 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing Swimming Performance Using Drone Captured Aerial Videos
Mar 17, 2025
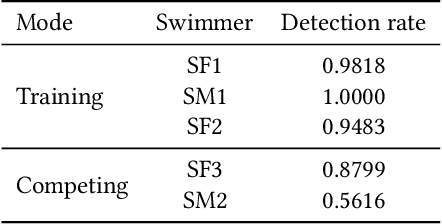

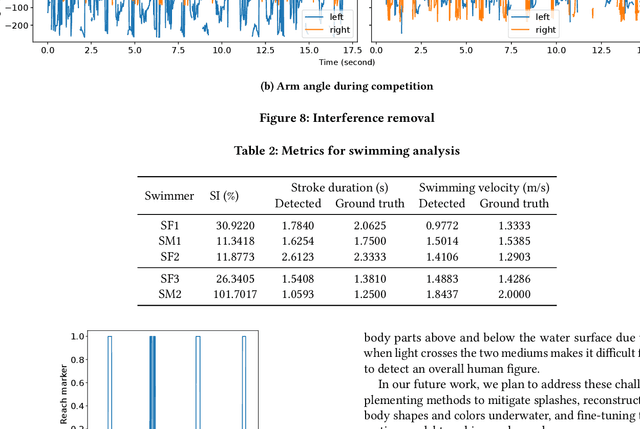
Monitoring swimmer performance is crucial for improving training and enhancing athletic techniques. Traditional methods for tracking swimmers, such as above-water and underwater cameras, face limitations due to the need for multiple cameras and obstructions from water splashes. This paper presents a novel approach for tracking swimmers using a moving UAV. The proposed system employs a UAV equipped with a high-resolution camera to capture aerial footage of the swimmers. The footage is then processed using computer vision algorithms to extract the swimmers' positions and movements. This approach offers several advantages, including single camera use and comprehensive coverage. The system's accuracy is evaluated with both training and in competition videos. The results demonstrate the system's ability to accurately track swimmers' movements, limb angles, stroke duration and velocity with the maximum error of 0.3 seconds and 0.35~m/s for stroke duration and velocity, respectively.
Detecting abnormal heart sound using mobile phones and on-device IConNet
Dec 04, 2024


Given the global prevalence of cardiovascular diseases, there is a pressing need for easily accessible early screening methods. Typically, this requires medical practitioners to investigate heart auscultations for irregular sounds, followed by echocardiography and electrocardiography tests. To democratize early diagnosis, we present a user-friendly solution for abnormal heart sound detection, utilizing mobile phones and a lightweight neural network optimized for on-device inference. Unlike previous approaches reliant on specialized stethoscopes, our method directly analyzes audio recordings, facilitated by a novel architecture known as IConNet. IConNet, an Interpretable Convolutional Neural Network, harnesses insights from audio signal processing, enhancing efficiency and providing transparency in neural pattern extraction from raw waveform signals. This is a significant step towards trustworthy AI in healthcare, aiding in remote health monitoring efforts.
Toward end-to-end interpretable convolutional neural networks for waveform signals
May 03, 2024



This paper introduces a novel convolutional neural networks (CNN) framework tailored for end-to-end audio deep learning models, presenting advancements in efficiency and explainability. By benchmarking experiments on three standard speech emotion recognition datasets with five-fold cross-validation, our framework outperforms Mel spectrogram features by up to seven percent. It can potentially replace the Mel-Frequency Cepstral Coefficients (MFCC) while remaining lightweight. Furthermore, we demonstrate the efficiency and interpretability of the front-end layer using the PhysioNet Heart Sound Database, illustrating its ability to handle and capture intricate long waveform patterns. Our contributions offer a portable solution for building efficient and interpretable models for raw waveform data.