 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Ante-Hoc Explainable Models through Generative Adversarial Networks
Jan 09, 2024



This paper presents a novel concept learning framework for enhancing model interpretability and performance in visual classification tasks. Our approach appends an unsupervised explanation generator to the primary classifier network and makes use of adversarial training. During training, the explanation module is optimized to extract visual concepts from the classifier's latent representations, while the GAN-based module aims to discriminate images generated from concepts, from true images. This joint training scheme enables the model to implicitly align its internally learned concepts with human-interpretable visual properties. Comprehensive experiments demonstrate the robustness of our approach, while producing coherent concept activations. We analyse the learned concepts, showing their semantic concordance with object parts and visual attributes. We also study how perturbations in the adversarial training protocol impact both classification and concept acquisition. In summary, this work presents a significant step towards building inherently interpretable deep vision models with task-aligned concept representations - a key enabler for developing trustworthy AI for real-world perception tasks.
Building a Winning Team: Selecting Source Model Ensembles using a Submodular Transferability Estimation Approach
Sep 05, 2023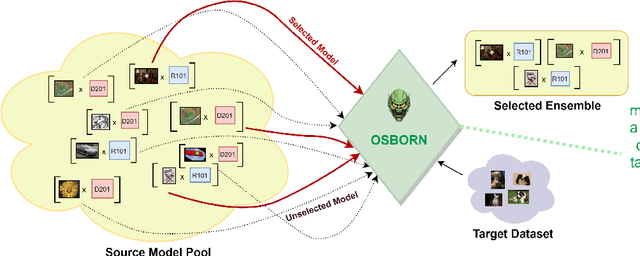


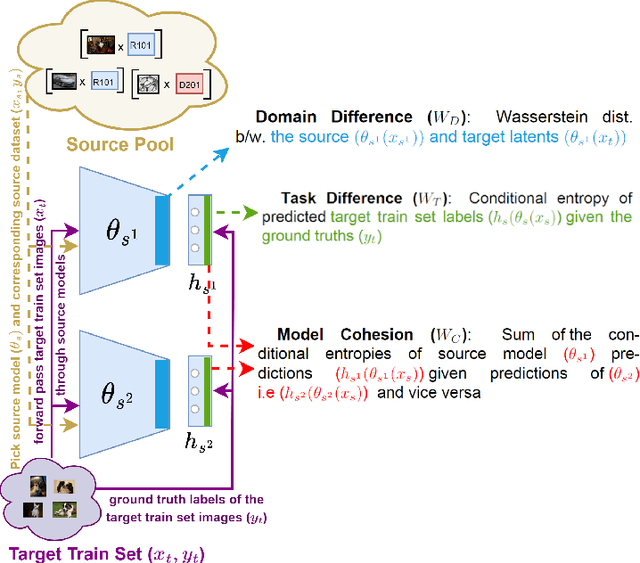
Estimating the transferability of publicly available pretrained models to a target task has assumed an important place for transfer learning tasks in recent years. Existing efforts propose metrics that allow a user to choose one model from a pool of pre-trained models without having to fine-tune each model individually and identify one explicitly. With the growth in the number of available pre-trained models and the popularity of model ensembles, it also becomes essential to study the transferability of multiple-source models for a given target task. The few existing efforts study transferability in such multi-source ensemble settings using just the outputs of the classification layer and neglect possible domain or task mismatch. Moreover, they overlook the most important factor while selecting the source models, viz., the cohesiveness factor between them, which can impact the performance and confidence in the prediction of the ensemble. To address these gaps, we propose a novel Optimal tranSport-based suBmOdular tRaNsferability metric (OSBORN) to estimate the transferability of an ensemble of models to a downstream task. OSBORN collectively accounts for image domain difference, task difference, and cohesiveness of models in the ensemble to provide reliable estimates of transferability. We gauge the performance of OSBORN on both image classification and semantic segmentation tasks. Our setup includes 28 source datasets, 11 target datasets, 5 model architectures, and 2 pre-training methods. We benchmark our method against current state-of-the-art metrics MS-LEEP and E-LEEP, and outperform them consistently using the proposed approach.
Model-Agnostic Meta-Learning for Multilingual Hate Speech Detection
Mar 04, 2023Hate speech in social media is a growing phenomenon, and detecting such toxic content has recently gained significant traction in the research community. Existing studies have explored fine-tuning language models (LMs) to perform hate speech detection, and these solutions have yielded significant performance. However, most of these studies are limited to detecting hate speech only in English, neglecting the bulk of hateful content that is generated in other languages, particularly in low-resource languages. Developing a classifier that captures hate speech and nuances in a low-resource language with limited data is extremely challenging. To fill the research gap, we propose HateMAML, a model-agnostic meta-learning-based framework that effectively performs hate speech detection in low-resource languages. HateMAML utilizes a self-supervision strategy to overcome the limitation of data scarcity and produces better LM initialization for fast adaptation to an unseen target language (i.e., cross-lingual transfer) or other hate speech datasets (i.e., domain generalization). Extensive experiments are conducted on five datasets across eight different low-resource languages. The results show that HateMAML outperforms the state-of-the-art baselines by more than 3% in the cross-domain multilingual transfer setting. We also conduct ablation studies to analyze the characteristics of HateMAML.
Handling Bias in Toxic Speech Detection: A Survey
Feb 02, 2022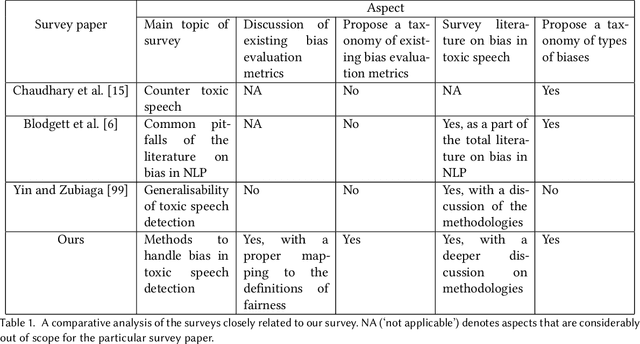
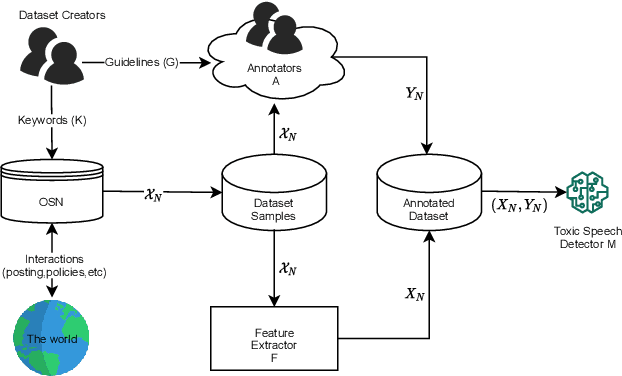
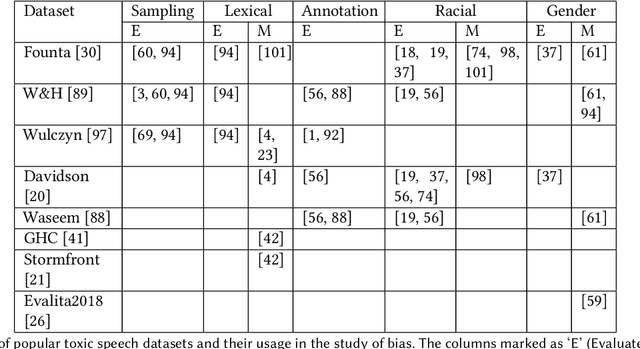
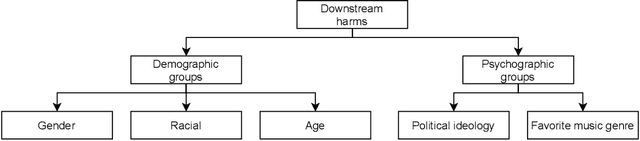
The massive growth of social media usage has witnessed a tsunami of online toxicity in teams of hate speech, abusive posts, cyberbullying, etc. Detecting online toxicity is challenging due to its inherent subjectivity. Factors such as the context of the speech, geography, socio-political climate, and background of the producers and consumers of the posts play a crucial role in determining if the content can be flagged as toxic. Adoption of automated toxicity detection models in production can lead to a sidelining of the various demographic and psychographic groups they aim to help in the first place. It has piqued researchers' interest in examining unintended biases and their mitigation. Due to the nascent and multi-faceted nature of the work, complete literature is chaotic in its terminologies, techniques, and findings. In this paper, we put together a systematic study to discuss the limitations and challenges of existing methods. We start by developing a taxonomy for categorising various unintended biases and a suite of evaluation metrics proposed to quantify such biases. We take a closer look at each proposed method for evaluating and mitigating bias in toxic speech detection. To examine the limitations of existing methods, we also conduct a case study to introduce the concept of bias shift due to knowledge-based bias mitigation methods. The survey concludes with an overview of the critical challenges, research gaps and future directions. While reducing toxicity on online platforms continues to be an active area of research, a systematic study of various biases and their mitigation strategies will help the research community produce robust and fair models.