 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Space Interventions Can Be Transferred Between Large Language Models
Mar 06, 2025The study of representation universality in AI models reveals growing convergence across domains, modalities, and architectures. However, the practical applications of representation universality remain largely unexplored. We bridge this gap by demonstrating that safety interventions can be transferred between models through learned mappings of their shared activation spaces. We demonstrate this approach on two well-established AI safety tasks: backdoor removal and refusal of harmful prompts, showing successful transfer of steering vectors that alter the models' outputs in a predictable way. Additionally, we propose a new task, \textit{corrupted capabilities}, where models are fine-tuned to embed knowledge tied to a backdoor. This tests their ability to separate useful skills from backdoors, reflecting real-world challenges. Extensive experiments across Llama, Qwen and Gemma model families show that our method enables using smaller models to efficiently align larger ones. Furthermore, we demonstrate that autoencoder mappings between base and fine-tuned models can serve as reliable ``lightweight safety switches", allowing dynamic toggling between model behaviors.
Sparse Autoencoders Reveal Universal Feature Spaces Across Large Language Models
Oct 09, 2024
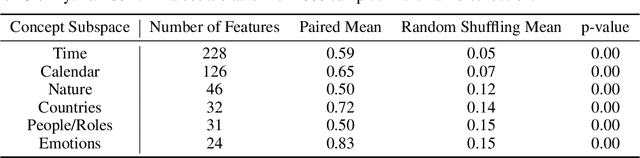
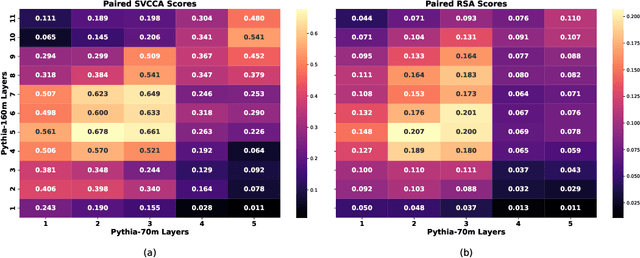
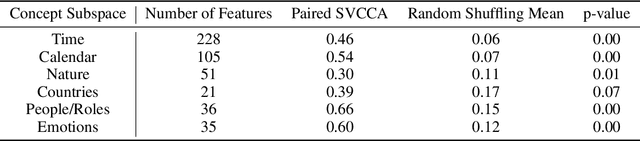
We investigate feature universality in large language models (LLMs), a research field that aims to understand how different models similarly represent concepts in the latent spaces of their intermediate layers. Demonstrating feature universality allows discoveries about latent representations to generalize across several models. However, comparing features across LLMs is challenging due to polysemanticity, in which individual neurons often correspond to multiple features rather than distinct ones. This makes it difficult to disentangle and match features across different models. To address this issue, we employ a method known as dictionary learning by using sparse autoencoders (SAEs) to transform LLM activations into more interpretable spaces spanned by neurons corresponding to individual features. After matching feature neurons across models via activation correlation, we apply representational space similarity metrics like Singular Value Canonical Correlation Analysis to analyze these SAE features across different LLMs. Our experiments reveal significant similarities in SAE feature spaces across various LLMs, providing new evidence for feature universality.
Locating Cross-Task Sequence Continuation Circuits in Transformers
Nov 07, 2023While transformer models exhibit strong capabilities on linguistic tasks, their complex architectures make them difficult to interpret. Recent work has aimed to reverse engineer transformer models into human-readable representations called circuits that implement algorithmic functions. We extend this research by analyzing and comparing circuits for similar sequence continuation tasks, which include increasing sequences of digits, number words, and months. Through the application of circuit analysis techniques, we identify key sub-circuits responsible for detecting sequence members and for predicting the next member in a sequence. Our analysis reveals that semantically related sequences rely on shared circuit subgraphs with analogous roles. Overall, documenting shared computational structures enables better prediction of model behaviors, identification of errors, and safer editing procedures. This mechanistic understanding of transformers is a critical step towards building more robust, aligned, and interpretable language models.