 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompting Large Language Models for Topic Modeling
Paper and Code
Dec 15, 2023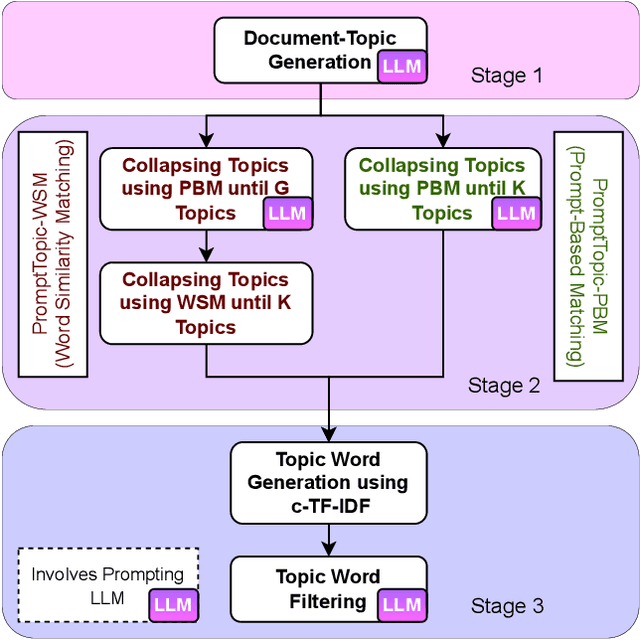

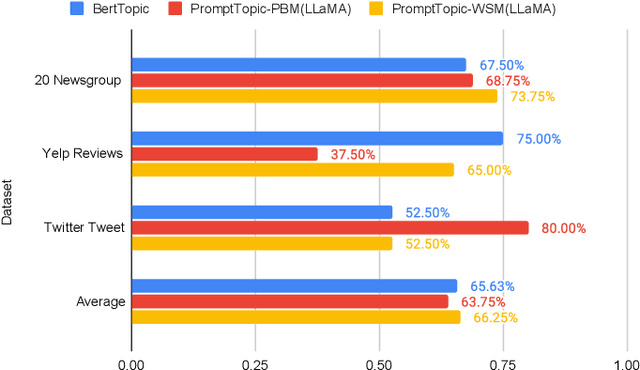

Topic modeling is a widely used technique for revealing underlying thematic structures within textual data. However, existing models have certain limitations, particularly when dealing with short text datasets that lack co-occurring words. Moreover, these models often neglect sentence-level semantics, focusing primarily on token-level semantics. In this paper, we propose PromptTopic, a novel topic modeling approach that harnesses the advanced language understanding of large language models (LLMs) to address these challenges. It involves extracting topics at the sentence level from individual documents, then aggregating and condensing these topics into a predefined quantity, ultimately providing coherent topics for texts of varying lengths. This approach eliminates the need for manual parameter tuning and improves the quality of extracted topics. We benchmark PromptTopic against the state-of-the-art baselines on three vastly diverse datasets, establishing its proficiency in discovering meaningful topics. Furthermore, qualitative analysis showcases PromptTopic's ability to uncover relevant topics in multiple datasets.