 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscourse Diversity in Multi-Turn Empathic Dialogue
Apr 13, 2026Large language models (LLMs) produce responses rated as highly empathic in single-turn settings (Ayers et al., 2023; Lee et al., 2024), yet they are also known to be formulaic generators that reuse the same lexical patterns, syntactic templates, and discourse structures across tasks (Jiang et al., 2025; Shaib et al., 2024; Namuduri et al., 2025). Less attention has been paid to whether this formulaicity extends to the level of discourse moves, i.e., what a response does for the person it is addressing. This question is especially consequential for empathic dialogue, where effective support demands not just a kind response at one moment but varied strategies as a conversation unfolds (Stiles et al., 1998). Indeed, prior work shows that LLMs reuse the same tactic sequences more than human supporters in single-turn settings (Gueorguieva et al., 2026). We extend this analysis to multi-turn conversations and find that the rigidity compounds: once a tactic appears in a supporter turn, LLMs reuse it in the next at nearly double the rate of humans (0.50-0.56 vs. 0.27). This pattern holds across LLMs serving as supporters in real emotional support conversations, and is invisible to standard similarity metrics. To address this gap, we introduce MINT (Multi-turn Inter-tactic Novelty Training), the first reinforcement learning framework to optimize discourse move diversity across multi-turn empathic dialogue. The best MINT variant combines an empathy quality reward with a cross-turn tactic novelty signal, improving aggregate empathy by 25.3% over vanilla across 1.7B and 4B models while reducing cross-turn discourse move repetition by 26.3% on the 4B model, surpassing all baselines including quality-only and token-level diversity methods on both measures. These results suggest that what current models lack is not empathy itself, but the ability to vary their discourse moves across a conversation.
AI generates well-liked but templatic empathic responses
Apr 09, 2026Recent research shows that greater numbers of people are turning to Large Language Models (LLMs) for emotional support, and that people rate LLM responses as more empathic than human-written responses. We suggest a reason for this success: LLMs have learned and consistently deploy a well-liked template for expressing empathy. We develop a taxonomy of 10 empathic language "tactics" that include validating someone's feelings and paraphrasing, and apply this taxonomy to characterize the language that people and LLMs produce when writing empathic responses. Across a set of 2 studies comparing a total of n = 3,265 AI-generated (by six models) and n = 1,290 human-written responses, we find that LLM responses are highly formulaic at a discourse functional level. We discovered a template -- a structured sequence of tactics -- that matches between 83--90% of LLM responses (and 60--83\% in a held out sample), and when those are matched, covers 81--92% of the response. By contrast, human-written responses are more diverse. We end with a discussion of implications for the future of AI-generated empathy.
Seeking Late Night Life Lines: Experiences of Conversational AI Use in Mental Health Crisis
Dec 29, 2025Online, people often recount their experiences turning to conversational AI agents (e.g., ChatGPT, Claude, Copilot) for mental health support -- going so far as to replace their therapists. These anecdotes suggest that AI agents have great potential to offer accessible mental health support. However, it's unclear how to meet this potential in extreme mental health crisis use cases. In this work, we explore the first-person experience of turning to a conversational AI agent in a mental health crisis. From a testimonial survey (n = 53) of lived experiences, we find that people use AI agents to fill the in-between spaces of human support; they turn to AI due to lack of access to mental health professionals or fears of burdening others. At the same time, our interviews with mental health experts (n = 16) suggest that human-human connection is an essential positive action when managing a mental health crisis. Using the stages of change model, our results suggest that a responsible AI crisis intervention is one that increases the user's preparedness to take a positive action while de-escalating any intended negative action. We discuss the implications of designing conversational AI agents as bridges towards human-human connection rather than ends in themselves.
When Testing AI Tests Us: Safeguarding Mental Health on the Digital Frontlines
Apr 29, 2025Red-teaming is a core part of the infrastructure that ensures that AI models do not produce harmful content. Unlike past technologies, the black box nature of generative AI systems necessitates a uniquely interactional mode of testing, one in which individuals on red teams actively interact with the system, leveraging natural language to simulate malicious actors and solicit harmful outputs. This interactional labor done by red teams can result in mental health harms that are uniquely tied to the adversarial engagement strategies necessary to effectively red team. The importance of ensuring that generative AI models do not propagate societal or individual harm is widely recognized -- one less visible foundation of end-to-end AI safety is also the protection of the mental health and wellbeing of those who work to keep model outputs safe. In this paper, we argue that the unmet mental health needs of AI red-teamers is a critical workplace safety concern. Through analyzing the unique mental health impacts associated with the labor done by red teams, we propose potential individual and organizational strategies that could be used to meet these needs, and safeguard the mental health of red-teamers. We develop our proposed strategies through drawing parallels between common red-teaming practices and interactional labor common to other professions (including actors, mental health professionals, conflict photographers, and content moderators), describing how individuals and organizations within these professional spaces safeguard their mental health given similar psychological demands. Drawing on these protective practices, we describe how safeguards could be adapted for the distinct mental health challenges experienced by red teaming organizations as they mitigate emerging technological risks on the new digital frontlines.
Longitudinal Study on Social and Emotional Use of AI Conversational Agent
Apr 19, 2025Development in digital technologies has continuously reshaped how individuals seek and receive social and emotional support. While online platforms and communities have long served this need, the increased integration of general-purpose conversational AI into daily lives has introduced new dynamics in how support is provided and experienced. Existing research has highlighted both benefits (e.g., wider access to well-being resources) and potential risks (e.g., over-reliance) of using AI for support seeking. In this five-week, exploratory study, we recruited 149 participants divided into two usage groups: a baseline usage group (BU, n=60) that used the internet and AI as usual, and an active usage group (AU, n=89) encouraged to use one of four commercially available AI tools (Microsoft Copilot, Google Gemini, PI AI, ChatGPT) for social and emotional interactions. Our analysis revealed significant increases in perceived attachment towards AI (32.99 percentage points), perceived AI empathy (25.8 p.p.), and motivation to use AI for entertainment (22.90 p.p.) among the AU group. We also observed that individual differences (e.g., gender identity, prior AI usage) influenced perceptions of AI empathy and attachment. Lastly, the AU group expressed higher comfort in seeking personal help, managing stress, obtaining social support, and talking about health with AI, indicating potential for broader emotional support while highlighting the need for safeguards against problematic usage. Overall, our exploratory findings underscore the importance of developing consumer-facing AI tools that support emotional well-being responsibly, while empowering users to understand the limitations of these tools.
Uncovering inequalities in new knowledge learning by large language models across different languages
Mar 06, 2025As large language models (LLMs) gradually become integral tools for problem solving in daily life worldwide, understanding linguistic inequality is becoming increasingly important. Existing research has primarily focused on static analyses that assess the disparities in the existing knowledge and capabilities of LLMs across languages. However, LLMs are continuously evolving, acquiring new knowledge to generate up-to-date, domain-specific responses. Investigating linguistic inequalities within this dynamic process is, therefore, also essential. In this paper, we explore inequalities in new knowledge learning by LLMs across different languages and four key dimensions: effectiveness, transferability, prioritization, and robustness. Through extensive experiments under two settings (in-context learning and fine-tuning) using both proprietary and open-source models, we demonstrate that low-resource languages consistently face disadvantages across all four dimensions. By shedding light on these disparities, we aim to raise awareness of linguistic inequalities in LLMs' new knowledge learning, fostering the development of more inclusive and equitable future LLMs.
AI Red-Teaming is a Sociotechnical System. Now What?
Dec 12, 2024As generative AI technologies find more and more real-world applications, the importance of testing their performance and safety seems paramount. ``Red-teaming'' has quickly become the primary approach to test AI models--prioritized by AI companies, and enshrined in AI policy and regulation. Members of red teams act as adversaries, probing AI systems to test their safety mechanisms and uncover vulnerabilities. Yet we know too little about this work and its implications. This essay calls for collaboration between computer scientists and social scientists to study the sociotechnical systems surrounding AI technologies, including the work of red-teaming, to avoid repeating the mistakes of the recent past. We highlight the importance of understanding the values and assumptions behind red-teaming, the labor involved, and the psychological impacts on red-teamers.
From Lived Experience to Insight: Unpacking the Psychological Risks of Using AI Conversational Agents
Dec 12, 2024Recent gain in popularity of AI conversational agents has led to their increased use for improving productivity and supporting well-being. While previous research has aimed to understand the risks associated with interactions with AI conversational agents, these studies often fall short in capturing the lived experiences. Additionally, psychological risks have often been presented as a sub-category within broader AI-related risks in past taxonomy works, leading to under-representation of the impact of psychological risks of AI use. To address these challenges, our work presents a novel risk taxonomy focusing on psychological risks of using AI gathered through lived experience of individuals. We employed a mixed-method approach, involving a comprehensive survey with 283 individuals with lived mental health experience and workshops involving lived experience experts to develop a psychological risk taxonomy. Our taxonomy features 19 AI behaviors, 21 negative psychological impacts, and 15 contexts related to individuals. Additionally, we propose a novel multi-path vignette based framework for understanding the complex interplay between AI behaviors, psychological impacts, and individual user contexts. Finally, based on the feedback obtained from the workshop sessions, we present design recommendations for developing safer and more robust AI agents. Our work offers an in-depth understanding of the psychological risks associated with AI conversational agents and provides actionable recommendations for policymakers, researchers, and developers.
The Human Factor in AI Red Teaming: Perspectives from Social and Collaborative Computing
Jul 10, 2024Rapid progress in general-purpose AI has sparked significant interest in "red teaming," a practice of adversarial testing originating in military and cybersecurity applications. AI red teaming raises many questions about the human factor, such as how red teamers are selected, biases and blindspots in how tests are conducted, and harmful content's psychological effects on red teamers. A growing body of HCI and CSCW literature examines related practices-including data labeling, content moderation, and algorithmic auditing. However, few, if any, have investigated red teaming itself. This workshop seeks to consider the conceptual and empirical challenges associated with this practice, often rendered opaque by non-disclosure agreements. Future studies may explore topics ranging from fairness to mental health and other areas of potential harm. We aim to facilitate a community of researchers and practitioners who can begin to meet these challenges with creativity, innovation, and thoughtful reflection.
Large Language Models are Capable of Offering Cognitive Reappraisal, if Guided
Apr 01, 2024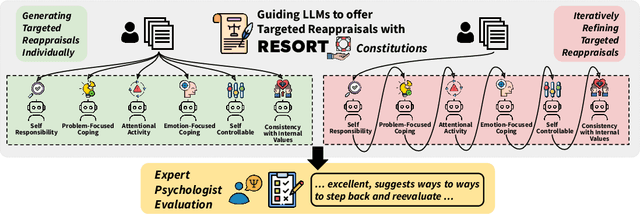
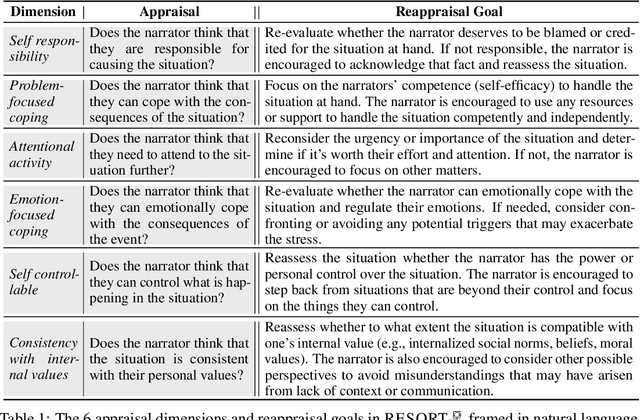

Large language models (LLMs) have offered new opportunities for emotional support, and recent work has shown that they can produce empathic responses to people in distress. However, long-term mental well-being requires emotional self-regulation, where a one-time empathic response falls short. This work takes a first step by engaging with cognitive reappraisals, a strategy from psychology practitioners that uses language to targetedly change negative appraisals that an individual makes of the situation; such appraisals is known to sit at the root of human emotional experience. We hypothesize that psychologically grounded principles could enable such advanced psychology capabilities in LLMs, and design RESORT which consists of a series of reappraisal constitutions across multiple dimensions that can be used as LLM instructions. We conduct a first-of-its-kind expert evaluation (by clinical psychologists with M.S. or Ph.D. degrees) of an LLM's zero-shot ability to generate cognitive reappraisal responses to medium-length social media messages asking for support. This fine-grained evaluation showed that even LLMs at the 7B scale guided by RESORT are capable of generating empathic responses that can help users reappraise their situations.