 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngryBERT: Joint Learning Target and Emotion for Hate Speech Detection
Paper and Code
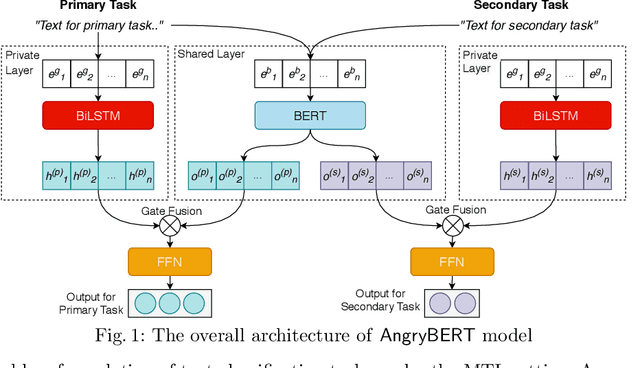
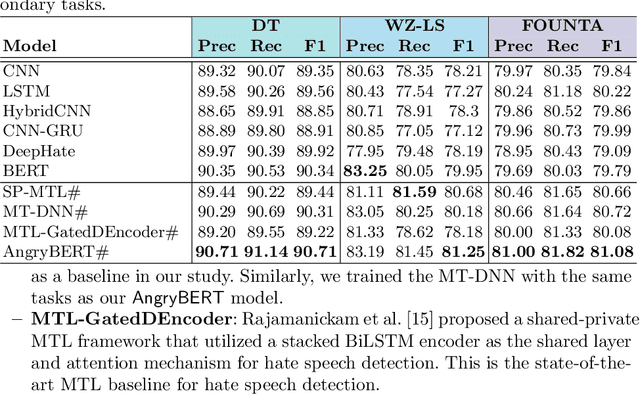
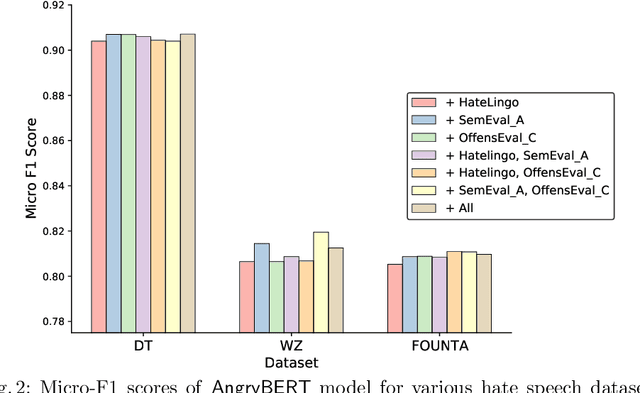

Automated hate speech detection in social media is a challenging task that has recently gained significant traction in the data mining and Natural Language Processing community. However, most of the existing methods adopt a supervised approach that depended heavily on the annotated hate speech datasets, which are imbalanced and often lack training samples for hateful content. This paper addresses the research gaps by proposing a novel multitask learning-based model, AngryBERT, which jointly learns hate speech detection with sentiment classification and target identification as secondary relevant tasks. We conduct extensive experiments to augment three commonly-used hate speech detection datasets. Our experiment results show that AngryBERT outperforms state-of-the-art single-task-learning and multitask learning baselines. We conduct ablation studies and case studies to empirically examine the strengths and characteristics of our AngryBERT model and show that the secondary tasks are able to improve hate speech detection.