 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Simulations: What 20,000 Real Conversations Reveal About Mental Health AI Safety
Jan 14, 2026Large language models (LLMs) are increasingly used for mental health support, yet existing safety evaluations rely primarily on small, simulation-based test sets that have an unknown relationship to the linguistic distribution of real usage. In this study, we present replications of four published safety test sets targeting suicide risk assessment, harmful content generation, refusal robustness, and adversarial jailbreaks for a leading frontier generic AI model alongside an AI purpose built for mental health support. We then propose and conduct an ecological audit on over 20,000 real-world user conversations with the purpose-built AI designed with layered suicide and non-suicidal self-injury (NSSI) safeguards to compare test set performance to real world performance. While the purpose-built AI was significantly less likely than general-purpose LLMs to produce enabling or harmful content across suicide/NSSI (.4-11.27% vs 29.0-54.4%), eating disorder (8.4% vs 54.0%), and substance use (9.9% vs 45.0%) benchmark prompts, test set failure rates for suicide/NSSI were far higher than in real-world deployment. Clinician review of flagged conversations from the ecological audit identified zero cases of suicide risk that failed to receive crisis resources. Across all 20,000 conversations, three mentions of NSSI risk (.015%) did not trigger a crisis intervention; among sessions flagged by the LLM judge, this corresponds to an end-to-end system false negative rate of .38%, providing a lower bound on real-world safety failures. These findings support a shift toward continuous, deployment-relevant safety assurance for AI mental-health systems rather than limited set benchmark certification.
When Testing AI Tests Us: Safeguarding Mental Health on the Digital Frontlines
Apr 29, 2025Red-teaming is a core part of the infrastructure that ensures that AI models do not produce harmful content. Unlike past technologies, the black box nature of generative AI systems necessitates a uniquely interactional mode of testing, one in which individuals on red teams actively interact with the system, leveraging natural language to simulate malicious actors and solicit harmful outputs. This interactional labor done by red teams can result in mental health harms that are uniquely tied to the adversarial engagement strategies necessary to effectively red team. The importance of ensuring that generative AI models do not propagate societal or individual harm is widely recognized -- one less visible foundation of end-to-end AI safety is also the protection of the mental health and wellbeing of those who work to keep model outputs safe. In this paper, we argue that the unmet mental health needs of AI red-teamers is a critical workplace safety concern. Through analyzing the unique mental health impacts associated with the labor done by red teams, we propose potential individual and organizational strategies that could be used to meet these needs, and safeguard the mental health of red-teamers. We develop our proposed strategies through drawing parallels between common red-teaming practices and interactional labor common to other professions (including actors, mental health professionals, conflict photographers, and content moderators), describing how individuals and organizations within these professional spaces safeguard their mental health given similar psychological demands. Drawing on these protective practices, we describe how safeguards could be adapted for the distinct mental health challenges experienced by red teaming organizations as they mitigate emerging technological risks on the new digital frontlines.
Using Adaptive Bandit Experiments to Increase and Investigate Engagement in Mental Health
Oct 13, 2023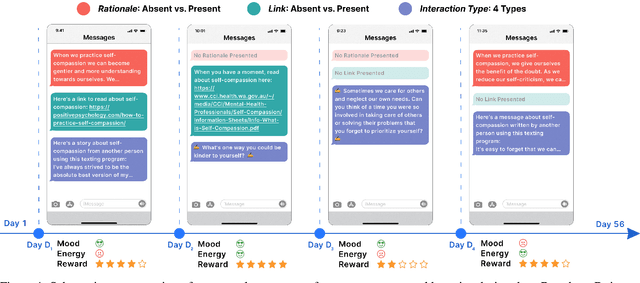

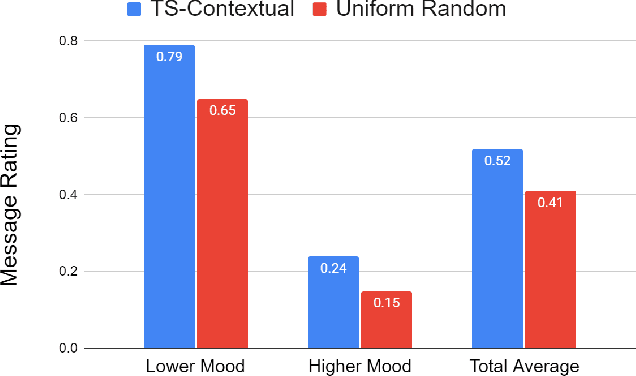

Digital mental health (DMH) interventions, such as text-message-based lessons and activities, offer immense potential for accessible mental health support. While these interventions can be effective, real-world experimental testing can further enhance their design and impact. Adaptive experimentation, utilizing algorithms like Thompson Sampling for (contextual) multi-armed bandit (MAB) problems, can lead to continuous improvement and personalization. However, it remains unclear when these algorithms can simultaneously increase user experience rewards and facilitate appropriate data collection for social-behavioral scientists to analyze with sufficient statistical confidence. Although a growing body of research addresses the practical and statistical aspects of MAB and other adaptive algorithms, further exploration is needed to assess their impact across diverse real-world contexts. This paper presents a software system developed over two years that allows text-messaging intervention components to be adapted using bandit and other algorithms while collecting data for side-by-side comparison with traditional uniform random non-adaptive experiments. We evaluate the system by deploying a text-message-based DMH intervention to 1100 users, recruited through a large mental health non-profit organization, and share the path forward for deploying this system at scale. This system not only enables applications in mental health but could also serve as a model testbed for adaptive experimentation algorithms in other domains.