model. It varies with model outcome (Probability/Log-odds/binary decision such as accept vs reject) and hence model application.