 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating GPT-3 Generated Explanations for Hateful Content Moderation
May 28, 2023Recent research has focused on using large language models (LLMs) to generate explanations for hate speech through fine-tuning or prompting. Despite the growing interest in this area, these generated explanations' effectiveness and potential limitations remain poorly understood. A key concern is that these explanations, generated by LLMs, may lead to erroneous judgments about the nature of flagged content by both users and content moderators. For instance, an LLM-generated explanation might inaccurately convince a content moderator that a benign piece of content is hateful. In light of this, we propose an analytical framework for examining hate speech explanations and conducted an extensive survey on evaluating such explanations. Specifically, we prompted GPT-3 to generate explanations for both hateful and non-hateful content, and a survey was conducted with 2,400 unique respondents to evaluate the generated explanations. Our findings reveal that (1) human evaluators rated the GPT-generated explanations as high quality in terms of linguistic fluency, informativeness, persuasiveness, and logical soundness, (2) the persuasive nature of these explanations, however, varied depending on the prompting strategy employed, and (3) this persuasiveness may result in incorrect judgments about the hatefulness of the content. Our study underscores the need for caution in applying LLM-generated explanations for content moderation. Code and results are available at https://github.com/Social-AI-Studio/GPT3-HateEval.
Model-Agnostic Meta-Learning for Multilingual Hate Speech Detection
Mar 04, 2023Hate speech in social media is a growing phenomenon, and detecting such toxic content has recently gained significant traction in the research community. Existing studies have explored fine-tuning language models (LMs) to perform hate speech detection, and these solutions have yielded significant performance. However, most of these studies are limited to detecting hate speech only in English, neglecting the bulk of hateful content that is generated in other languages, particularly in low-resource languages. Developing a classifier that captures hate speech and nuances in a low-resource language with limited data is extremely challenging. To fill the research gap, we propose HateMAML, a model-agnostic meta-learning-based framework that effectively performs hate speech detection in low-resource languages. HateMAML utilizes a self-supervision strategy to overcome the limitation of data scarcity and produces better LM initialization for fast adaptation to an unseen target language (i.e., cross-lingual transfer) or other hate speech datasets (i.e., domain generalization). Extensive experiments are conducted on five datasets across eight different low-resource languages. The results show that HateMAML outperforms the state-of-the-art baselines by more than 3% in the cross-domain multilingual transfer setting. We also conduct ablation studies to analyze the characteristics of HateMAML.
AngryBERT: Joint Learning Target and Emotion for Hate Speech Detection
Mar 14, 2021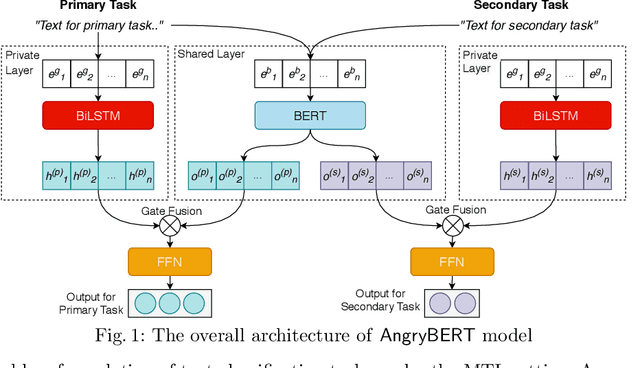
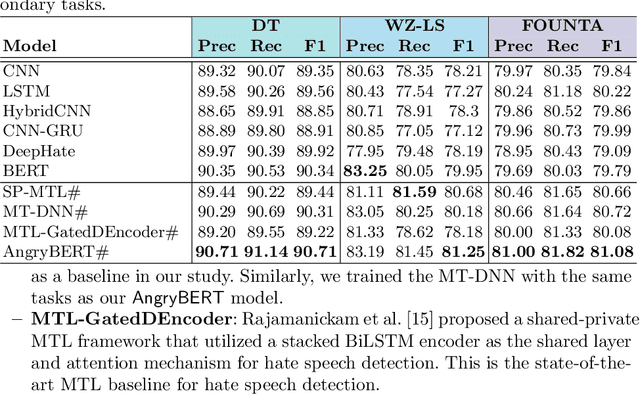
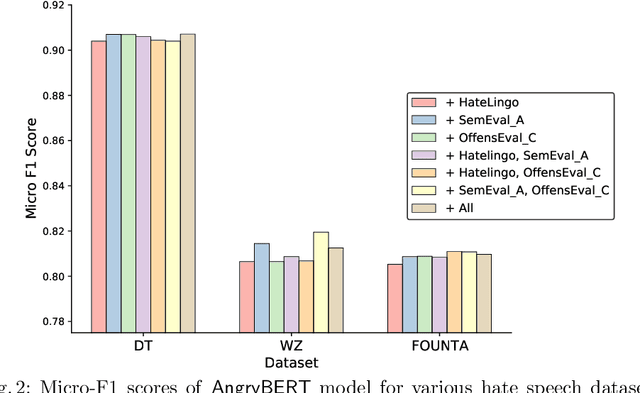

Automated hate speech detection in social media is a challenging task that has recently gained significant traction in the data mining and Natural Language Processing community. However, most of the existing methods adopt a supervised approach that depended heavily on the annotated hate speech datasets, which are imbalanced and often lack training samples for hateful content. This paper addresses the research gaps by proposing a novel multitask learning-based model, AngryBERT, which jointly learns hate speech detection with sentiment classification and target identification as secondary relevant tasks. We conduct extensive experiments to augment three commonly-used hate speech detection datasets. Our experiment results show that AngryBERT outperforms state-of-the-art single-task-learning and multitask learning baselines. We conduct ablation studies and case studies to empirically examine the strengths and characteristics of our AngryBERT model and show that the secondary tasks are able to improve hate speech detection.
On Analyzing Antisocial Behaviors Amid COVID-19 Pandemic
Jul 21, 2020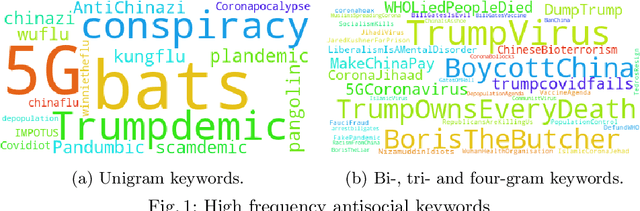
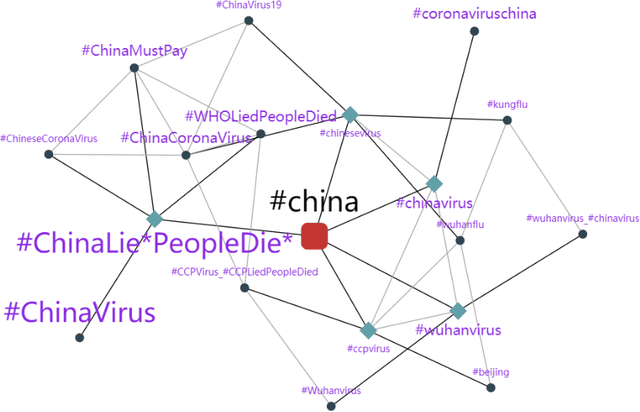
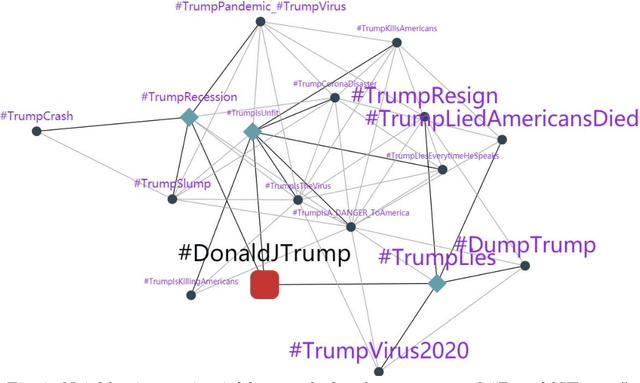
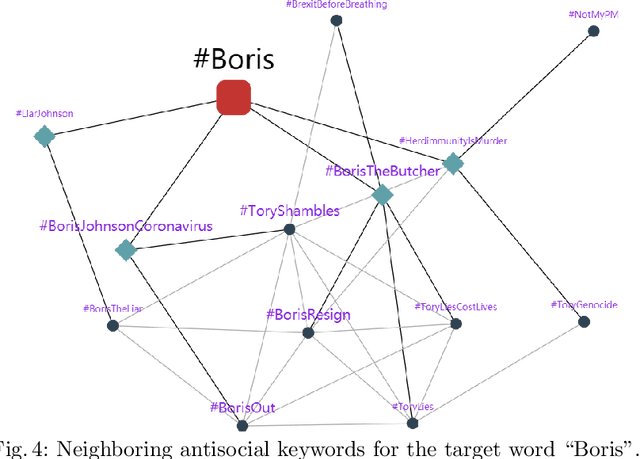
The COVID-19 pandemic has developed to be more than a bio-crisis as global news has reported a sharp rise in xenophobia and discrimination in both online and offline communities. Such toxic behaviors take a heavy toll on society, especially during these daunting times. Despite the gravity of the issue, very few studies have studied online antisocial behaviors amid the COVID-19 pandemic. In this paper, we fill the research gap by collecting and annotating a large dataset of over 40 million COVID-19 related tweets. Specially, we propose an annotation framework to annotate the antisocial behavior tweets automatically. We also conduct an empirical analysis of our annotated dataset and found that new abusive lexicons are introduced amid the COVID-19 pandemic. Our study also identified the vulnerable targets of antisocial behaviors and the factors that influence the spreading of online antisocial content.
On Analyzing Annotation Consistency in Online Abusive Behavior Datasets
Jun 24, 2020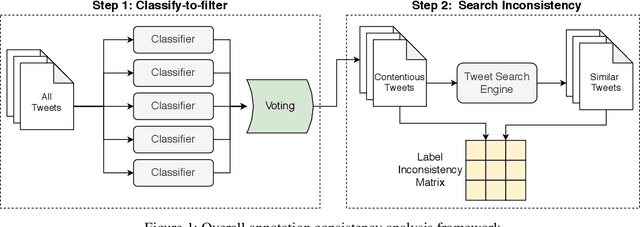

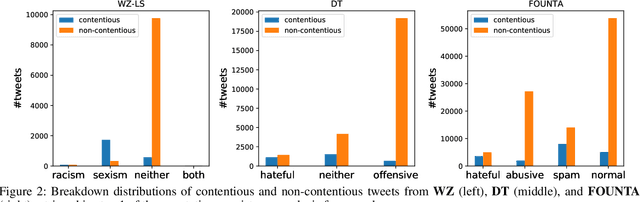
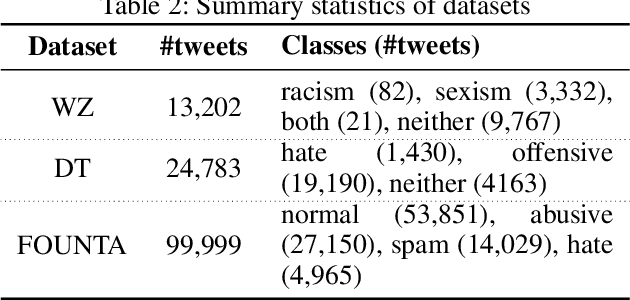
Online abusive behavior is an important issue that breaks the cohesiveness of online social communities and even raises public safety concerns in our societies. Motivated by this rising issue, researchers have proposed, collected, and annotated online abusive content datasets. These datasets play a critical role in facilitating the research on online hate speech and abusive behaviors. However, the annotation of such datasets is a difficult task; it is often contentious on what should be the true label of a given text as the semantic difference of the labels may be blurred (e.g., abusive and hate) and often subjective. In this study, we proposed an analytical framework to study the annotation consistency in online hate and abusive content datasets. We applied our proposed framework to evaluate the consistency of the annotation in three popular datasets that are widely used in online hate speech and abusive behavior studies. We found that there is still a substantial amount of annotation inconsistency in the existing datasets, particularly when the labels are semantically similar.