 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Family Adapters for Multilingual Neural Machine Translation
Paper and Code

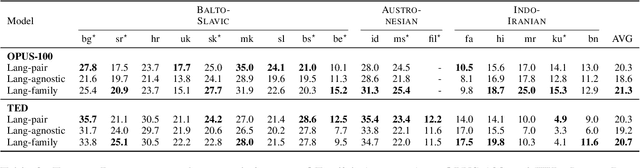
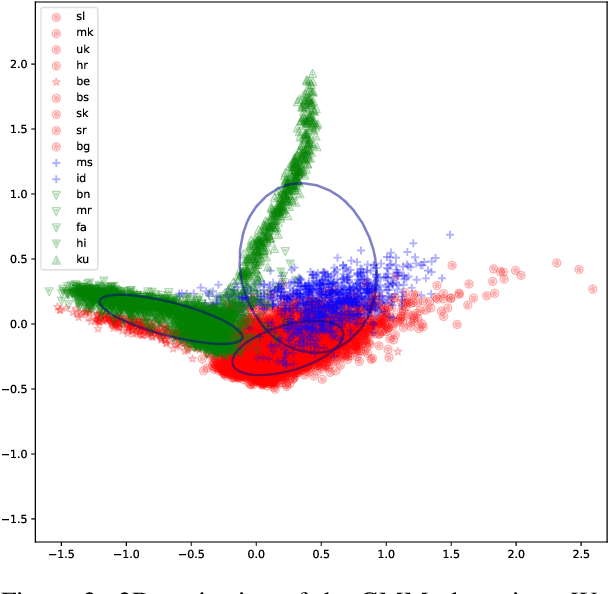
Massively multilingual models pretrained on abundant corpora with self-supervision achieve state-of-the-art results in a wide range of natural language processing tasks. In machine translation, multilingual pretrained models are often fine-tuned on parallel data from one or multiple language pairs. Multilingual fine-tuning improves performance on medium- and low-resource languages but requires modifying the entire model and can be prohibitively expensive. Training a new set of adapters on each language pair or training a single set of adapters on all language pairs while keeping the pretrained model's parameters frozen has been proposed as a parameter-efficient alternative. However, the former do not permit any sharing between languages, while the latter share parameters for all languages and have to deal with negative interference. In this paper, we propose training language-family adapters on top of a pretrained multilingual model to facilitate cross-lingual transfer. Our model consistently outperforms other adapter-based approaches. We also demonstrate that language-family adapters provide an effective method to translate to languages unseen during pretraining.