 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Family Adapters for Multilingual Neural Machine Translation
Sep 30, 2022
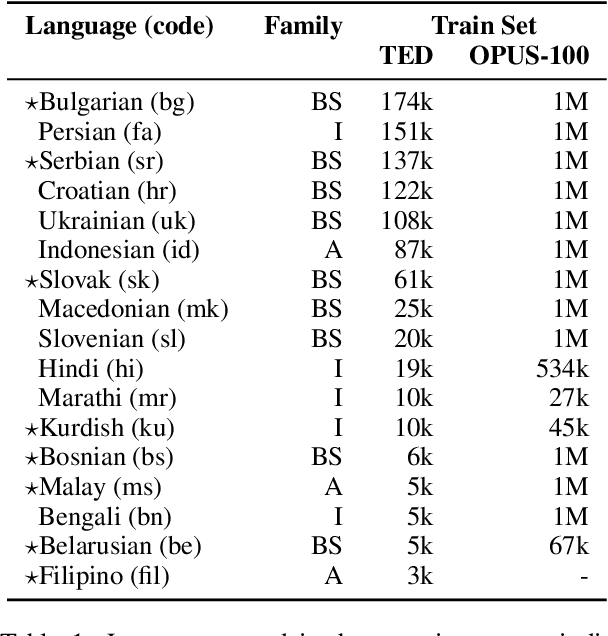
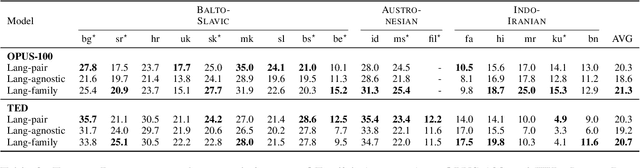
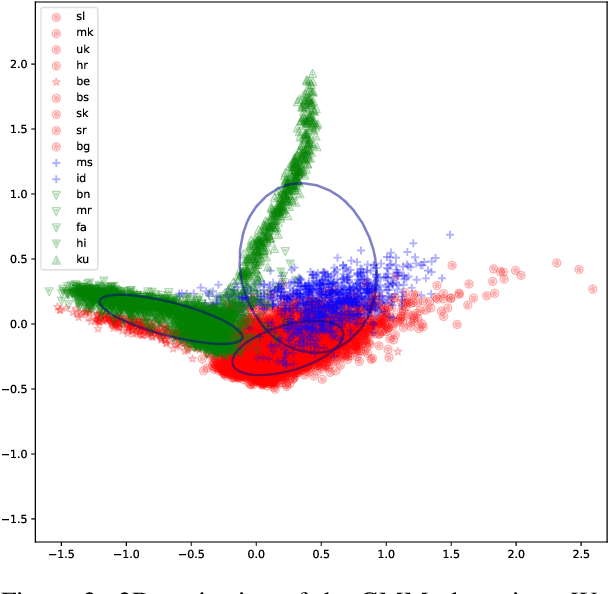
Massively multilingual models pretrained on abundant corpora with self-supervision achieve state-of-the-art results in a wide range of natural language processing tasks. In machine translation, multilingual pretrained models are often fine-tuned on parallel data from one or multiple language pairs. Multilingual fine-tuning improves performance on medium- and low-resource languages but requires modifying the entire model and can be prohibitively expensive. Training a new set of adapters on each language pair or training a single set of adapters on all language pairs while keeping the pretrained model's parameters frozen has been proposed as a parameter-efficient alternative. However, the former do not permit any sharing between languages, while the latter share parameters for all languages and have to deal with negative interference. In this paper, we propose training language-family adapters on top of a pretrained multilingual model to facilitate cross-lingual transfer. Our model consistently outperforms other adapter-based approaches. We also demonstrate that language-family adapters provide an effective method to translate to languages unseen during pretraining.
Improving the Lexical Ability of Pretrained Language Models for Unsupervised Neural Machine Translation
Apr 14, 2021


Successful methods for unsupervised neural machine translation (UNMT) employ crosslingual pretraining via self-supervision, often in the form of a masked language modeling or a sequence generation task, which requires the model to align the lexical- and high-level representations of the two languages. While cross-lingual pretraining works for similar languages with abundant corpora, it performs poorly in low-resource and distant languages. Previous research has shown that this is because the representations are not sufficiently aligned. In this paper, we enhance the bilingual masked language model pretraining with lexical-level information by using type-level cross-lingual subword embeddings. Empirical results demonstrate improved performance both on UNMT (up to 4.5 BLEU) and bilingual lexicon induction using our method compared to a UNMT baseline.
The LMU Munich System for the WMT 2020 Unsupervised Machine Translation Shared Task
Oct 25, 2020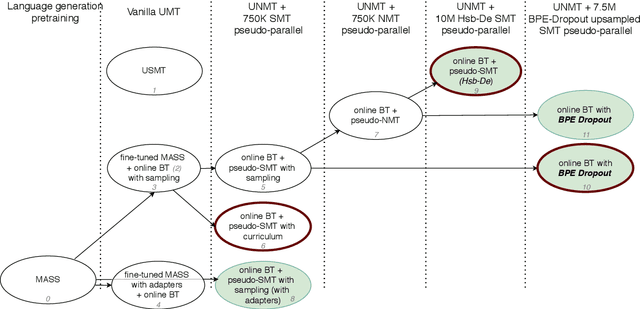
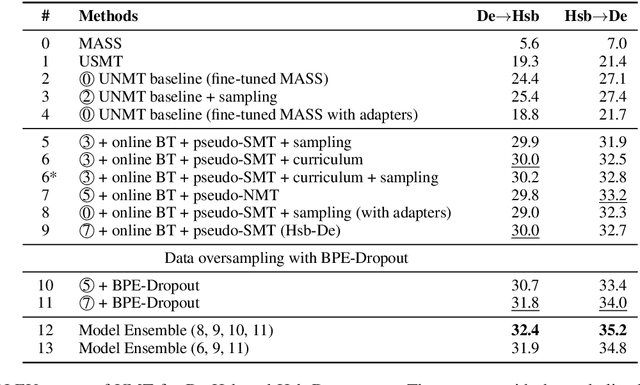
This paper describes the submission of LMU Munich to the WMT 2020 unsupervised shared task, in two language directions, German<->Upper Sorbian. Our core unsupervised neural machine translation (UNMT) system follows the strategy of Chronopoulou et al. (2020), using a monolingual pretrained language generation model (on German) and fine-tuning it on both German and Upper Sorbian, before initializing a UNMT model, which is trained with online backtranslation. Pseudo-parallel data obtained from an unsupervised statistical machine translation (USMT) system is used to fine-tune the UNMT model. We also apply BPE-Dropout to the low resource (Upper Sorbian) data to obtain a more robust system. We additionally experiment with residual adapters and find them useful in the Upper Sorbian->German direction. We explore sampling during backtranslation and curriculum learning to use SMT translations in a more principled way. Finally, we ensemble our best-performing systems and reach a BLEU score of 32.4 on German->Upper Sorbian and 35.2 on Upper Sorbian->German.
Reusing a Pretrained Language Model on Languages with Limited Corpora for Unsupervised NMT
Oct 06, 2020
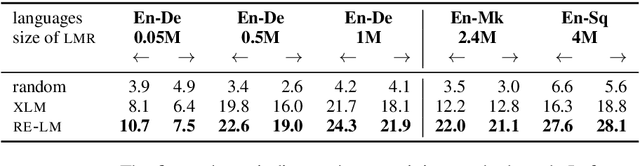

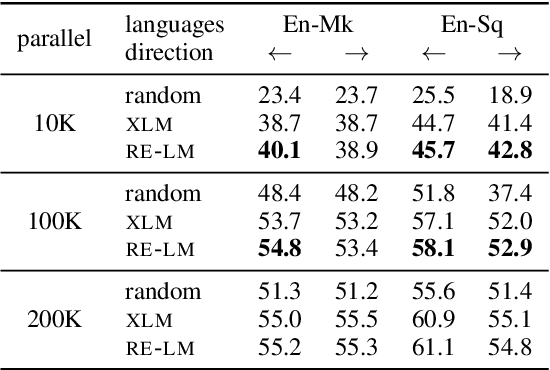
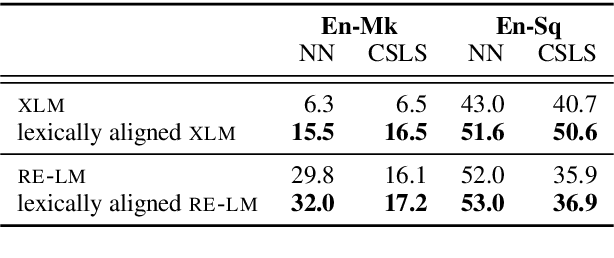
Using a language model (LM) pretrained on two languages with large monolingual data in order to initialize an unsupervised neural machine translation (UNMT) system yields state-of-the-art results. When limited data is available for one language, however, this method leads to poor translations. We present an effective approach that reuses an LM that is pretrained only on the high-resource language. The monolingual LM is fine-tuned on both languages and is then used to initialize a UNMT model. To reuse the pretrained LM, we have to modify its predefined vocabulary, to account for the new language. We therefore propose a novel vocabulary extension method. Our approach, RE-LM, outperforms a competitive cross-lingual pretraining model (XLM) in English-Macedonian (En-Mk) and English-Albanian (En-Sq), yielding more than +8.3 BLEU points for all four translation directions.
Addressing Zero-Resource Domains Using Document-Level Context in Neural Machine Translation
Apr 30, 2020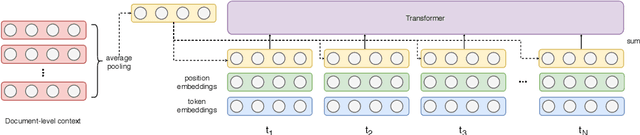


Achieving satisfying performance in machine translation on domains for which there is no training data is challenging. Traditional domain adaptation is not suitable for addressing such zero-resource domains because it relies on in-domain parallel data. We show that document-level context can be used to capture domain generalities when in-domain parallel data is not available. We present two document-level Transformer models which are capable of using large context sizes and we compare these models against strong Transformer baselines. We obtain improvements for the two zero-resource domains we study. We additionally present experiments showing the usefulness of large context when modeling multiple domains at once.