 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Refusal in Language Models with Sparse Autoencoders
May 29, 2025Refusal is a key safety behavior in aligned language models, yet the internal mechanisms driving refusals remain opaque. In this work, we conduct a mechanistic study of refusal in instruction-tuned LLMs using sparse autoencoders to identify latent features that causally mediate refusal behaviors. We apply our method to two open-source chat models and intervene on refusal-related features to assess their influence on generation, validating their behavioral impact across multiple harmful datasets. This enables a fine-grained inspection of how refusal manifests at the activation level and addresses key research questions such as investigating upstream-downstream latent relationship and understanding the mechanisms of adversarial jailbreaking techniques. We also establish the usefulness of refusal features in enhancing generalization for linear probes to out-of-distribution adversarial samples in classification tasks. We open source our code in https://github.com/wj210/refusal_sae.
Activation Space Interventions Can Be Transferred Between Large Language Models
Mar 06, 2025The study of representation universality in AI models reveals growing convergence across domains, modalities, and architectures. However, the practical applications of representation universality remain largely unexplored. We bridge this gap by demonstrating that safety interventions can be transferred between models through learned mappings of their shared activation spaces. We demonstrate this approach on two well-established AI safety tasks: backdoor removal and refusal of harmful prompts, showing successful transfer of steering vectors that alter the models' outputs in a predictable way. Additionally, we propose a new task, \textit{corrupted capabilities}, where models are fine-tuned to embed knowledge tied to a backdoor. This tests their ability to separate useful skills from backdoors, reflecting real-world challenges. Extensive experiments across Llama, Qwen and Gemma model families show that our method enables using smaller models to efficiently align larger ones. Furthermore, we demonstrate that autoencoder mappings between base and fine-tuned models can serve as reliable ``lightweight safety switches", allowing dynamic toggling between model behaviors.
Interpreting Bias in Large Language Models: A Feature-Based Approach
Jun 18, 2024Large Language Models (LLMs) such as Mistral and LLaMA have showcased remarkable performance across various natural language processing (NLP) tasks. Despite their success, these models inherit social biases from the diverse datasets on which they are trained. This paper investigates the propagation of biases within LLMs through a novel feature-based analytical approach. Drawing inspiration from causal mediation analysis, we hypothesize the evolution of bias-related features and validate them using interpretability techniques like activation and attribution patching. Our contributions are threefold: (1) We introduce and empirically validate a feature-based method for bias analysis in LLMs, applied to LLaMA-2-7B, LLaMA-3-8B, and Mistral-7B-v0.3 with templates from a professions dataset. (2) We extend our method to another form of gender bias, demonstrating its generalizability. (3) We differentiate the roles of MLPs and attention heads in bias propagation and implement targeted debiasing using a counterfactual dataset. Our findings reveal the complex nature of bias in LLMs and emphasize the necessity for tailored debiasing strategies, offering a deeper understanding of bias mechanisms and pathways for effective mitigation.
SGHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Singapore
May 03, 2024



To address the limitations of current hate speech detection models, we introduce \textsf{SGHateCheck}, a novel framework designed for the linguistic and cultural context of Singapore and Southeast Asia. It extends the functional testing approach of HateCheck and MHC, employing large language models for translation and paraphrasing into Singapore's main languages, and refining these with native annotators. \textsf{SGHateCheck} reveals critical flaws in state-of-the-art models, highlighting their inadequacy in sensitive content moderation. This work aims to foster the development of more effective hate speech detection tools for diverse linguistic environments, particularly for Singapore and Southeast Asia contexts.
Prompting Large Language Models for Topic Modeling
Dec 15, 2023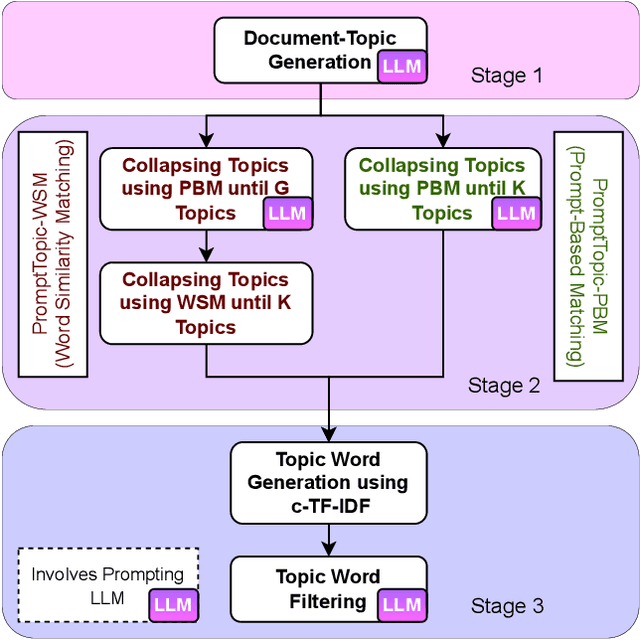

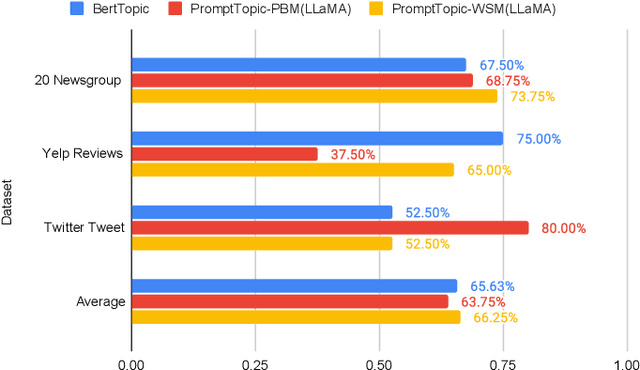

Topic modeling is a widely used technique for revealing underlying thematic structures within textual data. However, existing models have certain limitations, particularly when dealing with short text datasets that lack co-occurring words. Moreover, these models often neglect sentence-level semantics, focusing primarily on token-level semantics. In this paper, we propose PromptTopic, a novel topic modeling approach that harnesses the advanced language understanding of large language models (LLMs) to address these challenges. It involves extracting topics at the sentence level from individual documents, then aggregating and condensing these topics into a predefined quantity, ultimately providing coherent topics for texts of varying lengths. This approach eliminates the need for manual parameter tuning and improves the quality of extracted topics. We benchmark PromptTopic against the state-of-the-art baselines on three vastly diverse datasets, establishing its proficiency in discovering meaningful topics. Furthermore, qualitative analysis showcases PromptTopic's ability to uncover relevant topics in multiple datasets.
PromptMTopic: Unsupervised Multimodal Topic Modeling of Memes using Large Language Models
Dec 11, 2023



The proliferation of social media has given rise to a new form of communication: memes. Memes are multimodal and often contain a combination of text and visual elements that convey meaning, humor, and cultural significance. While meme analysis has been an active area of research, little work has been done on unsupervised multimodal topic modeling of memes, which is important for content moderation, social media analysis, and cultural studies. We propose \textsf{PromptMTopic}, a novel multimodal prompt-based model designed to learn topics from both text and visual modalities by leveraging the language modeling capabilities of large language models. Our model effectively extracts and clusters topics learned from memes, considering the semantic interaction between the text and visual modalities. We evaluate our proposed model through extensive experiments on three real-world meme datasets, which demonstrate its superiority over state-of-the-art topic modeling baselines in learning descriptive topics in memes. Additionally, our qualitative analysis shows that \textsf{PromptMTopic} can identify meaningful and culturally relevant topics from memes. Our work contributes to the understanding of the topics and themes of memes, a crucial form of communication in today's society.\\ \red{\textbf{Disclaimer: This paper contains sensitive content that may be disturbing to some readers.}}
MATK: The Meme Analytical Tool Kit
Dec 11, 2023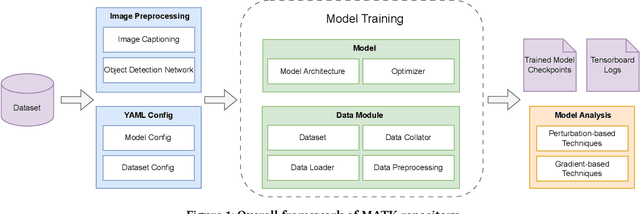
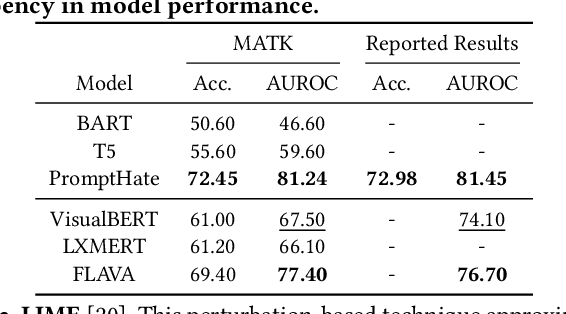
The rise of social media platforms has brought about a new digital culture called memes. Memes, which combine visuals and text, can strongly influence public opinions on social and cultural issues. As a result, people have become interested in categorizing memes, leading to the development of various datasets and multimodal models that show promising results in this field. However, there is currently a lack of a single library that allows for the reproduction, evaluation, and comparison of these models using fair benchmarks and settings. To fill this gap, we introduce the Meme Analytical Tool Kit (MATK), an open-source toolkit specifically designed to support existing memes datasets and cutting-edge multimodal models. MATK aims to assist researchers and engineers in training and reproducing these multimodal models for meme classification tasks, while also providing analysis techniques to gain insights into their strengths and weaknesses. To access MATK, please visit \url{https://github.com/Social-AI-Studio/MATK}.
TotalDefMeme: A Multi-Attribute Meme dataset on Total Defence in Singapore
May 29, 2023



Total Defence is a defence policy combining and extending the concept of military defence and civil defence. While several countries have adopted total defence as their defence policy, very few studies have investigated its effectiveness. With the rapid proliferation of social media and digitalisation, many social studies have been focused on investigating policy effectiveness through specially curated surveys and questionnaires either through digital media or traditional forms. However, such references may not truly reflect the underlying sentiments about the target policies or initiatives of interest. People are more likely to express their sentiment using communication mediums such as starting topic thread on forums or sharing memes on social media. Using Singapore as a case reference, this study aims to address this research gap by proposing TotalDefMeme, a large-scale multi-modal and multi-attribute meme dataset that captures public sentiments toward Singapore's Total Defence policy. Besides supporting social informatics and public policy analysis of the Total Defence policy, TotalDefMeme can also support many downstream multi-modal machine learning tasks, such as aspect-based stance classification and multi-modal meme clustering. We perform baseline machine learning experiments on TotalDefMeme and evaluate its technical validity, and present possible future interdisciplinary research directions and application scenarios using the dataset as a baseline.