 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Clustering in Narrative Knowledge Graphs
Nov 27, 2020

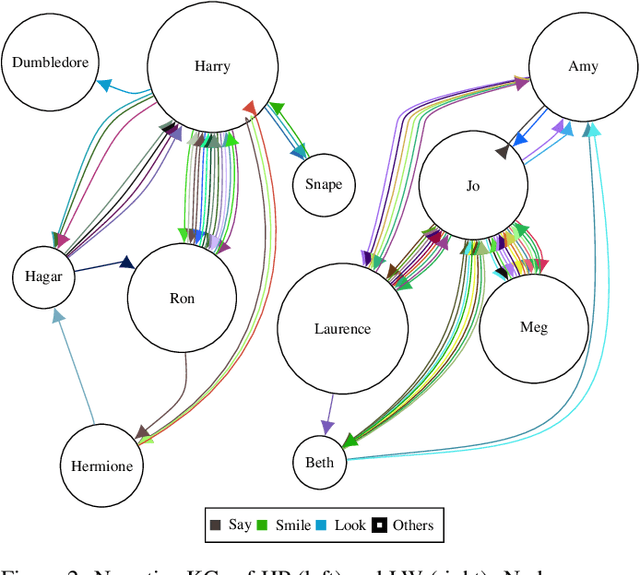
When coping with literary texts such as novels or short stories, the extraction of structured information in the form of a knowledge graph might be hindered by the huge number of possible relations between the entities corresponding to the characters in the novel and the consequent hurdles in gathering supervised information about them. Such issue is addressed here as an unsupervised task empowered by transformers: relational sentences in the original text are embedded (with SBERT) and clustered in order to merge together semantically similar relations. All the sentences in the same cluster are finally summarized (with BART) and a descriptive label extracted from the summary. Preliminary tests show that such clustering might successfully detect similar relations, and provide a valuable preprocessing for semi-supervised approaches.
Temporal Embeddings and Transformer Models for Narrative Text Understanding
Mar 19, 2020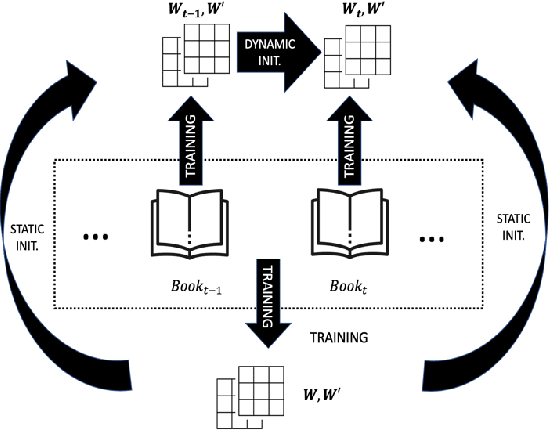



We present two deep learning approaches to narrative text understanding for character relationship modelling. The temporal evolution of these relations is described by dynamic word embeddings, that are designed to learn semantic changes over time. An empirical analysis of the corresponding character trajectories shows that such approaches are effective in depicting dynamic evolution. A supervised learning approach based on the state-of-the-art transformer model BERT is used instead to detect static relations between characters. The empirical validation shows that such events (e.g., two characters belonging to the same family) might be spotted with good accuracy, even when using automatically annotated data. This provides a deeper understanding of narrative plots based on the identification of key facts. Standard clustering techniques are finally used for character de-aliasing, a necessary pre-processing step for both approaches. Overall, deep learning models appear to be suitable for narrative text understanding, while also providing a challenging and unexploited benchmark for general natural language understanding.