 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing the Challenges of Cross-Lingual Hate Speech Detection
Paper and Code



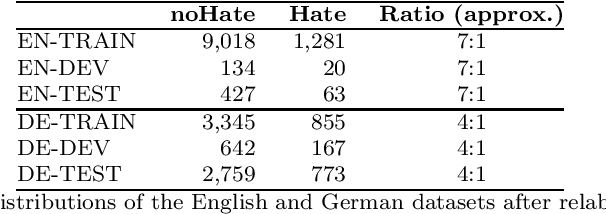
The goal of hate speech detection is to filter negative online content aiming at certain groups of people. Due to the easy accessibility of social media platforms it is crucial to protect everyone which requires building hate speech detection systems for a wide range of languages. However, the available labeled hate speech datasets are limited making it problematic to build systems for many languages. In this paper we focus on cross-lingual transfer learning to support hate speech detection in low-resource languages. We leverage cross-lingual word embeddings to train our neural network systems on the source language and apply it to the target language, which lacks labeled examples, and show that good performance can be achieved. We then incorporate unlabeled target language data for further model improvements by bootstrapping labels using an ensemble of different model architectures. Furthermore, we investigate the issue of label imbalance of hate speech datasets, since the high ratio of non-hate examples compared to hate examples often leads to low model performance. We test simple data undersampling and oversampling techniques and show their effectiveness.