 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Bias in Toxic Speech Detection: A Survey
Paper and Code
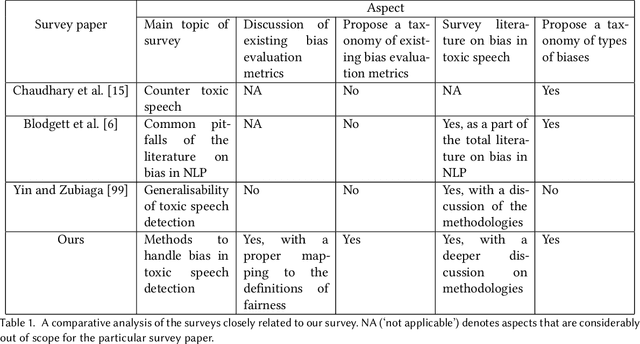
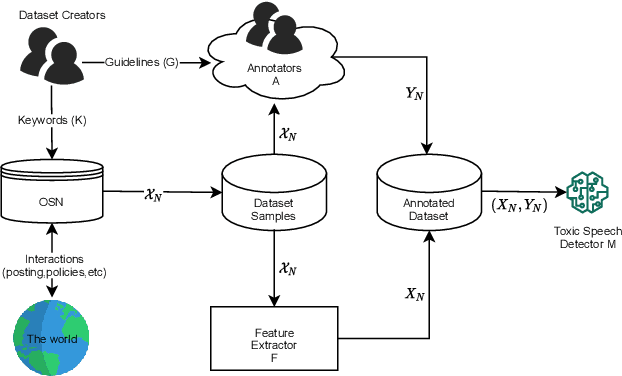
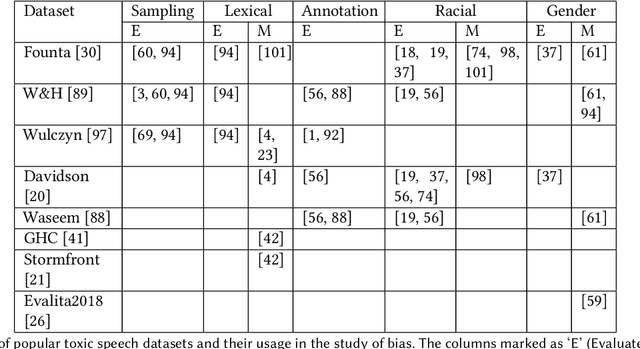
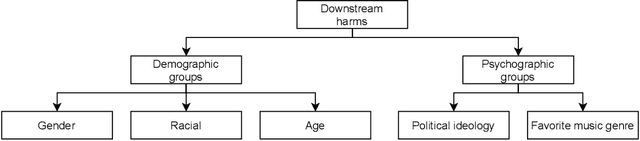
The massive growth of social media usage has witnessed a tsunami of online toxicity in teams of hate speech, abusive posts, cyberbullying, etc. Detecting online toxicity is challenging due to its inherent subjectivity. Factors such as the context of the speech, geography, socio-political climate, and background of the producers and consumers of the posts play a crucial role in determining if the content can be flagged as toxic. Adoption of automated toxicity detection models in production can lead to a sidelining of the various demographic and psychographic groups they aim to help in the first place. It has piqued researchers' interest in examining unintended biases and their mitigation. Due to the nascent and multi-faceted nature of the work, complete literature is chaotic in its terminologies, techniques, and findings. In this paper, we put together a systematic study to discuss the limitations and challenges of existing methods. We start by developing a taxonomy for categorising various unintended biases and a suite of evaluation metrics proposed to quantify such biases. We take a closer look at each proposed method for evaluating and mitigating bias in toxic speech detection. To examine the limitations of existing methods, we also conduct a case study to introduce the concept of bias shift due to knowledge-based bias mitigation methods. The survey concludes with an overview of the critical challenges, research gaps and future directions. While reducing toxicity on online platforms continues to be an active area of research, a systematic study of various biases and their mitigation strategies will help the research community produce robust and fair models.