 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngryBERT: Joint Learning Target and Emotion for Hate Speech Detection
Mar 14, 2021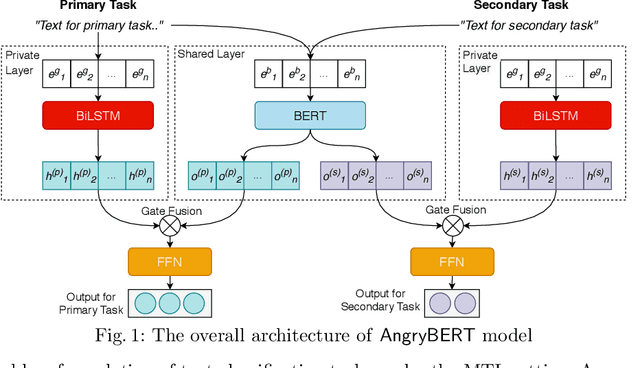
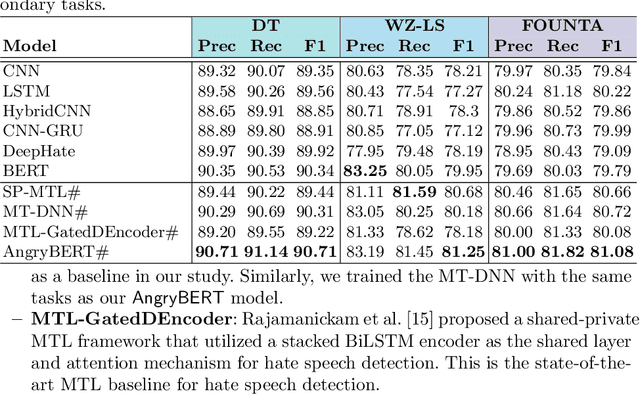
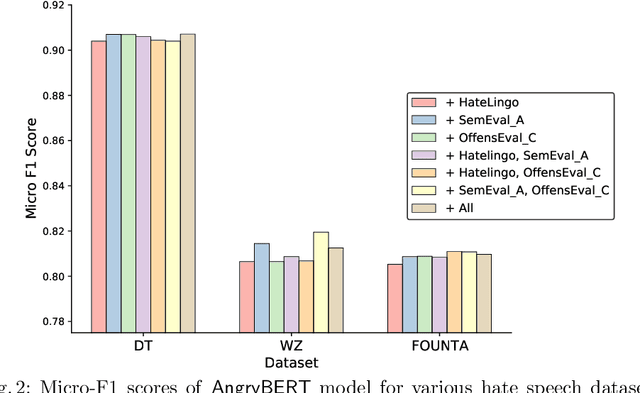

Automated hate speech detection in social media is a challenging task that has recently gained significant traction in the data mining and Natural Language Processing community. However, most of the existing methods adopt a supervised approach that depended heavily on the annotated hate speech datasets, which are imbalanced and often lack training samples for hateful content. This paper addresses the research gaps by proposing a novel multitask learning-based model, AngryBERT, which jointly learns hate speech detection with sentiment classification and target identification as secondary relevant tasks. We conduct extensive experiments to augment three commonly-used hate speech detection datasets. Our experiment results show that AngryBERT outperforms state-of-the-art single-task-learning and multitask learning baselines. We conduct ablation studies and case studies to empirically examine the strengths and characteristics of our AngryBERT model and show that the secondary tasks are able to improve hate speech detection.
SST-BERT at SemEval-2020 Task 1: Semantic Shift Tracing by Clustering in BERT-based Embedding Spaces
Oct 02, 2020

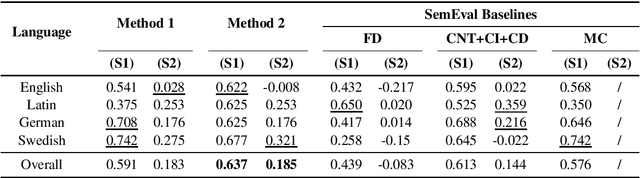
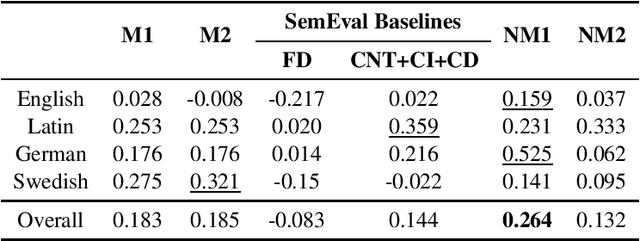
Lexical semantic change detection (also known as semantic shift tracing) is a task of identifying words that have changed their meaning over time. Unsupervised semantic shift tracing, focal point of SemEval2020, is particularly challenging. Given the unsupervised setup, in this work, we propose to identify clusters among different occurrences of each target word, considering these as representatives of different word meanings. As such, disagreements in obtained clusters naturally allow to quantify the level of semantic shift per each target word in four target languages. To leverage this idea, clustering is performed on contextualized (BERT-based) embeddings of word occurrences. The obtained results show that our approach performs well both measured separately (per language) and overall, where we surpass all provided SemEval baselines.
On Analyzing Antisocial Behaviors Amid COVID-19 Pandemic
Jul 21, 2020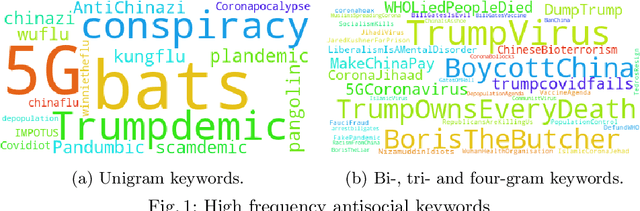
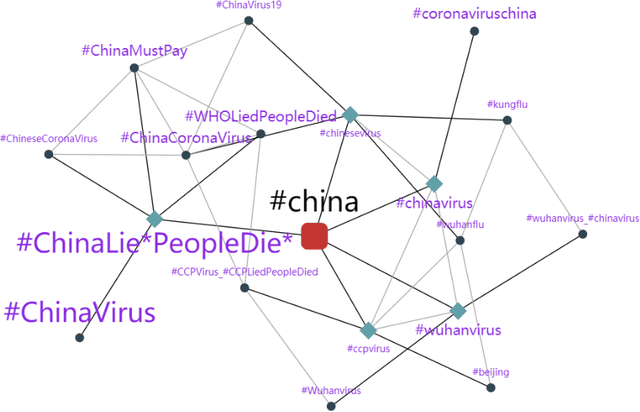
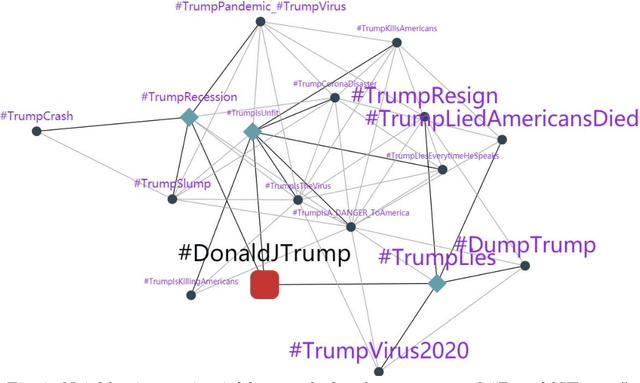
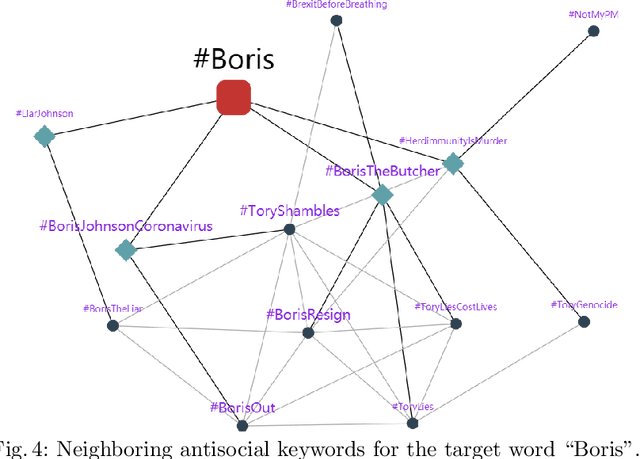
The COVID-19 pandemic has developed to be more than a bio-crisis as global news has reported a sharp rise in xenophobia and discrimination in both online and offline communities. Such toxic behaviors take a heavy toll on society, especially during these daunting times. Despite the gravity of the issue, very few studies have studied online antisocial behaviors amid the COVID-19 pandemic. In this paper, we fill the research gap by collecting and annotating a large dataset of over 40 million COVID-19 related tweets. Specially, we propose an annotation framework to annotate the antisocial behavior tweets automatically. We also conduct an empirical analysis of our annotated dataset and found that new abusive lexicons are introduced amid the COVID-19 pandemic. Our study also identified the vulnerable targets of antisocial behaviors and the factors that influence the spreading of online antisocial content.