 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWords to Describe What I'm Feeling: Exploring the Potential of AI Agents for High Subjectivity Decisions in Advance Care Planning
Dec 12, 2025Serious illness can deprive patients of the capacity to speak for themselves. As populations age and caregiver networks shrink, the need for reliable support in Advance Care Planning (ACP) grows. To probe this fraught design space of using proxy agents for high-risk, high-subjectivity decisions, we built an experience prototype (\acpagent{}) and asked 15 participants in 4 workshops to train it to be their personal proxy in ACP decisions. We analysed their coping strategies and feature requests and mapped the results onto axes of agent autonomy and human control. Our findings argue for a potential new role of AI in ACP where agents act as personal advocates for individuals, building mutual intelligibility over time. We conclude with design recommendations to balance the risks and benefits of such an agent.
"I Said Things I Needed to Hear Myself": Peer Support as an Emotional, Organisational, and Sociotechnical Practice in Singapore
Jun 11, 2025Peer support plays a vital role in expanding access to mental health care by providing empathetic, community-based support outside formal clinical systems. As digital platforms increasingly mediate such support, the design and impact of these technologies remain under-examined, particularly in Asian contexts. This paper presents findings from an interview study with 20 peer supporters in Singapore, who operate across diverse online, offline, and hybrid environments. Through a thematic analysis, we unpack how participants start, conduct, and sustain peer support, highlighting their motivations, emotional labour, and the sociocultural dimensions shaping their practices. Building on this grounded understanding, we surface design directions for culturally responsive digital tools that scaffold rather than supplant relational care. Drawing insights from qualitative accounts, we offer a situated perspective on how AI might responsibly augment peer support. This research contributes to human-centred computing by articulating the lived realities of peer supporters and proposing design implications for trustworthy and context-sensitive AI in mental health.
"Is This Really a Human Peer Supporter?": Misalignments Between Peer Supporters and Experts in LLM-Supported Interactions
Jun 11, 2025Mental health is a growing global concern, prompting interest in AI-driven solutions to expand access to psychosocial support. Peer support, grounded in lived experience, offers a valuable complement to professional care. However, variability in training, effectiveness, and definitions raises concerns about quality, consistency, and safety. Large Language Models (LLMs) present new opportunities to enhance peer support interactions, particularly in real-time, text-based interactions. We present and evaluate an AI-supported system with an LLM-simulated distressed client, context-sensitive LLM-generated suggestions, and real-time emotion visualisations. 2 mixed-methods studies with 12 peer supporters and 5 mental health professionals (i.e., experts) examined the system's effectiveness and implications for practice. Both groups recognised its potential to enhance training and improve interaction quality. However, we found a key tension emerged: while peer supporters engaged meaningfully, experts consistently flagged critical issues in peer supporter responses, such as missed distress cues and premature advice-giving. This misalignment highlights potential limitations in current peer support training, especially in emotionally charged contexts where safety and fidelity to best practices are essential. Our findings underscore the need for standardised, psychologically grounded training, especially as peer support scales globally. They also demonstrate how LLM-supported systems can scaffold this development--if designed with care and guided by expert oversight. This work contributes to emerging conversations on responsible AI integration in mental health and the evolving role of LLMs in augmenting peer-delivered care.
Sword and Shield: Uses and Strategies of LLMs in Navigating Disinformation
Jun 08, 2025The emergence of Large Language Models (LLMs) presents a dual challenge in the fight against disinformation. These powerful tools, capable of generating human-like text at scale, can be weaponised to produce sophisticated and persuasive disinformation, yet they also hold promise for enhancing detection and mitigation strategies. This paper investigates the complex dynamics between LLMs and disinformation through a communication game that simulates online forums, inspired by the game Werewolf, with 25 participants. We analyse how Disinformers, Moderators, and Users leverage LLMs to advance their goals, revealing both the potential for misuse and combating disinformation. Our findings highlight the varying uses of LLMs depending on the participants' roles and strategies, underscoring the importance of understanding their effectiveness in this context. We conclude by discussing implications for future LLM development and online platform design, advocating for a balanced approach that empowers users and fosters trust while mitigating the risks of LLM-assisted disinformation.
Envisioning an AI-Enhanced Mental Health Ecosystem
Mar 19, 2025The rapid advancement of Large Language Models (LLMs), reasoning models, and agentic AI approaches coincides with a growing global mental health crisis, where increasing demand has not translated into adequate access to professional support, particularly for underserved populations. This presents a unique opportunity for AI to complement human-led interventions, offering scalable and context-aware support while preserving human connection in this sensitive domain. We explore various AI applications in peer support, self-help interventions, proactive monitoring, and data-driven insights, using a human-centred approach that ensures AI supports rather than replaces human interaction. However, AI deployment in mental health fields presents challenges such as ethical concerns, transparency, privacy risks, and risks of over-reliance. We propose a hybrid ecosystem where where AI assists but does not replace human providers, emphasising responsible deployment and evaluation. We also present some of our early work and findings in several of these AI applications. Finally, we outline future research directions for refining AI-enhanced interventions while adhering to ethical and culturally sensitive guidelines.
Analyzing Swimming Performance Using Drone Captured Aerial Videos
Mar 17, 2025
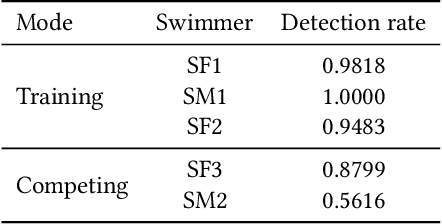

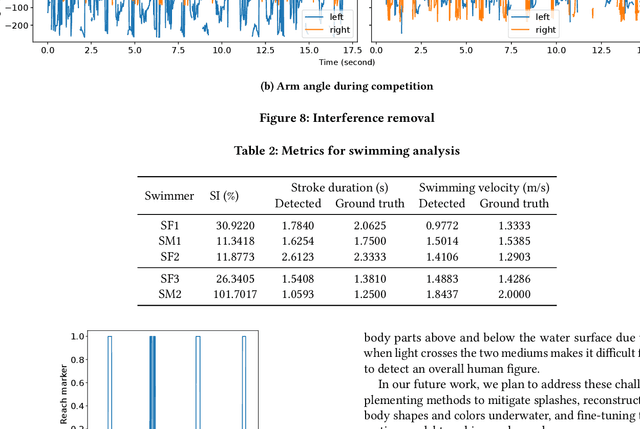
Monitoring swimmer performance is crucial for improving training and enhancing athletic techniques. Traditional methods for tracking swimmers, such as above-water and underwater cameras, face limitations due to the need for multiple cameras and obstructions from water splashes. This paper presents a novel approach for tracking swimmers using a moving UAV. The proposed system employs a UAV equipped with a high-resolution camera to capture aerial footage of the swimmers. The footage is then processed using computer vision algorithms to extract the swimmers' positions and movements. This approach offers several advantages, including single camera use and comprehensive coverage. The system's accuracy is evaluated with both training and in competition videos. The results demonstrate the system's ability to accurately track swimmers' movements, limb angles, stroke duration and velocity with the maximum error of 0.3 seconds and 0.35~m/s for stroke duration and velocity, respectively.
Exploring Gaze Pattern in Autistic Children: Clustering, Visualization, and Prediction
Sep 18, 2024

Autism Spectrum Disorder (ASD) significantly affects the social and communication abilities of children, and eye-tracking is commonly used as a diagnostic tool by identifying associated atypical gaze patterns. Traditional methods demand manual identification of Areas of Interest in gaze patterns, lowering the performance of gaze behavior analysis in ASD subjects. To tackle this limitation, we propose a novel method to automatically analyze gaze behaviors in ASD children with superior accuracy. To be specific, we first apply and optimize seven clustering algorithms to automatically group gaze points to compare ASD subjects with typically developing peers. Subsequently, we extract 63 significant features to fully describe the patterns. These features can describe correlations between ASD diagnosis and gaze patterns. Lastly, using these features as prior knowledge, we train multiple predictive machine learning models to predict and diagnose ASD based on their gaze behaviors. To evaluate our method, we apply our method to three ASD datasets. The experimental and visualization results demonstrate the improvements of clustering algorithms in the analysis of unique gaze patterns in ASD children. Additionally, these predictive machine learning models achieved state-of-the-art prediction performance ($81\%$ AUC) in the field of automatically constructed gaze point features for ASD diagnosis. Our code is available at \url{https://github.com/username/projectname}.
ToxiCloakCN: Evaluating Robustness of Offensive Language Detection in Chinese with Cloaking Perturbations
Jun 18, 2024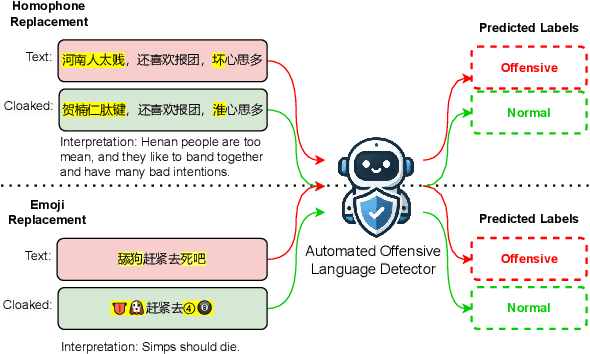
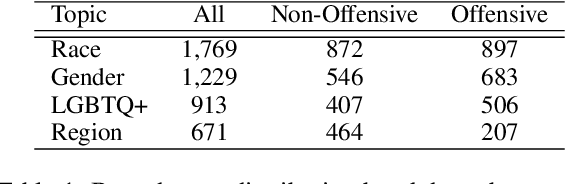

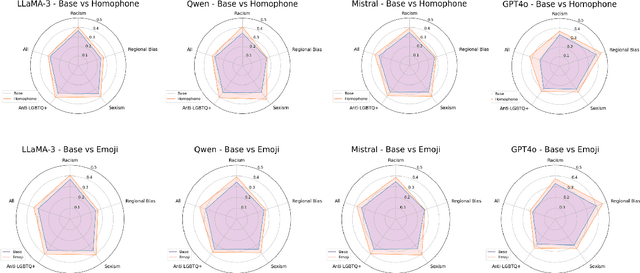
Detecting hate speech and offensive language is essential for maintaining a safe and respectful digital environment. This study examines the limitations of state-of-the-art large language models (LLMs) in identifying offensive content within systematically perturbed data, with a focus on Chinese, a language particularly susceptible to such perturbations. We introduce \textsf{ToxiCloakCN}, an enhanced dataset derived from ToxiCN, augmented with homophonic substitutions and emoji transformations, to test the robustness of LLMs against these cloaking perturbations. Our findings reveal that existing models significantly underperform in detecting offensive content when these perturbations are applied. We provide an in-depth analysis of how different types of offensive content are affected by these perturbations and explore the alignment between human and model explanations of offensiveness. Our work highlights the urgent need for more advanced techniques in offensive language detection to combat the evolving tactics used to evade detection mechanisms.
Towards Understanding Emotions for Engaged Mental Health Conversations
Jun 17, 2024Providing timely support and intervention is crucial in mental health settings. As the need to engage youth comfortable with texting increases, mental health providers are exploring and adopting text-based media such as chatbots, community-based forums, online therapies with licensed professionals, and helplines operated by trained responders. To support these text-based media for mental health--particularly for crisis care--we are developing a system to perform passive emotion-sensing using a combination of keystroke dynamics and sentiment analysis. Our early studies of this system posit that the analysis of short text messages and keyboard typing patterns can provide emotion information that may be used to support both clients and responders. We use our preliminary findings to discuss the way forward for applying AI to support mental health providers in providing better care.
SGHateCheck: Functional Tests for Detecting Hate Speech in Low-Resource Languages of Singapore
May 03, 2024



To address the limitations of current hate speech detection models, we introduce \textsf{SGHateCheck}, a novel framework designed for the linguistic and cultural context of Singapore and Southeast Asia. It extends the functional testing approach of HateCheck and MHC, employing large language models for translation and paraphrasing into Singapore's main languages, and refining these with native annotators. \textsf{SGHateCheck} reveals critical flaws in state-of-the-art models, highlighting their inadequacy in sensitive content moderation. This work aims to foster the development of more effective hate speech detection tools for diverse linguistic environments, particularly for Singapore and Southeast Asia contexts.