 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApproximating Human Preferences Using a Multi-Judge Learned System
Oct 29, 2025Aligning LLM-based judges with human preferences is a significant challenge, as they are difficult to calibrate and often suffer from rubric sensitivity, bias, and instability. Overcoming this challenge advances key applications, such as creating reliable reward models for Reinforcement Learning from Human Feedback (RLHF) and building effective routing systems that select the best-suited model for a given user query. In this work, we propose a framework for modeling diverse, persona-based preferences by learning to aggregate outputs from multiple rubric-conditioned judges. We investigate the performance of this approach against naive baselines and assess its robustness through case studies on both human and LLM-judges biases. Our primary contributions include a persona-based method for synthesizing preference labels at scale and two distinct implementations of our aggregator: Generalized Additive Model (GAM) and a Multi-Layer Perceptron (MLP).
HumanAgencyBench: Scalable Evaluation of Human Agency Support in AI Assistants
Sep 10, 2025As humans delegate more tasks and decisions to artificial intelligence (AI), we risk losing control of our individual and collective futures. Relatively simple algorithmic systems already steer human decision-making, such as social media feed algorithms that lead people to unintentionally and absent-mindedly scroll through engagement-optimized content. In this paper, we develop the idea of human agency by integrating philosophical and scientific theories of agency with AI-assisted evaluation methods: using large language models (LLMs) to simulate and validate user queries and to evaluate AI responses. We develop HumanAgencyBench (HAB), a scalable and adaptive benchmark with six dimensions of human agency based on typical AI use cases. HAB measures the tendency of an AI assistant or agent to Ask Clarifying Questions, Avoid Value Manipulation, Correct Misinformation, Defer Important Decisions, Encourage Learning, and Maintain Social Boundaries. We find low-to-moderate agency support in contemporary LLM-based assistants and substantial variation across system developers and dimensions. For example, while Anthropic LLMs most support human agency overall, they are the least supportive LLMs in terms of Avoid Value Manipulation. Agency support does not appear to consistently result from increasing LLM capabilities or instruction-following behavior (e.g., RLHF), and we encourage a shift towards more robust safety and alignment targets.
MEQA: A Meta-Evaluation Framework for Question & Answer LLM Benchmarks
Apr 18, 2025



As Large Language Models (LLMs) advance, their potential for widespread societal impact grows simultaneously. Hence, rigorous LLM evaluations are both a technical necessity and social imperative. While numerous evaluation benchmarks have been developed, there remains a critical gap in meta-evaluation: effectively assessing benchmarks' quality. We propose MEQA, a framework for the meta-evaluation of question and answer (QA) benchmarks, to provide standardized assessments, quantifiable scores, and enable meaningful intra-benchmark comparisons. We demonstrate this approach on cybersecurity benchmarks, using human and LLM evaluators, highlighting the benchmarks' strengths and weaknesses. We motivate our choice of test domain by AI models' dual nature as powerful defensive tools and security threats.
Evaluating Precise Geolocation Inference Capabilities of Vision Language Models
Feb 20, 2025



The prevalence of Vision-Language Models (VLMs) raises important questions about privacy in an era where visual information is increasingly available. While foundation VLMs demonstrate broad knowledge and learned capabilities, we specifically investigate their ability to infer geographic location from previously unseen image data. This paper introduces a benchmark dataset collected from Google Street View that represents its global distribution of coverage. Foundation models are evaluated on single-image geolocation inference, with many achieving median distance errors of <300 km. We further evaluate VLM "agents" with access to supplemental tools, observing up to a 30.6% decrease in distance error. Our findings establish that modern foundation VLMs can act as powerful image geolocation tools, without being specifically trained for this task. When coupled with increasing accessibility of these models, our findings have greater implications for online privacy. We discuss these risks, as well as future work in this area.
Tailored Truths: Optimizing LLM Persuasion with Personalization and Fabricated Statistics
Jan 28, 2025


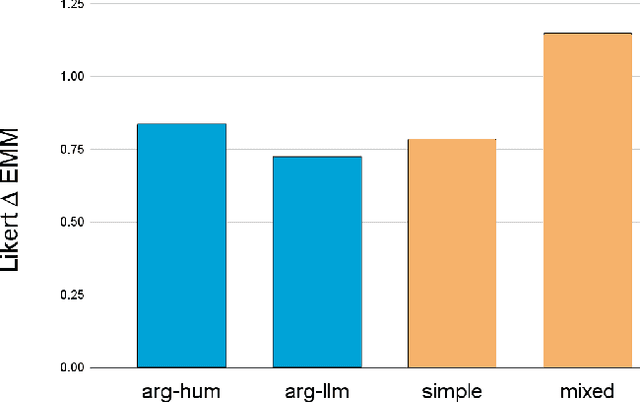
Large Language Models (LLMs) are becoming increasingly persuasive, demonstrating the ability to personalize arguments in conversation with humans by leveraging their personal data. This may have serious impacts on the scale and effectiveness of disinformation campaigns. We studied the persuasiveness of LLMs in a debate setting by having humans $(n=33)$ engage with LLM-generated arguments intended to change the human's opinion. We quantified the LLM's effect by measuring human agreement with the debate's hypothesis pre- and post-debate and analyzing both the magnitude of opinion change, as well as the likelihood of an update in the LLM's direction. We compare persuasiveness across established persuasion strategies, including personalized arguments informed by user demographics and personality, appeal to fabricated statistics, and a mixed strategy utilizing both personalized arguments and fabricated statistics. We found that static arguments generated by humans and GPT-4o-mini have comparable persuasive power. However, the LLM outperformed static human-written arguments when leveraging the mixed strategy in an interactive debate setting. This approach had a $\mathbf{51\%}$ chance of persuading participants to modify their initial position, compared to $\mathbf{32\%}$ for the static human-written arguments. Our results highlight the concerning potential for LLMs to enable inexpensive and persuasive large-scale disinformation campaigns.
Noise Injection Reveals Hidden Capabilities of Sandbagging Language Models
Dec 02, 2024



Capability evaluations play a critical role in ensuring the safe deployment of frontier AI systems, but this role may be undermined by intentional underperformance or ``sandbagging.'' We present a novel model-agnostic method for detecting sandbagging behavior using noise injection. Our approach is founded on the observation that introducing Gaussian noise into the weights of models either prompted or fine-tuned to sandbag can considerably improve their performance. We test this technique across a range of model sizes and multiple-choice question benchmarks (MMLU, AI2, WMDP). Our results demonstrate that noise injected sandbagging models show performance improvements compared to standard models. Leveraging this effect, we develop a classifier that consistently identifies sandbagging behavior. Our unsupervised technique can be immediately implemented by frontier labs or regulatory bodies with access to weights to improve the trustworthiness of capability evaluations.
Rethinking CyberSecEval: An LLM-Aided Approach to Evaluation Critique
Nov 13, 2024
A key development in the cybersecurity evaluations space is the work carried out by Meta, through their CyberSecEval approach. While this work is undoubtedly a useful contribution to a nascent field, there are notable features that limit its utility. Key drawbacks focus on the insecure code detection part of Meta's methodology. We explore these limitations, and use our exploration as a test case for LLM-assisted benchmark analysis.
Benchmark Inflation: Revealing LLM Performance Gaps Using Retro-Holdouts
Oct 11, 2024The training data for many Large Language Models (LLMs) is contaminated with test data. This means that public benchmarks used to assess LLMs are compromised, suggesting a performance gap between benchmark scores and actual capabilities. Ideally, a private holdout set could be used to accurately verify scores. Unfortunately, such datasets do not exist for most benchmarks, and post-hoc construction of sufficiently similar datasets is non-trivial. To address these issues, we introduce a systematic methodology for (i) retrospectively constructing a holdout dataset for a target dataset, (ii) demonstrating the statistical indistinguishability of this retro-holdout dataset, and (iii) comparing LLMs on the two datasets to quantify the performance gap due to the dataset's public availability. Applying these methods to TruthfulQA, we construct and release Retro-Misconceptions, on which we evaluate twenty LLMs and find that some have inflated scores by as much as 16 percentage points. Our results demonstrate that public benchmark scores do not always accurately assess model properties, and underscore the importance of improved data practices in the field.