Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Zero-Resource Domains Using Document-Level Context in Neural Machine Translation
Paper and Code
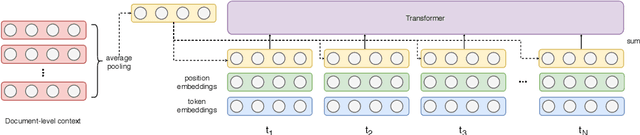


Achieving satisfying performance in machine translation on domains for which there is no training data is challenging. Traditional domain adaptation is not suitable for addressing such zero-resource domains because it relies on in-domain parallel data. We show that document-level context can be used to capture domain generalities when in-domain parallel data is not available. We present two document-level Transformer models which are capable of using large context sizes and we compare these models against strong Transformer baselines. We obtain improvements for the two zero-resource domains we study. We additionally present experiments showing the usefulness of large context when modeling multiple domains at once.
View paper on