 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatches of Nonlinearity: Instruction Vectors in Large Language Models
Feb 08, 2026Despite the recent success of instruction-tuned language models and their ubiquitous usage, very little is known of how models process instructions internally. In this work, we address this gap from a mechanistic point of view by investigating how instruction-specific representations are constructed and utilized in different stages of post-training: Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO). Via causal mediation, we identify that instruction representation is fairly localized in models. These representations, which we call Instruction Vectors (IVs), demonstrate a curious juxtaposition of linear separability along with non-linear causal interaction, broadly questioning the scope of the linear representation hypothesis commonplace in mechanistic interpretability. To disentangle the non-linear causal interaction, we propose a novel method to localize information processing in language models that is free from the implicit linear assumptions of patching-based techniques. We find that, conditioned on the task representations formed in the early layers, different information pathways are selected in the later layers to solve that task, i.e., IVs act as circuit selectors.
The Inherent Limits of Pretrained LLMs: The Unexpected Convergence of Instruction Tuning and In-Context Learning Capabilities
Jan 15, 2025Large Language Models (LLMs), trained on extensive web-scale corpora, have demonstrated remarkable abilities across diverse tasks, especially as they are scaled up. Nevertheless, even state-of-the-art models struggle in certain cases, sometimes failing at problems solvable by young children, indicating that traditional notions of task complexity are insufficient for explaining LLM capabilities. However, exploring LLM capabilities is complicated by the fact that most widely-used models are also "instruction-tuned" to respond appropriately to prompts. With the goal of disentangling the factors influencing LLM performance, we investigate whether instruction-tuned models possess fundamentally different capabilities from base models that are prompted using in-context examples. Through extensive experiments across various model families, scales and task types, which included instruction tuning 90 different LLMs, we demonstrate that the performance of instruction-tuned models is significantly correlated with the in-context performance of their base counterparts. By clarifying what instruction-tuning contributes, we extend prior research into in-context learning, which suggests that base models use priors from pretraining data to solve tasks. Specifically, we extend this understanding to instruction-tuned models, suggesting that their pretraining data similarly sets a limiting boundary on the tasks they can solve, with the added influence of the instruction-tuning dataset.
Are Emergent Abilities in Large Language Models just In-Context Learning?
Sep 04, 2023Large language models have exhibited emergent abilities, demonstrating exceptional performance across diverse tasks for which they were not explicitly trained, including those that require complex reasoning abilities. The emergence of such abilities carries profound implications for the future direction of research in NLP, especially as the deployment of such models becomes more prevalent. However, one key challenge is that the evaluation of these abilities is often confounded by competencies that arise in models through alternative prompting techniques, such as in-context learning and instruction following, which also emerge as the models are scaled up. In this study, we provide the first comprehensive examination of these emergent abilities while accounting for various potentially biasing factors that can influence the evaluation of models. We conduct rigorous tests on a set of 18 models, encompassing a parameter range from 60 million to 175 billion parameters, across a comprehensive set of 22 tasks. Through an extensive series of over 1,000 experiments, we provide compelling evidence that emergent abilities can primarily be ascribed to in-context learning. We find no evidence for the emergence of reasoning abilities, thus providing valuable insights into the underlying mechanisms driving the observed abilities and thus alleviating safety concerns regarding their use.
Effective Cross-Task Transfer Learning for Explainable Natural Language Inference with T5
Oct 31, 2022We compare sequential fine-tuning with a model for multi-task learning in the context where we are interested in boosting performance on two tasks, one of which depends on the other. We test these models on the FigLang2022 shared task which requires participants to predict language inference labels on figurative language along with corresponding textual explanations of the inference predictions. Our results show that while sequential multi-task learning can be tuned to be good at the first of two target tasks, it performs less well on the second and additionally struggles with overfitting. Our findings show that simple sequential fine-tuning of text-to-text models is an extraordinarily powerful method for cross-task knowledge transfer while simultaneously predicting multiple interdependent targets. So much so, that our best model achieved the (tied) highest score on the task.
Addressing the Challenges of Cross-Lingual Hate Speech Detection
Jan 15, 2022


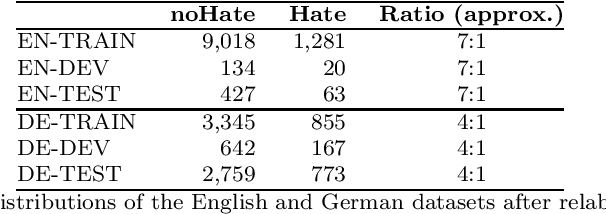
The goal of hate speech detection is to filter negative online content aiming at certain groups of people. Due to the easy accessibility of social media platforms it is crucial to protect everyone which requires building hate speech detection systems for a wide range of languages. However, the available labeled hate speech datasets are limited making it problematic to build systems for many languages. In this paper we focus on cross-lingual transfer learning to support hate speech detection in low-resource languages. We leverage cross-lingual word embeddings to train our neural network systems on the source language and apply it to the target language, which lacks labeled examples, and show that good performance can be achieved. We then incorporate unlabeled target language data for further model improvements by bootstrapping labels using an ensemble of different model architectures. Furthermore, we investigate the issue of label imbalance of hate speech datasets, since the high ratio of non-hate examples compared to hate examples often leads to low model performance. We test simple data undersampling and oversampling techniques and show their effectiveness.