 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Controlling Model Behavior via Constitutions for Atomic Concept Edits
Jan 23, 2026We introduce a black-box interpretability framework that learns a verifiable constitution: a natural language summary of how changes to a prompt affect a model's specific behavior, such as its alignment, correctness, or adherence to constraints. Our method leverages atomic concept edits (ACEs), which are targeted operations that add, remove, or replace an interpretable concept in the input prompt. By systematically applying ACEs and observing the resulting effects on model behavior across various tasks, our framework learns a causal mapping from edits to predictable outcomes. This learned constitution provides deep, generalizable insights into the model. Empirically, we validate our approach across diverse tasks, including mathematical reasoning and text-to-image alignment, for controlling and understanding model behavior. We found that for text-to-image generation, GPT-Image tends to focus on grammatical adherence, while Imagen 4 prioritizes atmospheric coherence. In mathematical reasoning, distractor variables confuse GPT-5 but leave Gemini 2.5 models and o4-mini largely unaffected. Moreover, our results show that the learned constitutions are highly effective for controlling model behavior, achieving an average of 1.86 times boost in success rate over methods that do not use constitutions.
Multilingual Test-Time Scaling via Initial Thought Transfer
May 21, 2025



Test-time scaling has emerged as a widely adopted inference-time strategy for boosting reasoning performance. However, its effectiveness has been studied almost exclusively in English, leaving its behavior in other languages largely unexplored. We present the first systematic study of test-time scaling in multilingual settings, evaluating DeepSeek-R1-Distill-LLama-8B and DeepSeek-R1-Distill-Qwen-7B across both high- and low-resource Latin-script languages. Our findings reveal that the relative gains from test-time scaling vary significantly across languages. Additionally, models frequently switch to English mid-reasoning, even when operating under strictly monolingual prompts. We further show that low-resource languages not only produce initial reasoning thoughts that differ significantly from English but also have lower internal consistency across generations in their early reasoning. Building on our findings, we introduce MITT (Multilingual Initial Thought Transfer), an unsupervised and lightweight reasoning prefix-tuning approach that transfers high-resource reasoning prefixes to enhance test-time scaling across all languages, addressing inconsistencies in multilingual reasoning performance. MITT significantly boosts DeepSeek-R1-Distill-Qwen-7B's reasoning performance, especially for underrepresented languages.
Can LLMs reason over extended multilingual contexts? Towards long-context evaluation beyond retrieval and haystacks
Apr 17, 2025

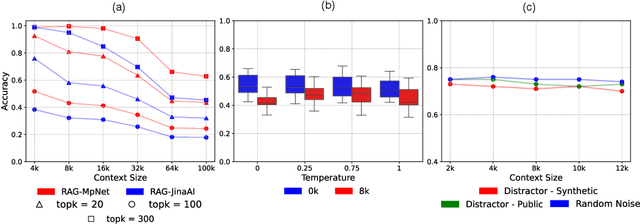
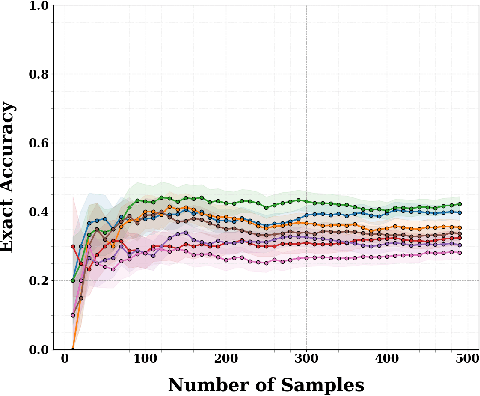
Existing multilingual long-context benchmarks, often based on the popular needle-in-a-haystack test, primarily evaluate a model's ability to locate specific information buried within irrelevant texts. However, such a retrieval-centric approach is myopic and inherently limited, as successful recall alone does not indicate a model's capacity to reason over extended contexts. Moreover, these benchmarks are susceptible to data leakage, short-circuiting, and risk making the evaluation a priori identifiable. To address these limitations, we introduce MLRBench, a new synthetic benchmark for multilingual long-context reasoning. Unlike existing benchmarks, MLRBench goes beyond surface-level retrieval by including tasks that assess multi-hop inference, aggregation, and epistemic reasoning. Spanning seven languages, MLRBench is designed to be parallel, resistant to leakage, and scalable to arbitrary context lengths. Our extensive experiments with an open-weight large language model (LLM) reveal a pronounced gap between high- and low-resource languages, particularly for tasks requiring the model to aggregate multiple facts or predict the absence of information. We also find that, in multilingual settings, LLMs effectively utilize less than 30% of their claimed context length. Although off-the-shelf Retrieval Augmented Generation helps alleviate this to a certain extent, it does not solve the long-context problem. We open-source MLRBench to enable future research in improved evaluation and training of multilingual LLMs.
Information Anxiety in Large Language Models
Nov 16, 2024



Large Language Models (LLMs) have demonstrated strong performance as knowledge repositories, enabling models to understand user queries and generate accurate and context-aware responses. Extensive evaluation setups have corroborated the positive correlation between the retrieval capability of LLMs and the frequency of entities in their pretraining corpus. We take the investigation further by conducting a comprehensive analysis of the internal reasoning and retrieval mechanisms of LLMs. Our work focuses on three critical dimensions - the impact of entity popularity, the models' sensitivity to lexical variations in query formulation, and the progression of hidden state representations across LLM layers. Our preliminary findings reveal that popular questions facilitate early convergence of internal states toward the correct answer. However, as the popularity of a query increases, retrieved attributes across lexical variations become increasingly dissimilar and less accurate. Interestingly, we find that LLMs struggle to disentangle facts, grounded in distinct relations, from their parametric memory when dealing with highly popular subjects. Through a case study, we explore these latent strains within LLMs when processing highly popular queries, a phenomenon we term information anxiety. The emergence of information anxiety in LLMs underscores the adversarial injection in the form of linguistic variations and calls for a more holistic evaluation of frequently occurring entities.
Can LLMs replace Neil deGrasse Tyson? Evaluating the Reliability of LLMs as Science Communicators
Sep 21, 2024Large Language Models (LLMs) and AI assistants driven by these models are experiencing exponential growth in usage among both expert and amateur users. In this work, we focus on evaluating the reliability of current LLMs as science communicators. Unlike existing benchmarks, our approach emphasizes assessing these models on scientific questionanswering tasks that require a nuanced understanding and awareness of answerability. We introduce a novel dataset, SCiPS-QA, comprising 742 Yes/No queries embedded in complex scientific concepts, along with a benchmarking suite that evaluates LLMs for correctness and consistency across various criteria. We benchmark three proprietary LLMs from the OpenAI GPT family and 13 open-access LLMs from the Meta Llama-2, Llama-3, and Mistral families. While most open-access models significantly underperform compared to GPT-4 Turbo, our experiments identify Llama-3-70B as a strong competitor, often surpassing GPT-4 Turbo in various evaluation aspects. We also find that even the GPT models exhibit a general incompetence in reliably verifying LLM responses. Moreover, we observe an alarming trend where human evaluators are deceived by incorrect responses from GPT-4 Turbo.
Multilingual Needle in a Haystack: Investigating Long-Context Behavior of Multilingual Large Language Models
Aug 19, 2024While recent large language models (LLMs) demonstrate remarkable abilities in responding to queries in diverse languages, their ability to handle long multilingual contexts is unexplored. As such, a systematic evaluation of the long-context capabilities of LLMs in multilingual settings is crucial, specifically in the context of information retrieval. To address this gap, we introduce the MultiLingual Needle-in-a-Haystack (MLNeedle) test, designed to assess a model's ability to retrieve relevant information (the needle) from a collection of multilingual distractor texts (the haystack). This test serves as an extension of the multilingual question-answering task, encompassing both monolingual and cross-lingual retrieval. We evaluate four state-of-the-art LLMs on MLNeedle. Our findings reveal that model performance can vary significantly with language and needle position. Specifically, we observe that model performance is the lowest when the needle is (i) in a language outside the English language family and (ii) located in the middle of the input context. Furthermore, although some models claim a context size of $8k$ tokens or greater, none demonstrate satisfactory cross-lingual retrieval performance as the context length increases. Our analysis provides key insights into the long-context behavior of LLMs in multilingual settings to guide future evaluation protocols. To our knowledge, this is the first study to investigate the multilingual long-context behavior of LLMs.