 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePSI-Bench: Towards Clinically Grounded and Interpretable Evaluation of Depression Patient Simulators
Apr 28, 2026Patient simulators are gaining traction in mental health training by providing scalable exposure to complex and sensitive patient interactions. Simulating depressed patients is particularly challenging, as safety constraints and high patient variability complicate simulations and underscore the need for simulators that capture diverse and realistic patient behaviors. However, existing evaluations heavily rely on LLM-judges with poorly specified prompts and do not assess behavioral diversity. We introduce PSI-Bench, an automatic evaluation framework that provides interpretable, clinically grounded diagnostics of depression patient simulator behavior across turn-, dialogue-, and population-level dimensions. Using PSI-Bench, we benchmark seven LLMs across two simulator frameworks and find that simulators produce overly long, lexically diverse responses, show reduced variability, resolve emotions too quickly, and follow a uniform negative-to-positive trajectory. We also show that the simulation framework has a larger impact on fidelity than the model scale. Results from a human study demonstrate that our benchmark is strongly aligned with expert judgments. Our work reveals key limitations of current depression patient simulators and provides an interpretable, extensible benchmark to guide future simulator design and evaluation.
Prompting Large Language Models for Topic Modeling
Dec 15, 2023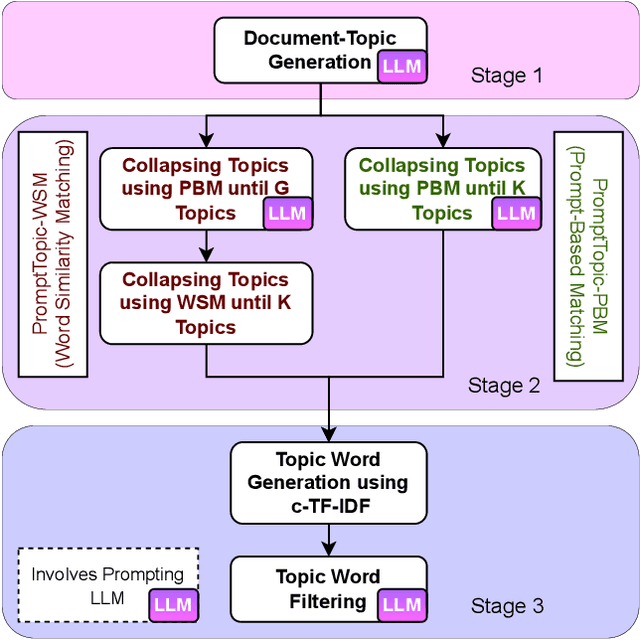

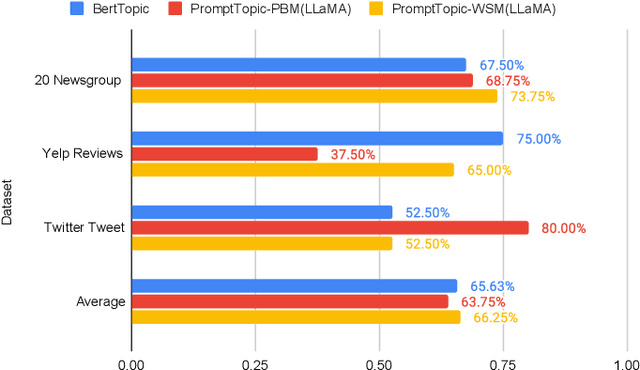

Topic modeling is a widely used technique for revealing underlying thematic structures within textual data. However, existing models have certain limitations, particularly when dealing with short text datasets that lack co-occurring words. Moreover, these models often neglect sentence-level semantics, focusing primarily on token-level semantics. In this paper, we propose PromptTopic, a novel topic modeling approach that harnesses the advanced language understanding of large language models (LLMs) to address these challenges. It involves extracting topics at the sentence level from individual documents, then aggregating and condensing these topics into a predefined quantity, ultimately providing coherent topics for texts of varying lengths. This approach eliminates the need for manual parameter tuning and improves the quality of extracted topics. We benchmark PromptTopic against the state-of-the-art baselines on three vastly diverse datasets, establishing its proficiency in discovering meaningful topics. Furthermore, qualitative analysis showcases PromptTopic's ability to uncover relevant topics in multiple datasets.
PromptMTopic: Unsupervised Multimodal Topic Modeling of Memes using Large Language Models
Dec 11, 2023



The proliferation of social media has given rise to a new form of communication: memes. Memes are multimodal and often contain a combination of text and visual elements that convey meaning, humor, and cultural significance. While meme analysis has been an active area of research, little work has been done on unsupervised multimodal topic modeling of memes, which is important for content moderation, social media analysis, and cultural studies. We propose \textsf{PromptMTopic}, a novel multimodal prompt-based model designed to learn topics from both text and visual modalities by leveraging the language modeling capabilities of large language models. Our model effectively extracts and clusters topics learned from memes, considering the semantic interaction between the text and visual modalities. We evaluate our proposed model through extensive experiments on three real-world meme datasets, which demonstrate its superiority over state-of-the-art topic modeling baselines in learning descriptive topics in memes. Additionally, our qualitative analysis shows that \textsf{PromptMTopic} can identify meaningful and culturally relevant topics from memes. Our work contributes to the understanding of the topics and themes of memes, a crucial form of communication in today's society.\\ \red{\textbf{Disclaimer: This paper contains sensitive content that may be disturbing to some readers.}}
MATK: The Meme Analytical Tool Kit
Dec 11, 2023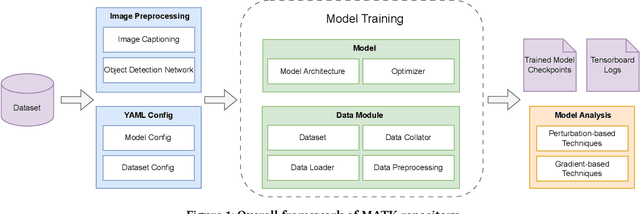
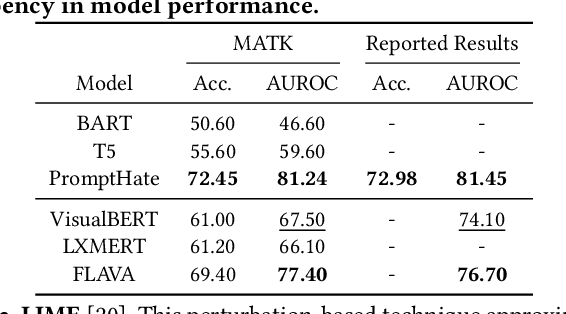
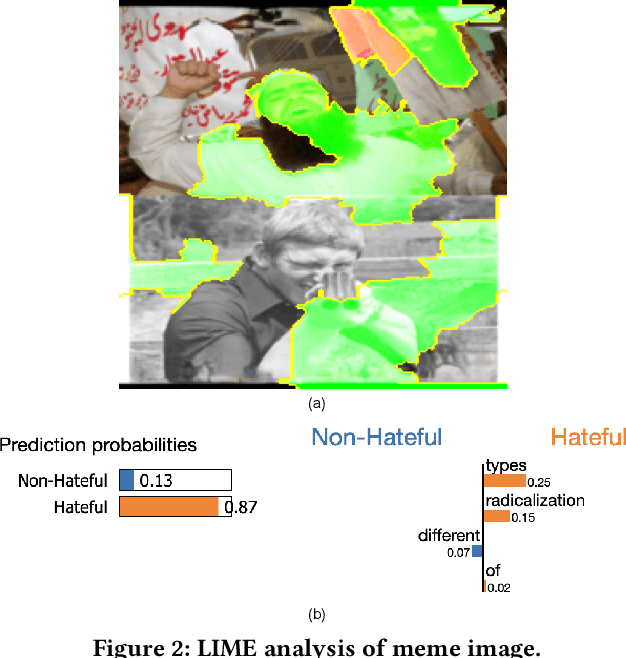
The rise of social media platforms has brought about a new digital culture called memes. Memes, which combine visuals and text, can strongly influence public opinions on social and cultural issues. As a result, people have become interested in categorizing memes, leading to the development of various datasets and multimodal models that show promising results in this field. However, there is currently a lack of a single library that allows for the reproduction, evaluation, and comparison of these models using fair benchmarks and settings. To fill this gap, we introduce the Meme Analytical Tool Kit (MATK), an open-source toolkit specifically designed to support existing memes datasets and cutting-edge multimodal models. MATK aims to assist researchers and engineers in training and reproducing these multimodal models for meme classification tasks, while also providing analysis techniques to gain insights into their strengths and weaknesses. To access MATK, please visit \url{https://github.com/Social-AI-Studio/MATK}.