 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProEval: Proactive Failure Discovery and Efficient Performance Estimation for Generative AI Evaluation
Apr 25, 2026Evaluating generative AI models is increasingly resource-intensive due to slow inference, expensive raters, and a rapidly growing landscape of models and benchmarks. We propose ProEval, a proactive evaluation framework that leverages transfer learning to efficiently estimate performance and identify failure cases. ProEval employs pre-trained Gaussian Processes (GPs) as surrogates for the performance score function, mapping model inputs to metrics such as the severity of errors or safety violations. By framing performance estimation as Bayesian quadrature (BQ) and failure discovery as superlevel set sampling, we develop uncertainty-aware decision strategies that actively select or synthesize highly informative inputs for testing. Theoretically, we prove that our pre-trained GP-based BQ estimator is unbiased and bounded. Empirically, extensive experiments on reasoning, safety alignment, and classification benchmarks demonstrate that ProEval is significantly more efficient than competitive baselines. It requires 8-65x fewer samples to achieve estimates within 1% of the ground truth, while simultaneously revealing more diverse failure cases under a stricter evaluation budget.
SEAHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Southeast Asia
Mar 17, 2026Hate speech detection relies heavily on linguistic resources, which are primarily available in high-resource languages such as English and Chinese, creating barriers for researchers and platforms developing tools for low-resource languages in Southeast Asia, where diverse socio-linguistic contexts complicate online hate moderation. To address this, we introduce SEAHateCheck, a pioneering dataset tailored to Indonesia, Thailand, the Philippines, and Vietnam, covering Indonesian, Tagalog, Thai, and Vietnamese. Building on HateCheck's functional testing framework and refining SGHateCheck's methods, SEAHateCheck provides culturally relevant test cases, augmented by large language models and validated by local experts for accuracy. Experiments with state-of-the-art and multilingual models revealed limitations in detecting hate speech in specific low-resource languages. In particular, Tagalog test cases showed the lowest model accuracy, likely due to linguistic complexity and limited training data. In contrast, slang-based functional tests proved the hardest, as models struggled with culturally nuanced expressions. The diagnostic insights of SEAHateCheck further exposed model weaknesses in implicit hate detection and models' struggles with counter-speech expression. As the first functional test suite for these Southeast Asian languages, this work equips researchers with a robust benchmark, advancing the development of practical, culturally attuned hate speech detection tools for inclusive online content moderation.
Bridging Modalities: Enhancing Cross-Modality Hate Speech Detection with Few-Shot In-Context Learning
Oct 08, 2024The widespread presence of hate speech on the internet, including formats such as text-based tweets and vision-language memes, poses a significant challenge to digital platform safety. Recent research has developed detection models tailored to specific modalities; however, there is a notable gap in transferring detection capabilities across different formats. This study conducts extensive experiments using few-shot in-context learning with large language models to explore the transferability of hate speech detection between modalities. Our findings demonstrate that text-based hate speech examples can significantly enhance the classification accuracy of vision-language hate speech. Moreover, text-based demonstrations outperform vision-language demonstrations in few-shot learning settings. These results highlight the effectiveness of cross-modality knowledge transfer and offer valuable insights for improving hate speech detection systems.
MATK: The Meme Analytical Tool Kit
Dec 11, 2023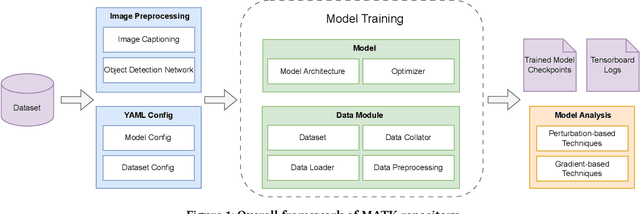
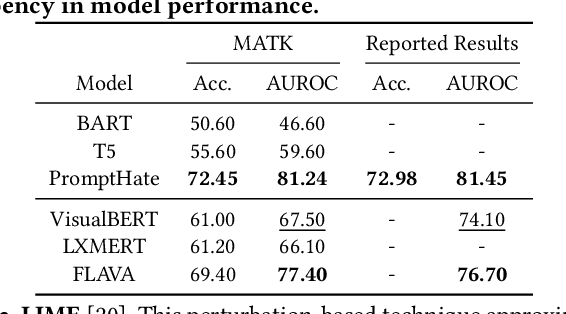
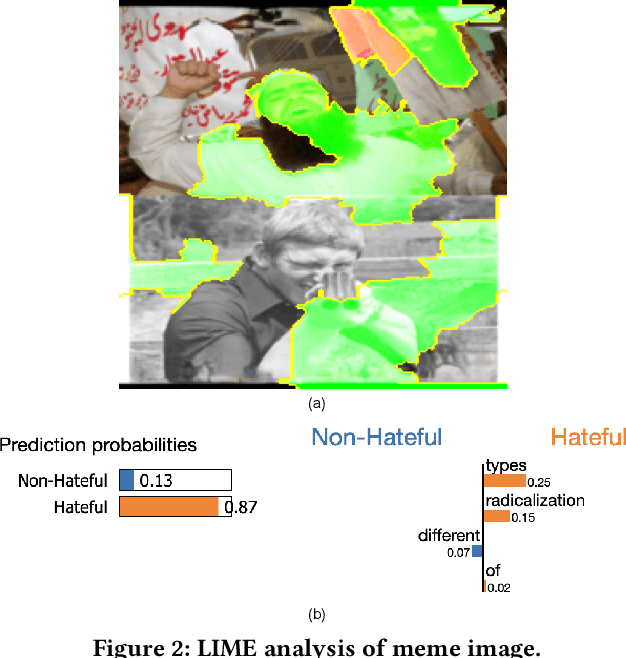
The rise of social media platforms has brought about a new digital culture called memes. Memes, which combine visuals and text, can strongly influence public opinions on social and cultural issues. As a result, people have become interested in categorizing memes, leading to the development of various datasets and multimodal models that show promising results in this field. However, there is currently a lack of a single library that allows for the reproduction, evaluation, and comparison of these models using fair benchmarks and settings. To fill this gap, we introduce the Meme Analytical Tool Kit (MATK), an open-source toolkit specifically designed to support existing memes datasets and cutting-edge multimodal models. MATK aims to assist researchers and engineers in training and reproducing these multimodal models for meme classification tasks, while also providing analysis techniques to gain insights into their strengths and weaknesses. To access MATK, please visit \url{https://github.com/Social-AI-Studio/MATK}.