 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGONITE: Iterative Retrieval on Induced Databases and Verbalized RDF for Conversational QA over KGs with RAG
Dec 24, 2024



Conversational question answering (ConvQA) is a convenient means of searching over RDF knowledge graphs (KGs), where a prevalent approach is to translate natural language questions to SPARQL queries. However, SPARQL has certain shortcomings: (i) it is brittle for complex intents and conversational questions, and (ii) it is not suitable for more abstract needs. Instead, we propose a novel two-pronged system where we fuse: (i) SQL-query results over a database automatically derived from the KG, and (ii) text-search results over verbalizations of KG facts. Our pipeline supports iterative retrieval: when the results of any branch are found to be unsatisfactory, the system can automatically opt for further rounds. We put everything together in a retrieval augmented generation (RAG) setup, where an LLM generates a coherent response from accumulated search results. We demonstrate the superiority of our proposed system over several baselines on a knowledge graph of BMW automobiles.
Hate Personified: Investigating the role of LLMs in content moderation
Oct 03, 2024

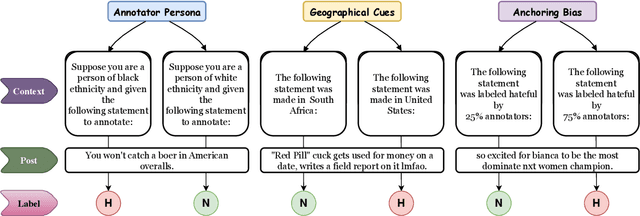
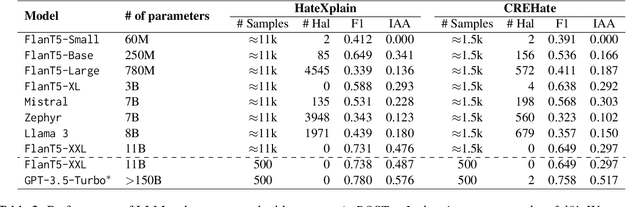
For subjective tasks such as hate detection, where people perceive hate differently, the Large Language Model's (LLM) ability to represent diverse groups is unclear. By including additional context in prompts, we comprehensively analyze LLM's sensitivity to geographical priming, persona attributes, and numerical information to assess how well the needs of various groups are reflected. Our findings on two LLMs, five languages, and six datasets reveal that mimicking persona-based attributes leads to annotation variability. Meanwhile, incorporating geographical signals leads to better regional alignment. We also find that the LLMs are sensitive to numerical anchors, indicating the ability to leverage community-based flagging efforts and exposure to adversaries. Our work provides preliminary guidelines and highlights the nuances of applying LLMs in culturally sensitive cases.
Style-Specific Neurons for Steering LLMs in Text Style Transfer
Oct 01, 2024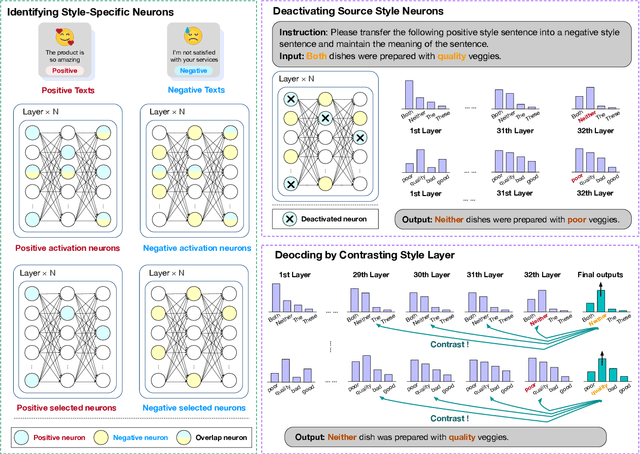
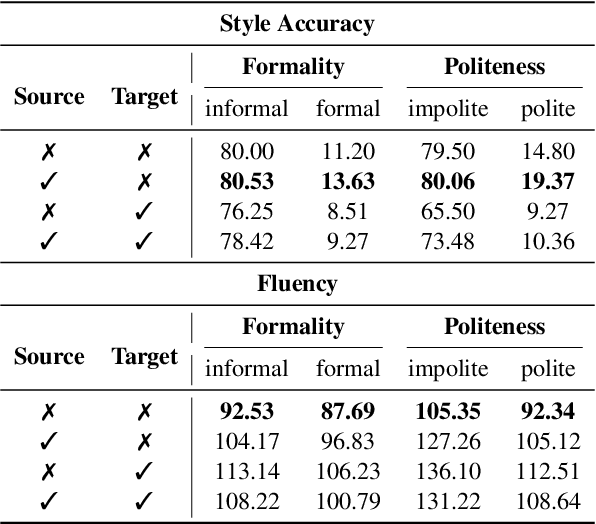
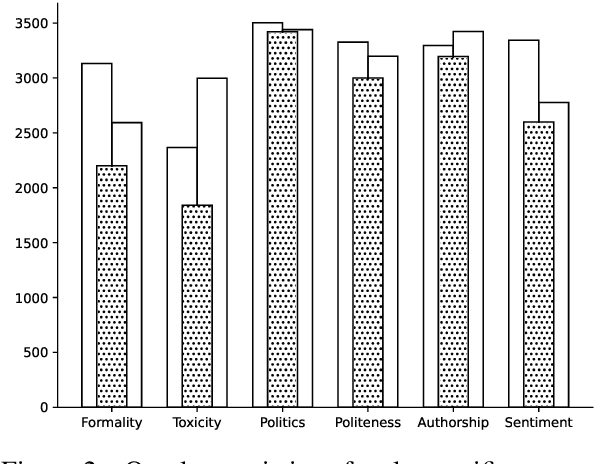
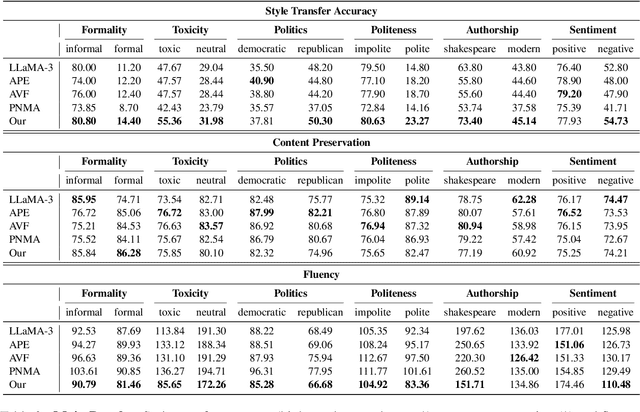
Text style transfer (TST) aims to modify the style of a text without altering its original meaning. Large language models (LLMs) demonstrate superior performance across multiple tasks, including TST. However, in zero-shot setups, they tend to directly copy a significant portion of the input text to the output without effectively changing its style. To enhance the stylistic variety and fluency of the text, we present sNeuron-TST, a novel approach for steering LLMs using style-specific neurons in TST. Specifically, we identify neurons associated with the source and target styles and deactivate source-style-only neurons to give target-style words a higher probability, aiming to enhance the stylistic diversity of the generated text. However, we find that this deactivation negatively impacts the fluency of the generated text, which we address by proposing an improved contrastive decoding method that accounts for rapid token probability shifts across layers caused by deactivated source-style neurons. Empirical experiments demonstrate the effectiveness of the proposed method on six benchmarks, encompassing formality, toxicity, politics, politeness, authorship, and sentiment.
Multilingual Word Embeddings for Low-Resource Languages using Anchors and a Chain of Related Languages
Nov 21, 2023



Very low-resource languages, having only a few million tokens worth of data, are not well-supported by multilingual NLP approaches due to poor quality cross-lingual word representations. Recent work showed that good cross-lingual performance can be achieved if a source language is related to the low-resource target language. However, not all language pairs are related. In this paper, we propose to build multilingual word embeddings (MWEs) via a novel language chain-based approach, that incorporates intermediate related languages to bridge the gap between the distant source and target. We build MWEs one language at a time by starting from the resource rich source and sequentially adding each language in the chain till we reach the target. We extend a semi-joint bilingual approach to multiple languages in order to eliminate the main weakness of previous works, i.e., independently trained monolingual embeddings, by anchoring the target language around the multilingual space. We evaluate our method on bilingual lexicon induction for 4 language families, involving 4 very low-resource (<5M tokens) and 4 moderately low-resource (<50M) target languages, showing improved performance in both categories. Additionally, our analysis reveals the importance of good quality embeddings for intermediate languages as well as the importance of leveraging anchor points from all languages in the multilingual space.
Extending Multilingual Machine Translation through Imitation Learning
Nov 14, 2023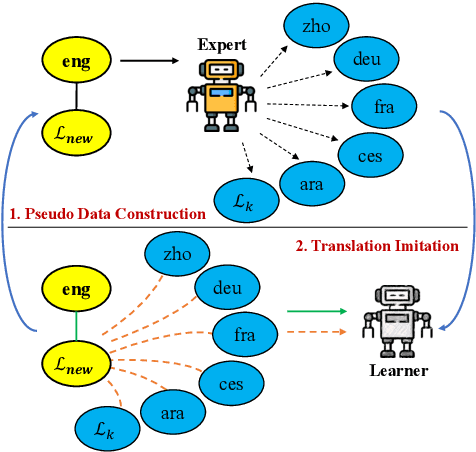
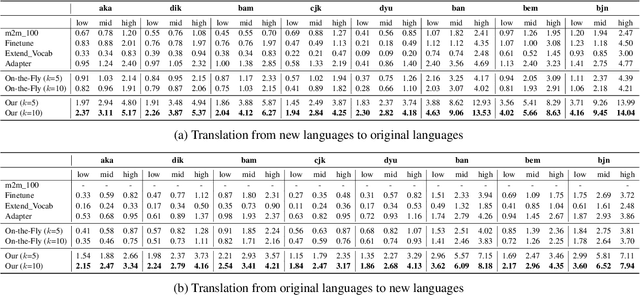
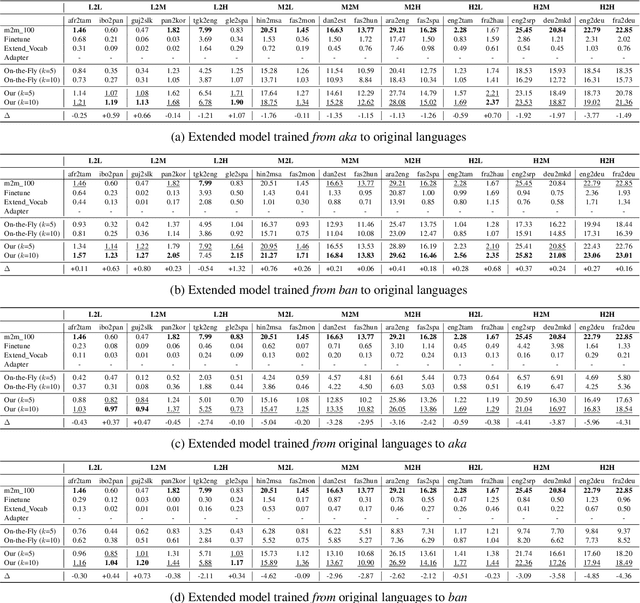
Despite the growing variety of languages supported by existing multilingual neural machine translation (MNMT) models, most of the world's languages are still being left behind. We aim to extend large-scale MNMT models to a new language, allowing for translation between the newly added and all of the already supported languages in a challenging scenario: using only a parallel corpus between the new language and English. Previous approaches, such as continued training on parallel data including the new language, suffer from catastrophic forgetting (i.e., performance on other languages is reduced). Our novel approach Imit-MNMT treats the task as an imitation learning process, which mimicks the behavior of an expert, a technique widely used in the computer vision area, but not well explored in NLP. More specifically, we construct a pseudo multi-parallel corpus of the new and the original languages by pivoting through English, and imitate the output distribution of the original MNMT model. Extensive experiments show that our approach significantly improves the translation performance between the new and the original languages, without severe catastrophic forgetting. We also demonstrate that our approach is capable of solving copy and off-target problems, which are two common issues existence in current large-scale MNMT models.
How to Solve Few-Shot Abusive Content Detection Using the Data We Actually Have
May 23, 2023Due to the broad range of social media platforms and their user groups, the requirements of abusive language detection systems are varied and ever-changing. Already a large set of annotated corpora with different properties and label sets were created, such as hate or misogyny detection, but the form and targets of abusive speech are constantly changing. Since, the annotation of new corpora is expensive, in this work we leverage datasets we already have, covering a wide range of tasks related to abusive language detection, in order to build models cheaply for a new target label set and/or language, using only a few training examples of the target domain. We propose a two-step approach: first we train our model in a multitask fashion. We then carry out few-shot adaptation to the target requirements. Our experiments show that by leveraging already existing datasets and only a few-shots of the target task the performance of models can be improved not only monolingually but across languages as well. Our analysis also shows that our models acquire a general understanding of abusive language, since they improve the prediction of labels which are present only in the target dataset. We also analyze the trade-off between specializing the already existing datasets to a given target setup for best performance and its negative effects on model adaptability.
Don't Forget Cheap Training Signals Before Building Unsupervised Bilingual Word Embeddings
May 31, 2022
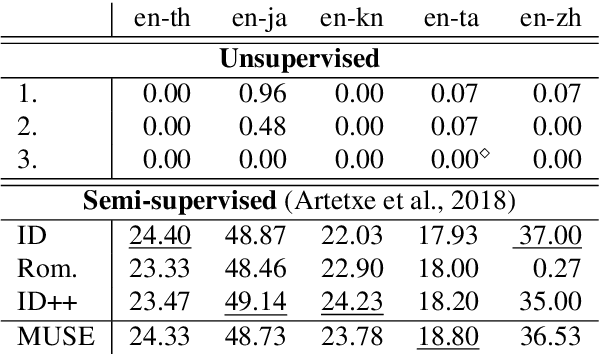

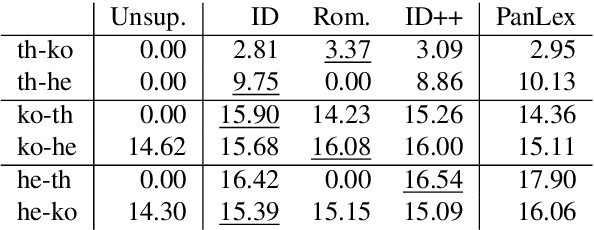
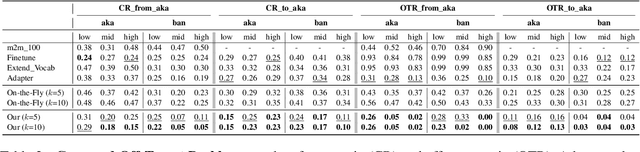
Bilingual Word Embeddings (BWEs) are one of the cornerstones of cross-lingual transfer of NLP models. They can be built using only monolingual corpora without supervision leading to numerous works focusing on unsupervised BWEs. However, most of the current approaches to build unsupervised BWEs do not compare their results with methods based on easy-to-access cross-lingual signals. In this paper, we argue that such signals should always be considered when developing unsupervised BWE methods. The two approaches we find most effective are: 1) using identical words as seed lexicons (which unsupervised approaches incorrectly assume are not available for orthographically distinct language pairs) and 2) combining such lexicons with pairs extracted by matching romanized versions of words with an edit distance threshold. We experiment on thirteen non-Latin languages (and English) and show that such cheap signals work well and that they outperform using more complex unsupervised methods on distant language pairs such as Chinese, Japanese, Kannada, Tamil, and Thai. In addition, they are even competitive with the use of high-quality lexicons in supervised approaches. Our results show that these training signals should not be neglected when building BWEs, even for distant languages.
Addressing the Challenges of Cross-Lingual Hate Speech Detection
Jan 15, 2022


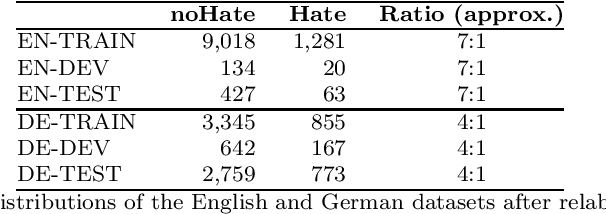
The goal of hate speech detection is to filter negative online content aiming at certain groups of people. Due to the easy accessibility of social media platforms it is crucial to protect everyone which requires building hate speech detection systems for a wide range of languages. However, the available labeled hate speech datasets are limited making it problematic to build systems for many languages. In this paper we focus on cross-lingual transfer learning to support hate speech detection in low-resource languages. We leverage cross-lingual word embeddings to train our neural network systems on the source language and apply it to the target language, which lacks labeled examples, and show that good performance can be achieved. We then incorporate unlabeled target language data for further model improvements by bootstrapping labels using an ensemble of different model architectures. Furthermore, we investigate the issue of label imbalance of hate speech datasets, since the high ratio of non-hate examples compared to hate examples often leads to low model performance. We test simple data undersampling and oversampling techniques and show their effectiveness.
The LMU Munich System for the WMT 2020 Unsupervised Machine Translation Shared Task
Oct 25, 2020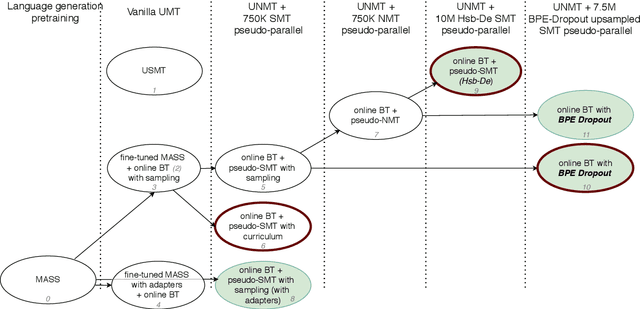
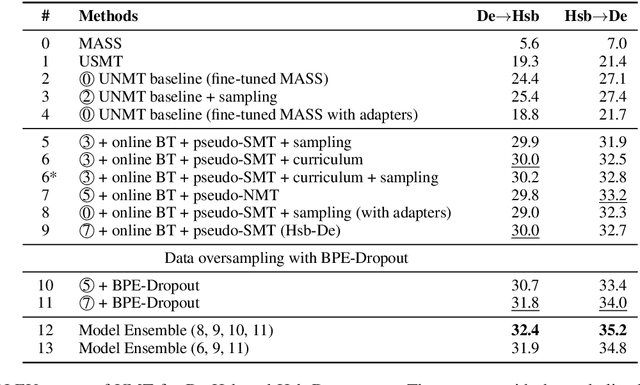
This paper describes the submission of LMU Munich to the WMT 2020 unsupervised shared task, in two language directions, German<->Upper Sorbian. Our core unsupervised neural machine translation (UNMT) system follows the strategy of Chronopoulou et al. (2020), using a monolingual pretrained language generation model (on German) and fine-tuning it on both German and Upper Sorbian, before initializing a UNMT model, which is trained with online backtranslation. Pseudo-parallel data obtained from an unsupervised statistical machine translation (USMT) system is used to fine-tune the UNMT model. We also apply BPE-Dropout to the low resource (Upper Sorbian) data to obtain a more robust system. We additionally experiment with residual adapters and find them useful in the Upper Sorbian->German direction. We explore sampling during backtranslation and curriculum learning to use SMT translations in a more principled way. Finally, we ensemble our best-performing systems and reach a BLEU score of 32.4 on German->Upper Sorbian and 35.2 on Upper Sorbian->German.
Anchor-based Bilingual Word Embeddings for Low-Resource Languages
Oct 23, 2020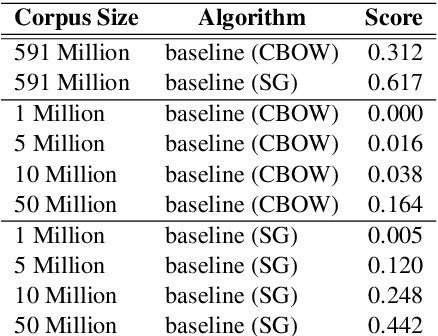
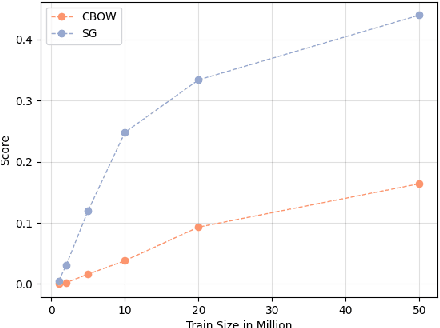
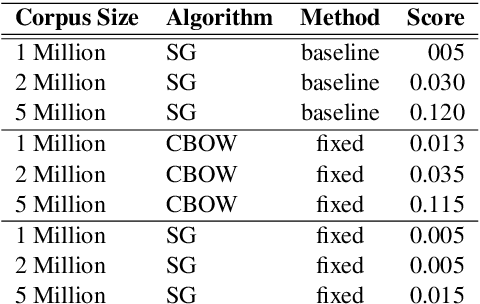
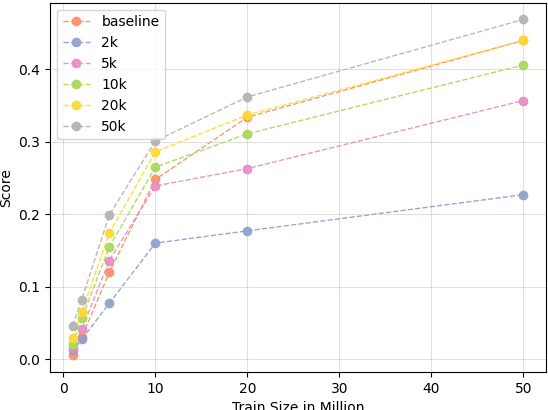
Bilingual word embeddings (BWEs) are useful for many cross-lingual applications, such as bilingual lexicon induction (BLI) and cross-lingual transfer learning. While recent methods have led to good quality BWEs for different language pairs using only weak bilingual signals, they still rely on an abundance of monolingual training data in both languages for their performance. This becomes a problem especially in the case of low resource languages where neither parallel bilingual corpora nor large monolingual training data are available. This paper proposes a new approach for building BWEs in which the vector space of the high resource source language is used as a starting point for training an embedding space for the low resource target language. By using the source vectors as anchors the vector spaces are automatically aligned. We evaluate the resulting BWEs on BLI and show the proposed method outperforms previous approaches in the low-resource setting by a large margin. We show strong results on the standard English-German test pair (using German to simulate low resource). We also show we can build useful BWEs for English-Hiligaynon, a true low-resource language, where previous approaches failed.