 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Anatomy of Alignment: Decomposing Preference Optimization by Steering Sparse Features
Sep 16, 2025



Aligning large language models is critical for their usability and safety. However, the prevailing approach of Reinforcement Learning from Human Feedback (RLHF) induces diffuse, opaque parameter changes, making it difficult to discern what the model has internalized. Hence, we introduce Feature Steering with Reinforcement Learning (FSRL), a transparent alignment framework that trains a lightweight adapter to steer behavior by modulating interpretable features from a Sparse Autoencoder (SAE). First, we demonstrate that FSRL is an effective method for preference optimization and is comparable with current RLHF methods. We then perform mechanistic analysis on the trained adapter, and find that its policy systematically promotes style features over explicit alignment concepts, suggesting that the preference optimization process rewards stylistic presentation as a proxy for quality. Ultimately, we hope that FSRL provides a tool for both interpretable model control and diagnosing the internal mechanisms of alignment.
Understanding Refusal in Language Models with Sparse Autoencoders
May 29, 2025Refusal is a key safety behavior in aligned language models, yet the internal mechanisms driving refusals remain opaque. In this work, we conduct a mechanistic study of refusal in instruction-tuned LLMs using sparse autoencoders to identify latent features that causally mediate refusal behaviors. We apply our method to two open-source chat models and intervene on refusal-related features to assess their influence on generation, validating their behavioral impact across multiple harmful datasets. This enables a fine-grained inspection of how refusal manifests at the activation level and addresses key research questions such as investigating upstream-downstream latent relationship and understanding the mechanisms of adversarial jailbreaking techniques. We also establish the usefulness of refusal features in enhancing generalization for linear probes to out-of-distribution adversarial samples in classification tasks. We open source our code in https://github.com/wj210/refusal_sae.
TinySQL: A Progressive Text-to-SQL Dataset for Mechanistic Interpretability Research
Mar 17, 2025Mechanistic interpretability research faces a gap between analyzing simple circuits in toy tasks and discovering features in large models. To bridge this gap, we propose text-to-SQL generation as an ideal task to study, as it combines the formal structure of toy tasks with real-world complexity. We introduce TinySQL, a synthetic dataset progressing from basic to advanced SQL operations, and train models ranging from 33M to 1B parameters to establish a comprehensive testbed for interpretability. We apply multiple complementary interpretability techniques, including edge attribution patching and sparse autoencoders, to identify minimal circuits and components supporting SQL generation. Our analysis reveals both the potential and limitations of current interpretability methods, showing how circuits can vary even across similar queries. Lastly, we demonstrate how mechanistic interpretability can identify flawed heuristics in models and improve synthetic dataset design. Our work provides a comprehensive framework for evaluating and advancing interpretability techniques while establishing clear boundaries for their reliable application.
Benchmark Inflation: Revealing LLM Performance Gaps Using Retro-Holdouts
Oct 11, 2024The training data for many Large Language Models (LLMs) is contaminated with test data. This means that public benchmarks used to assess LLMs are compromised, suggesting a performance gap between benchmark scores and actual capabilities. Ideally, a private holdout set could be used to accurately verify scores. Unfortunately, such datasets do not exist for most benchmarks, and post-hoc construction of sufficiently similar datasets is non-trivial. To address these issues, we introduce a systematic methodology for (i) retrospectively constructing a holdout dataset for a target dataset, (ii) demonstrating the statistical indistinguishability of this retro-holdout dataset, and (iii) comparing LLMs on the two datasets to quantify the performance gap due to the dataset's public availability. Applying these methods to TruthfulQA, we construct and release Retro-Misconceptions, on which we evaluate twenty LLMs and find that some have inflated scores by as much as 16 percentage points. Our results demonstrate that public benchmark scores do not always accurately assess model properties, and underscore the importance of improved data practices in the field.
Towards Interpreting Visual Information Processing in Vision-Language Models
Oct 09, 2024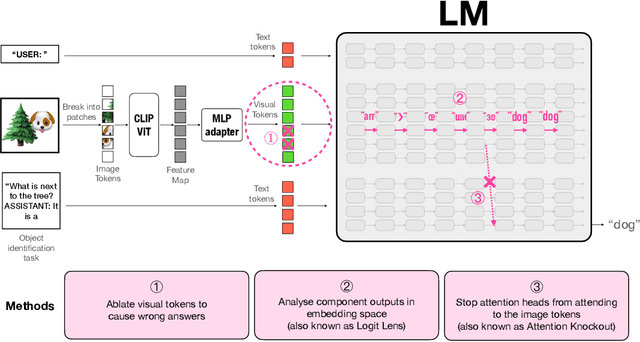



Vision-Language Models (VLMs) are powerful tools for processing and understanding text and images. We study the processing of visual tokens in the language model component of LLaVA, a prominent VLM. Our approach focuses on analyzing the localization of object information, the evolution of visual token representations across layers, and the mechanism of integrating visual information for predictions. Through ablation studies, we demonstrated that object identification accuracy drops by over 70\% when object-specific tokens are removed. We observed that visual token representations become increasingly interpretable in the vocabulary space across layers, suggesting an alignment with textual tokens corresponding to image content. Finally, we found that the model extracts object information from these refined representations at the last token position for prediction, mirroring the process in text-only language models for factual association tasks. These findings provide crucial insights into how VLMs process and integrate visual information, bridging the gap between our understanding of language and vision models, and paving the way for more interpretable and controllable multimodal systems.
Min P Sampling: Balancing Creativity and Coherence at High Temperature
Jul 01, 2024Large Language Models (LLMs) generate longform text by successively sampling the next token based on the probability distribution of the token vocabulary at each decoding step. Current popular truncation sampling methods such as top-$p$ sampling, also known as nucleus sampling, often struggle to balance coherence and creativity in generating text, particularly when using higher temperatures. To address this issue, we propose min-$p$, a dynamic truncation sampling method, that establishes a minimum base percentage threshold for tokens, which the scales according to the probability of the top candidate token. Through experiments on several benchmarks, such as GPQA, GSM8K and AlpacaEval Creative Writing, we demonstrate that min-$p$ improves the coherence and quality of generated text even at high temperatures, while also facilitating more creative and diverse outputs compared to top-$p$ and other sampling methods. As of writing, min-$p$ has been adopted by multiple open-source LLM implementations, and have been independently assessed by members of the open-source LLM community, further validating its practical utility and potential.
Interpreting Context Look-ups in Transformers: Investigating Attention-MLP Interactions
Feb 23, 2024In this paper, we investigate the interplay between attention heads and specialized "next-token" neurons in the Multilayer Perceptron that predict specific tokens. By prompting an LLM like GPT-4 to explain these model internals, we can elucidate attention mechanisms that activate certain next-token neurons. Our analysis identifies attention heads that recognize contexts relevant to predicting a particular token, activating the associated neuron through the residual connection. We focus specifically on heads in earlier layers consistently activating the same next-token neuron across similar prompts. Exploring these differential activation patterns reveals that heads that specialize for distinct linguistic contexts are tied to generating certain tokens. Overall, our method combines neural explanations and probing isolated components to illuminate how attention enables context-dependent, specialized processing in LLMs.
Increasing Trust in Language Models through the Reuse of Verified Circuits
Feb 06, 2024Language Models (LMs) are increasingly used for a wide range of prediction tasks, but their training can often neglect rare edge cases, reducing their reliability. Here, we define a stringent standard of trustworthiness whereby the task algorithm and circuit implementation must be verified, accounting for edge cases, with no known failure modes. We show that a transformer model can be trained to meet this standard if built using mathematically and logically specified frameworks. In this paper, we fully verify a model for n-digit integer addition. To exhibit the reusability of verified modules, we insert the trained integer addition model into an untrained model and train the combined model to perform both addition and subtraction. We find extensive reuse of the addition circuits for both tasks, easing verification of the more complex subtractor model. We discuss how inserting verified task modules into LMs can leverage model reuse to improve verifiability and trustworthiness of language models built using them. The reuse of verified circuits reduces the effort to verify more complex composite models which we believe to be a significant step towards safety of language models.