 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Clustering in Narrative Knowledge Graphs
Paper and Code


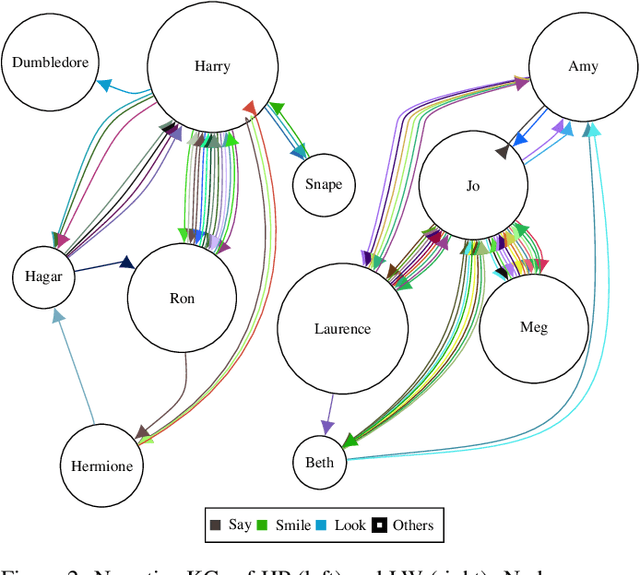
When coping with literary texts such as novels or short stories, the extraction of structured information in the form of a knowledge graph might be hindered by the huge number of possible relations between the entities corresponding to the characters in the novel and the consequent hurdles in gathering supervised information about them. Such issue is addressed here as an unsupervised task empowered by transformers: relational sentences in the original text are embedded (with SBERT) and clustered in order to merge together semantically similar relations. All the sentences in the same cluster are finally summarized (with BART) and a descriptive label extracted from the summary. Preliminary tests show that such clustering might successfully detect similar relations, and provide a valuable preprocessing for semi-supervised approaches.