 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListening Between the Lines: Decoding Podcast Narratives with Language Modeling
Nov 07, 2025



Podcasts have become a central arena for shaping public opinion, making them a vital source for understanding contemporary discourse. Their typically unscripted, multi-themed, and conversational style offers a rich but complex form of data. To analyze how podcasts persuade and inform, we must examine their narrative structures -- specifically, the narrative frames they employ. The fluid and conversational nature of podcasts presents a significant challenge for automated analysis. We show that existing large language models, typically trained on more structured text such as news articles, struggle to capture the subtle cues that human listeners rely on to identify narrative frames. As a result, current approaches fall short of accurately analyzing podcast narratives at scale. To solve this, we develop and evaluate a fine-tuned BERT model that explicitly links narrative frames to specific entities mentioned in the conversation, effectively grounding the abstract frame in concrete details. Our approach then uses these granular frame labels and correlates them with high-level topics to reveal broader discourse trends. The primary contributions of this paper are: (i) a novel frame-labeling methodology that more closely aligns with human judgment for messy, conversational data, and (ii) a new analysis that uncovers the systematic relationship between what is being discussed (the topic) and how it is being presented (the frame), offering a more robust framework for studying influence in digital media.
QUENCH: Measuring the gap between Indic and Non-Indic Contextual General Reasoning in LLMs
Dec 16, 2024



The rise of large language models (LLMs) has created a need for advanced benchmarking systems beyond traditional setups. To this end, we introduce QUENCH, a novel text-based English Quizzing Benchmark manually curated and transcribed from YouTube quiz videos. QUENCH possesses masked entities and rationales for the LLMs to predict via generation. At the intersection of geographical context and common sense reasoning, QUENCH helps assess world knowledge and deduction capabilities of LLMs via a zero-shot, open-domain quizzing setup. We perform an extensive evaluation on 7 LLMs and 4 metrics, investigating the influence of model size, prompting style, geographical context, and gold-labeled rationale generation. The benchmarking concludes with an error analysis to which the LLMs are prone.
Information Anxiety in Large Language Models
Nov 16, 2024



Large Language Models (LLMs) have demonstrated strong performance as knowledge repositories, enabling models to understand user queries and generate accurate and context-aware responses. Extensive evaluation setups have corroborated the positive correlation between the retrieval capability of LLMs and the frequency of entities in their pretraining corpus. We take the investigation further by conducting a comprehensive analysis of the internal reasoning and retrieval mechanisms of LLMs. Our work focuses on three critical dimensions - the impact of entity popularity, the models' sensitivity to lexical variations in query formulation, and the progression of hidden state representations across LLM layers. Our preliminary findings reveal that popular questions facilitate early convergence of internal states toward the correct answer. However, as the popularity of a query increases, retrieved attributes across lexical variations become increasingly dissimilar and less accurate. Interestingly, we find that LLMs struggle to disentangle facts, grounded in distinct relations, from their parametric memory when dealing with highly popular subjects. Through a case study, we explore these latent strains within LLMs when processing highly popular queries, a phenomenon we term information anxiety. The emergence of information anxiety in LLMs underscores the adversarial injection in the form of linguistic variations and calls for a more holistic evaluation of frequently occurring entities.
Hate Personified: Investigating the role of LLMs in content moderation
Oct 03, 2024

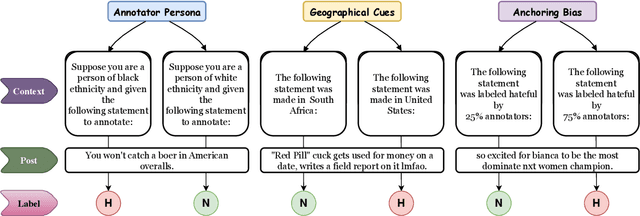
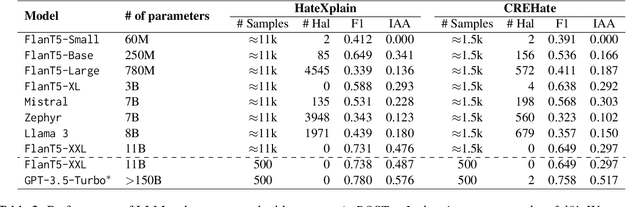
For subjective tasks such as hate detection, where people perceive hate differently, the Large Language Model's (LLM) ability to represent diverse groups is unclear. By including additional context in prompts, we comprehensively analyze LLM's sensitivity to geographical priming, persona attributes, and numerical information to assess how well the needs of various groups are reflected. Our findings on two LLMs, five languages, and six datasets reveal that mimicking persona-based attributes leads to annotation variability. Meanwhile, incorporating geographical signals leads to better regional alignment. We also find that the LLMs are sensitive to numerical anchors, indicating the ability to leverage community-based flagging efforts and exposure to adversaries. Our work provides preliminary guidelines and highlights the nuances of applying LLMs in culturally sensitive cases.
Tox-BART: Leveraging Toxicity Attributes for Explanation Generation of Implicit Hate Speech
Jun 06, 2024



Employing language models to generate explanations for an incoming implicit hate post is an active area of research. The explanation is intended to make explicit the underlying stereotype and aid content moderators. The training often combines top-k relevant knowledge graph (KG) tuples to provide world knowledge and improve performance on standard metrics. Interestingly, our study presents conflicting evidence for the role of the quality of KG tuples in generating implicit explanations. Consequently, simpler models incorporating external toxicity signals outperform KG-infused models. Compared to the KG-based setup, we observe a comparable performance for SBIC (LatentHatred) datasets with a performance variation of +0.44 (+0.49), +1.83 (-1.56), and -4.59 (+0.77) in BLEU, ROUGE-L, and BERTScore. Further human evaluation and error analysis reveal that our proposed setup produces more precise explanations than zero-shot GPT-3.5, highlighting the intricate nature of the task.
Probing Critical Learning Dynamics of PLMs for Hate Speech Detection
Feb 03, 2024Despite the widespread adoption, there is a lack of research into how various critical aspects of pretrained language models (PLMs) affect their performance in hate speech detection. Through five research questions, our findings and recommendations lay the groundwork for empirically investigating different aspects of PLMs' use in hate speech detection. We deep dive into comparing different pretrained models, evaluating their seed robustness, finetuning settings, and the impact of pretraining data collection time. Our analysis reveals early peaks for downstream tasks during pretraining, the limited benefit of employing a more recent pretraining corpus, and the significance of specific layers during finetuning. We further call into question the use of domain-specific models and highlight the need for dynamic datasets for benchmarking hate speech detection.
Overview of the HASOC Subtrack at FIRE 2023: Identification of Tokens Contributing to Explicit Hate in English by Span Detection
Nov 16, 2023As hate speech continues to proliferate on the web, it is becoming increasingly important to develop computational methods to mitigate it. Reactively, using black-box models to identify hateful content can perplex users as to why their posts were automatically flagged as hateful. On the other hand, proactive mitigation can be achieved by suggesting rephrasing before a post is made public. However, both mitigation techniques require information about which part of a post contains the hateful aspect, i.e., what spans within a text are responsible for conveying hate. Better detection of such spans can significantly reduce explicitly hateful content on the web. To further contribute to this research area, we organized HateNorm at HASOC-FIRE 2023, focusing on explicit span detection in English Tweets. A total of 12 teams participated in the competition, with the highest macro-F1 observed at 0.58.
Focal Inferential Infusion Coupled with Tractable Density Discrimination for Implicit Hate Speech Detection
Sep 21, 2023Although pre-trained large language models (PLMs) have achieved state-of-the-art on many NLP tasks, they lack understanding of subtle expressions of implicit hate speech. Such nuanced and implicit hate is often misclassified as non-hate. Various attempts have been made to enhance the detection of (implicit) hate content by augmenting external context or enforcing label separation via distance-based metrics. We combine these two approaches and introduce FiADD, a novel Focused Inferential Adaptive Density Discrimination framework. FiADD enhances the PLM finetuning pipeline by bringing the surface form of an implicit hate speech closer to its implied form while increasing the inter-cluster distance among various class labels. We test FiADD on three implicit hate datasets and observe significant improvement in the two-way and three-way hate classification tasks. We further experiment on the generalizability of FiADD on three other tasks, namely detecting sarcasm, irony, and stance, in which surface and implied forms differ, and observe similar performance improvement. We analyze the generated latent space to understand its evolution under FiADD, which corroborates the advantage of employing FiADD for implicit hate speech detection.
Revisiting Hate Speech Benchmarks: From Data Curation to System Deployment
Jun 15, 2023



Social media is awash with hateful content, much of which is often veiled with linguistic and topical diversity. The benchmark datasets used for hate speech detection do not account for such divagation as they are predominantly compiled using hate lexicons. However, capturing hate signals becomes challenging in neutrally-seeded malicious content. Thus, designing models and datasets that mimic the real-world variability of hate warrants further investigation. To this end, we present GOTHate, a large-scale code-mixed crowdsourced dataset of around 51k posts for hate speech detection from Twitter. GOTHate is neutrally seeded, encompassing different languages and topics. We conduct detailed comparisons of GOTHate with the existing hate speech datasets, highlighting its novelty. We benchmark it with 10 recent baselines. Our extensive empirical and benchmarking experiments suggest that GOTHate is hard to classify in a text-only setup. Thus, we investigate how adding endogenous signals enhances the hate speech detection task. We augment GOTHate with the user's timeline information and ego network, bringing the overall data source closer to the real-world setup for understanding hateful content. Our proposed solution HEN-mBERT is a modular, multilingual, mixture-of-experts model that enriches the linguistic subspace with latent endogenous signals from history, topology, and exemplars. HEN-mBERT transcends the best baseline by 2.5% and 5% in overall macro-F1 and hate class F1, respectively. Inspired by our experiments, in partnership with Wipro AI, we are developing a semi-automated pipeline to detect hateful content as a part of their mission to tackle online harm.
Proactively Reducing the Hate Intensity of Online Posts via Hate Speech Normalization
Jun 08, 2022
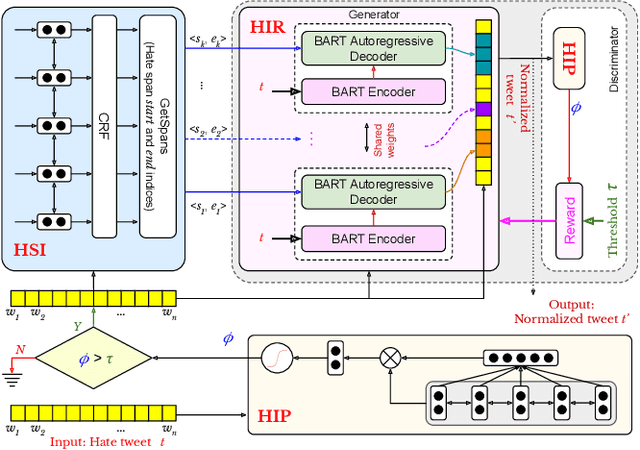
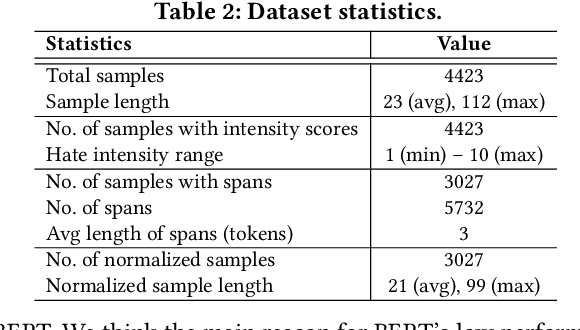
Curbing online hate speech has become the need of the hour; however, a blanket ban on such activities is infeasible for several geopolitical and cultural reasons. To reduce the severity of the problem, in this paper, we introduce a novel task, hate speech normalization, that aims to weaken the intensity of hatred exhibited by an online post. The intention of hate speech normalization is not to support hate but instead to provide the users with a stepping stone towards non-hate while giving online platforms more time to monitor any improvement in the user's behavior. To this end, we manually curated a parallel corpus - hate texts and their normalized counterparts (a normalized text is less hateful and more benign). We introduce NACL, a simple yet efficient hate speech normalization model that operates in three stages - first, it measures the hate intensity of the original sample; second, it identifies the hate span(s) within it; and finally, it reduces hate intensity by paraphrasing the hate spans. We perform extensive experiments to measure the efficacy of NACL via three-way evaluation (intrinsic, extrinsic, and human-study). We observe that NACL outperforms six baselines - NACL yields a score of 0.1365 RMSE for the intensity prediction, 0.622 F1-score in the span identification, and 82.27 BLEU and 80.05 perplexity for the normalized text generation. We further show the generalizability of NACL across other platforms (Reddit, Facebook, Gab). An interactive prototype of NACL was put together for the user study. Further, the tool is being deployed in a real-world setting at Wipro AI as a part of its mission to tackle harmful content on online platforms.