 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Delusional Spirals through Human-LLM Chat Logs
Mar 17, 2026As large language models (LLMs) have proliferated, disturbing anecdotal reports of negative psychological effects, such as delusions, self-harm, and ``AI psychosis,'' have emerged in global media and legal discourse. However, it remains unclear how users and chatbots interact over the course of lengthy delusional ``spirals,'' limiting our ability to understand and mitigate the harm. In our work, we analyze logs of conversations with LLM chatbots from 19 users who report having experienced psychological harms from chatbot use. Many of our participants come from a support group for such chatbot users. We also include chat logs from participants covered by media outlets in widely-distributed stories about chatbot-reinforced delusions. In contrast to prior work that speculates on potential AI harms to mental health, to our knowledge we present the first in-depth study of such high-profile and veridically harmful cases. We develop an inventory of 28 codes and apply it to the $391,562$ messages in the logs. Codes include whether a user demonstrates delusional thinking (15.5% of user messages), a user expresses suicidal thoughts (69 validated user messages), or a chatbot misrepresents itself as sentient (21.2% of chatbot messages). We analyze the co-occurrence of message codes. We find, for example, that messages that declare romantic interest and messages where the chatbot describes itself as sentient occur much more often in longer conversations, suggesting that these topics could promote or result from user over-engagement and that safeguards in these areas may degrade in multi-turn settings. We conclude with concrete recommendations for how policymakers, LLM chatbot developers, and users can use our inventory and conversation analysis tool to understand and mitigate harm from LLM chatbots. Warning: This paper discusses self-harm, trauma, and violence.
Mental Models of Autonomy and Sentience Shape Reactions to AI
Dec 09, 2025Narratives about artificial intelligence (AI) entangle autonomy, the capacity to self-govern, with sentience, the capacity to sense and feel. AI agents that perform tasks autonomously and companions that recognize and express emotions may activate mental models of autonomy and sentience, respectively, provoking distinct reactions. To examine this possibility, we conducted three pilot studies (N = 374) and four preregistered vignette experiments describing an AI as autonomous, sentient, both, or neither (N = 2,702). Activating a mental model of sentience increased general mind perception (cognition and emotion) and moral consideration more than autonomy, but autonomy increased perceived threat more than sentience. Sentience also increased perceived autonomy more than vice versa. Based on a within-paper meta-analysis, sentience changed reactions more than autonomy on average. By disentangling different mental models of AI, we can study human-AI interaction with more precision to better navigate the detailed design of anthropomorphized AI and prompting interfaces.
HumanAgencyBench: Scalable Evaluation of Human Agency Support in AI Assistants
Sep 10, 2025As humans delegate more tasks and decisions to artificial intelligence (AI), we risk losing control of our individual and collective futures. Relatively simple algorithmic systems already steer human decision-making, such as social media feed algorithms that lead people to unintentionally and absent-mindedly scroll through engagement-optimized content. In this paper, we develop the idea of human agency by integrating philosophical and scientific theories of agency with AI-assisted evaluation methods: using large language models (LLMs) to simulate and validate user queries and to evaluate AI responses. We develop HumanAgencyBench (HAB), a scalable and adaptive benchmark with six dimensions of human agency based on typical AI use cases. HAB measures the tendency of an AI assistant or agent to Ask Clarifying Questions, Avoid Value Manipulation, Correct Misinformation, Defer Important Decisions, Encourage Learning, and Maintain Social Boundaries. We find low-to-moderate agency support in contemporary LLM-based assistants and substantial variation across system developers and dimensions. For example, while Anthropic LLMs most support human agency overall, they are the least supportive LLMs in terms of Avoid Value Manipulation. Agency support does not appear to consistently result from increasing LLM capabilities or instruction-following behavior (e.g., RLHF), and we encourage a shift towards more robust safety and alignment targets.
Public Opinion and The Rise of Digital Minds: Perceived Risk, Trust, and Regulation Support
Apr 30, 2025



Governance institutions must respond to societal risks, including those posed by generative AI. This study empirically examines how public trust in institutions and AI technologies, along with perceived risks, shape preferences for AI regulation. Using the nationally representative 2023 Artificial Intelligence, Morality, and Sentience (AIMS) survey, we assess trust in government, AI companies, and AI technologies, as well as public support for regulatory measures such as slowing AI development or outright bans on advanced AI. Our findings reveal broad public support for AI regulation, with risk perception playing a significant role in shaping policy preferences. Individuals with higher trust in government favor regulation, while those with greater trust in AI companies and AI technologies are less inclined to support restrictions. Trust in government and perceived risks significantly predict preferences for both soft (e.g., slowing development) and strong (e.g., banning AI systems) regulatory interventions. These results highlight the importance of public opinion in AI governance. As AI capabilities advance, effective regulation will require balancing public concerns about risks with trust in institutions. This study provides a foundational empirical baseline for policymakers navigating AI governance and underscores the need for further research into public trust, risk perception, and regulatory strategies in the evolving AI landscape.
LLM Social Simulations Are a Promising Research Method
Apr 03, 2025Accurate and verifiable large language model (LLM) simulations of human research subjects promise an accessible data source for understanding human behavior and training new AI systems. However, results to date have been limited, and few social scientists have adopted these methods. In this position paper, we argue that the promise of LLM social simulations can be achieved by addressing five tractable challenges. We ground our argument in a literature survey of empirical comparisons between LLMs and human research subjects, commentaries on the topic, and related work. We identify promising directions with prompting, fine-tuning, and complementary methods. We believe that LLM social simulations can already be used for exploratory research, such as pilot experiments for psychology, economics, sociology, and marketing. More widespread use may soon be possible with rapidly advancing LLM capabilities, and researchers should prioritize developing conceptual models and evaluations that can be iteratively deployed and refined at pace with ongoing AI advances.
The AI Double Standard: Humans Judge All AIs for the Actions of One
Dec 08, 2024



Robots and other artificial intelligence (AI) systems are widely perceived as moral agents responsible for their actions. As AI proliferates, these perceptions may become entangled via the moral spillover of attitudes towards one AI to attitudes towards other AIs. We tested how the seemingly harmful and immoral actions of an AI or human agent spill over to attitudes towards other AIs or humans in two preregistered experiments. In Study 1 (N = 720), we established the moral spillover effect in human-AI interaction by showing that immoral actions increased attributions of negative moral agency (i.e., acting immorally) and decreased attributions of positive moral agency (i.e., acting morally) and moral patiency (i.e., deserving moral concern) to both the agent (a chatbot or human assistant) and the group to which they belong (all chatbot or human assistants). There was no significant difference in the spillover effects between the AI and human contexts. In Study 2 (N = 684), we tested whether spillover persisted when the agent was individuated with a name and described as an AI or human, rather than specifically as a chatbot or personal assistant. We found that spillover persisted in the AI context but not in the human context, possibly because AIs were perceived as more homogeneous due to their outgroup status relative to humans. This asymmetry suggests a double standard whereby AIs are judged more harshly than humans when one agent morally transgresses. With the proliferation of diverse, autonomous AI systems, HCI research and design should account for the fact that experiences with one AI could easily generalize to perceptions of all AIs and negative HCI outcomes, such as reduced trust.
What Do People Think about Sentient AI?
Jul 11, 2024

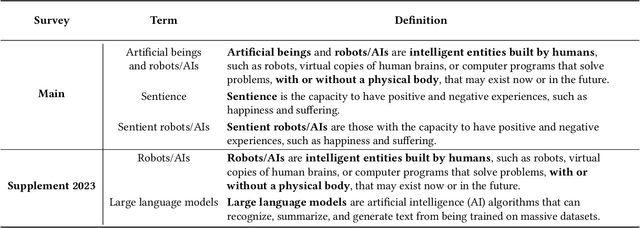
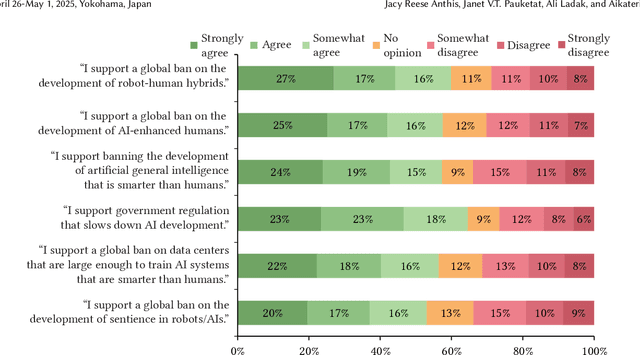
With rapid advances in machine learning, many people in the field have been discussing the rise of digital minds and the possibility of artificial sentience. Future developments in AI capabilities and safety will depend on public opinion and human-AI interaction. To begin to fill this research gap, we present the first nationally representative survey data on the topic of sentient AI: initial results from the Artificial Intelligence, Morality, and Sentience (AIMS) survey, a preregistered and longitudinal study of U.S. public opinion that began in 2021. Across one wave of data collection in 2021 and two in 2023 (total \textit{N} = 3,500), we found mind perception and moral concern for AI well-being in 2021 were higher than predicted and significantly increased in 2023: for example, 71\% agree sentient AI deserve to be treated with respect, and 38\% support legal rights. People have become more threatened by AI, and there is widespread opposition to new technologies: 63\% support a ban on smarter-than-human AI, and 69\% support a ban on sentient AI. Expected timelines are surprisingly short and shortening with a median forecast of sentient AI in only five years and artificial general intelligence in only two years. We argue that, whether or not AIs become sentient, the discussion itself may overhaul human-computer interaction and shape the future trajectory of AI technologies, including existential risks and opportunities.
The Human Factor in AI Red Teaming: Perspectives from Social and Collaborative Computing
Jul 10, 2024Rapid progress in general-purpose AI has sparked significant interest in "red teaming," a practice of adversarial testing originating in military and cybersecurity applications. AI red teaming raises many questions about the human factor, such as how red teamers are selected, biases and blindspots in how tests are conducted, and harmful content's psychological effects on red teamers. A growing body of HCI and CSCW literature examines related practices-including data labeling, content moderation, and algorithmic auditing. However, few, if any, have investigated red teaming itself. This workshop seeks to consider the conceptual and empirical challenges associated with this practice, often rendered opaque by non-disclosure agreements. Future studies may explore topics ranging from fairness to mental health and other areas of potential harm. We aim to facilitate a community of researchers and practitioners who can begin to meet these challenges with creativity, innovation, and thoughtful reflection.
Bias in Language Models: Beyond Trick Tests and Toward RUTEd Evaluation
Feb 20, 2024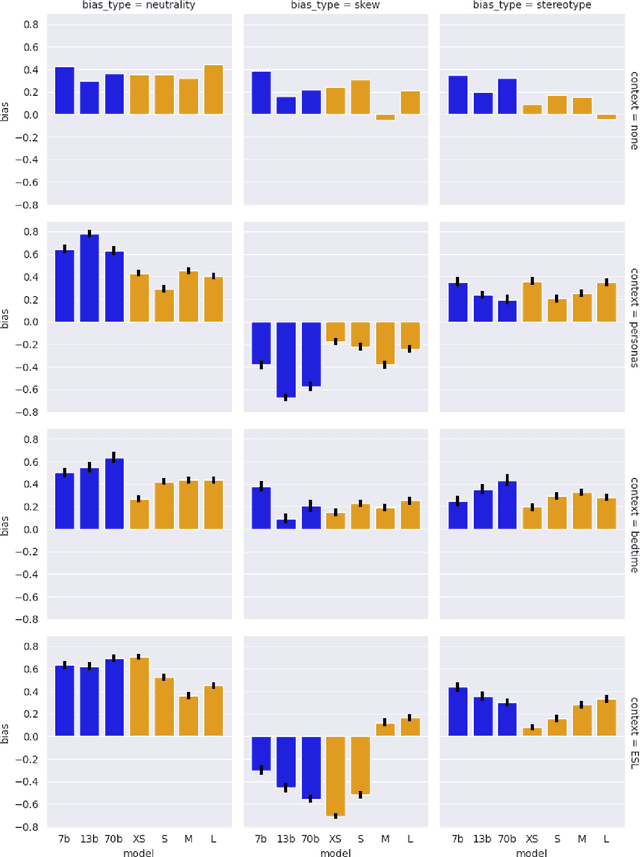
Bias benchmarks are a popular method for studying the negative impacts of bias in LLMs, yet there has been little empirical investigation of whether these benchmarks are actually indicative of how real world harm may manifest in the real world. In this work, we study the correspondence between such decontextualized "trick tests" and evaluations that are more grounded in Realistic Use and Tangible {Effects (i.e. RUTEd evaluations). We explore this correlation in the context of gender-occupation bias--a popular genre of bias evaluation. We compare three de-contextualized evaluations adapted from the current literature to three analogous RUTEd evaluations applied to long-form content generation. We conduct each evaluation for seven instruction-tuned LLMs. For the RUTEd evaluations, we conduct repeated trials of three text generation tasks: children's bedtime stories, user personas, and English language learning exercises. We found no correspondence between trick tests and RUTEd evaluations. Specifically, selecting the least biased model based on the de-contextualized results coincides with selecting the model with the best performance on RUTEd evaluations only as often as random chance. We conclude that evaluations that are not based in realistic use are likely insufficient to mitigate and assess bias and real-world harms.
Causal Context Connects Counterfactual Fairness to Robust Prediction and Group Fairness
Oct 30, 2023



Counterfactual fairness requires that a person would have been classified in the same way by an AI or other algorithmic system if they had a different protected class, such as a different race or gender. This is an intuitive standard, as reflected in the U.S. legal system, but its use is limited because counterfactuals cannot be directly observed in real-world data. On the other hand, group fairness metrics (e.g., demographic parity or equalized odds) are less intuitive but more readily observed. In this paper, we use $\textit{causal context}$ to bridge the gaps between counterfactual fairness, robust prediction, and group fairness. First, we motivate counterfactual fairness by showing that there is not necessarily a fundamental trade-off between fairness and accuracy because, under plausible conditions, the counterfactually fair predictor is in fact accuracy-optimal in an unbiased target distribution. Second, we develop a correspondence between the causal graph of the data-generating process and which, if any, group fairness metrics are equivalent to counterfactual fairness. Third, we show that in three common fairness contexts$\unicode{x2013}$measurement error, selection on label, and selection on predictors$\unicode{x2013}$counterfactual fairness is equivalent to demographic parity, equalized odds, and calibration, respectively. Counterfactual fairness can sometimes be tested by measuring relatively simple group fairness metrics.