 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Clustering in Narrative Knowledge Graphs
Nov 27, 2020

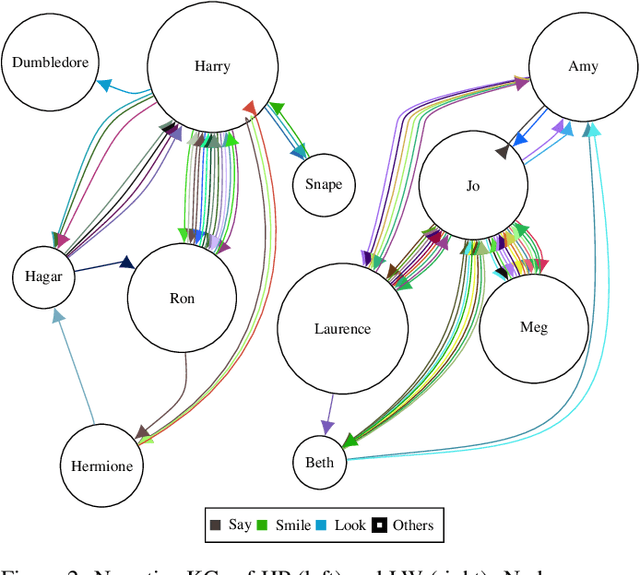
When coping with literary texts such as novels or short stories, the extraction of structured information in the form of a knowledge graph might be hindered by the huge number of possible relations between the entities corresponding to the characters in the novel and the consequent hurdles in gathering supervised information about them. Such issue is addressed here as an unsupervised task empowered by transformers: relational sentences in the original text are embedded (with SBERT) and clustered in order to merge together semantically similar relations. All the sentences in the same cluster are finally summarized (with BART) and a descriptive label extracted from the summary. Preliminary tests show that such clustering might successfully detect similar relations, and provide a valuable preprocessing for semi-supervised approaches.
SST-BERT at SemEval-2020 Task 1: Semantic Shift Tracing by Clustering in BERT-based Embedding Spaces
Oct 02, 2020

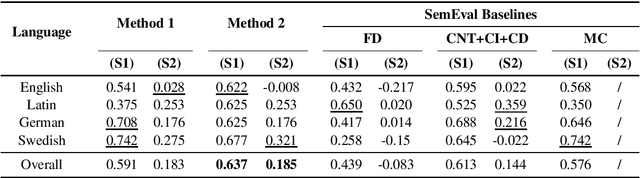
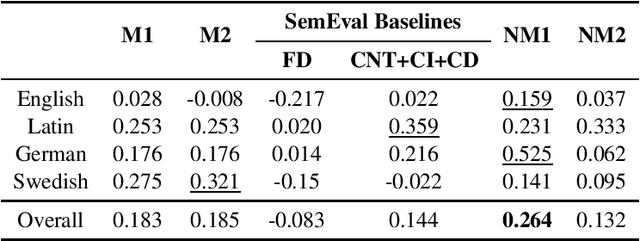
Lexical semantic change detection (also known as semantic shift tracing) is a task of identifying words that have changed their meaning over time. Unsupervised semantic shift tracing, focal point of SemEval2020, is particularly challenging. Given the unsupervised setup, in this work, we propose to identify clusters among different occurrences of each target word, considering these as representatives of different word meanings. As such, disagreements in obtained clusters naturally allow to quantify the level of semantic shift per each target word in four target languages. To leverage this idea, clustering is performed on contextualized (BERT-based) embeddings of word occurrences. The obtained results show that our approach performs well both measured separately (per language) and overall, where we surpass all provided SemEval baselines.