 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Multilingual Representations in LLMs with Cross-Layer Transcoders
Nov 13, 2025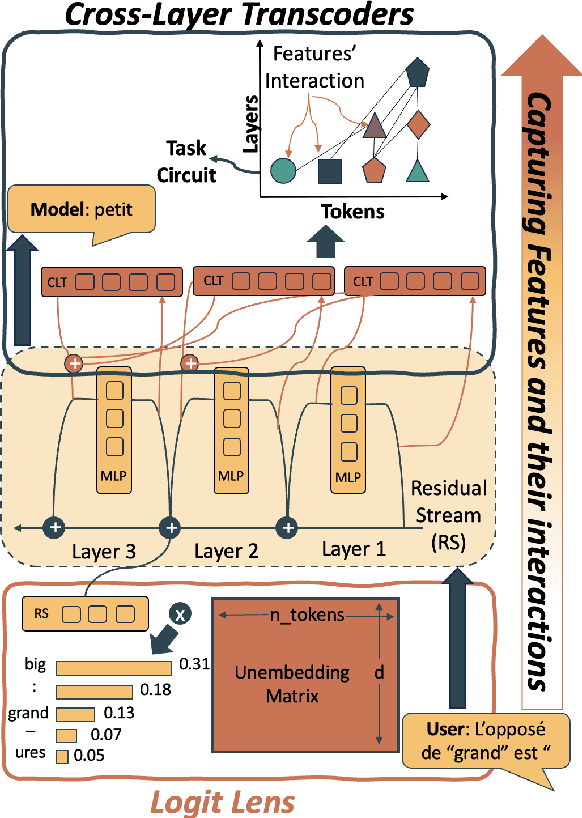
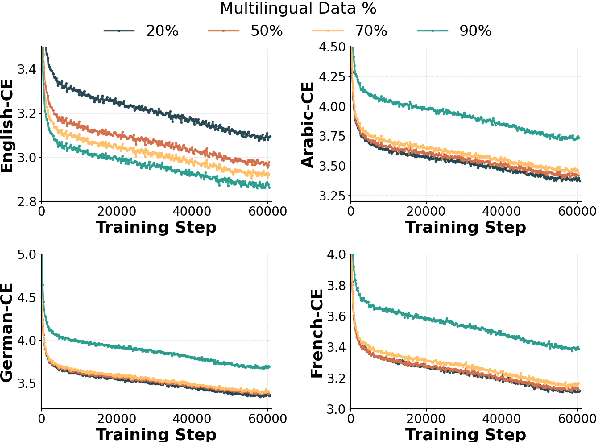
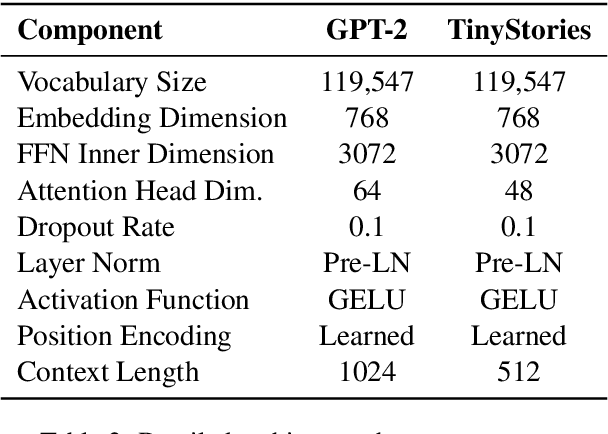
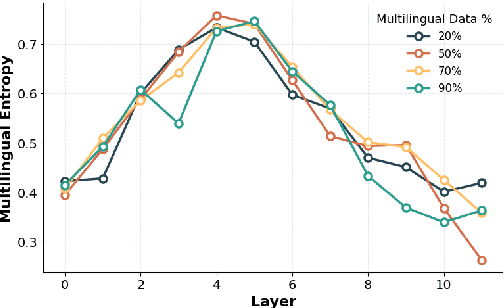
Multilingual Large Language Models (LLMs) can process many languages, yet how they internally represent this diversity remains unclear. Do they form shared multilingual representations with language-specific decoding, and if so, why does performance still favor the dominant training language? To address this, we train a series of LLMs on different mixtures of multilingual data and analyze their internal mechanisms using cross-layer transcoders (CLT) and attribution graphs. Our results provide strong evidence for pivot language representations: the model employs nearly identical representations across languages, while language-specific decoding emerges in later layers. Attribution analyses reveal that decoding relies in part on a small set of high-frequency language features in the final layers, which linearly read out language identity from the first layers in the model. By intervening on these features, we can suppress one language and substitute another in the model's outputs. Finally, we study how the dominant training language influences these mechanisms across attribution graphs and decoding pathways. We argue that understanding this pivot-language mechanism is crucial for improving multilingual alignment in LLMs.
TinySQL: A Progressive Text-to-SQL Dataset for Mechanistic Interpretability Research
Mar 17, 2025Mechanistic interpretability research faces a gap between analyzing simple circuits in toy tasks and discovering features in large models. To bridge this gap, we propose text-to-SQL generation as an ideal task to study, as it combines the formal structure of toy tasks with real-world complexity. We introduce TinySQL, a synthetic dataset progressing from basic to advanced SQL operations, and train models ranging from 33M to 1B parameters to establish a comprehensive testbed for interpretability. We apply multiple complementary interpretability techniques, including edge attribution patching and sparse autoencoders, to identify minimal circuits and components supporting SQL generation. Our analysis reveals both the potential and limitations of current interpretability methods, showing how circuits can vary even across similar queries. Lastly, we demonstrate how mechanistic interpretability can identify flawed heuristics in models and improve synthetic dataset design. Our work provides a comprehensive framework for evaluating and advancing interpretability techniques while establishing clear boundaries for their reliable application.
Activation Space Interventions Can Be Transferred Between Large Language Models
Mar 06, 2025The study of representation universality in AI models reveals growing convergence across domains, modalities, and architectures. However, the practical applications of representation universality remain largely unexplored. We bridge this gap by demonstrating that safety interventions can be transferred between models through learned mappings of their shared activation spaces. We demonstrate this approach on two well-established AI safety tasks: backdoor removal and refusal of harmful prompts, showing successful transfer of steering vectors that alter the models' outputs in a predictable way. Additionally, we propose a new task, \textit{corrupted capabilities}, where models are fine-tuned to embed knowledge tied to a backdoor. This tests their ability to separate useful skills from backdoors, reflecting real-world challenges. Extensive experiments across Llama, Qwen and Gemma model families show that our method enables using smaller models to efficiently align larger ones. Furthermore, we demonstrate that autoencoder mappings between base and fine-tuned models can serve as reliable ``lightweight safety switches", allowing dynamic toggling between model behaviors.
Adversarial Multi-Agent Evaluation of Large Language Models through Iterative Debates
Oct 07, 2024


This paper explores optimal architectures for evaluating the outputs of large language models (LLMs) using LLMs themselves. We propose a novel framework that interprets LLMs as advocates within an ensemble of interacting agents, allowing them to defend their answers and reach conclusions through a judge and jury system. This approach offers a more dynamic and comprehensive evaluation process compared to traditional human-based assessments or automated metrics. We discuss the motivation behind this framework, its key components, and comparative advantages. We also present a probabilistic model to evaluate the error reduction achieved by iterative advocate systems. Finally, we outline experiments to validate the effectiveness of multi-advocate architectures and discuss future research directions.