 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchor-based Bilingual Word Embeddings for Low-Resource Languages
Paper and Code
Oct 23, 2020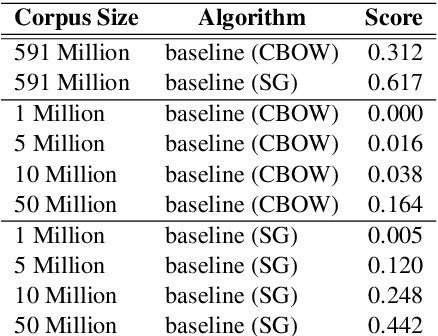
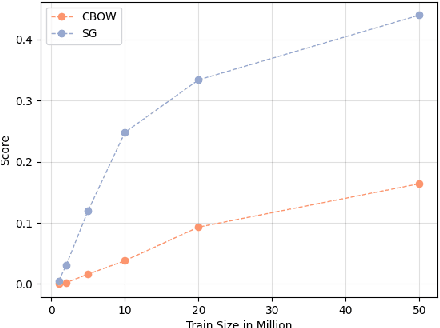
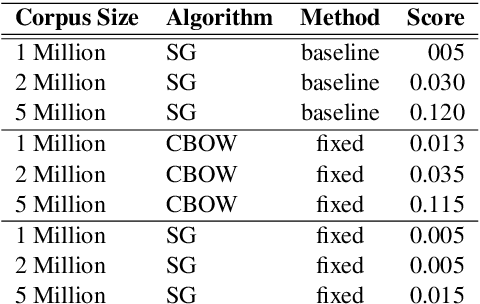
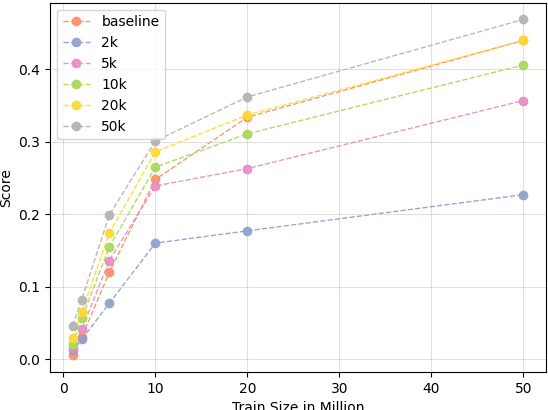
Bilingual word embeddings (BWEs) are useful for many cross-lingual applications, such as bilingual lexicon induction (BLI) and cross-lingual transfer learning. While recent methods have led to good quality BWEs for different language pairs using only weak bilingual signals, they still rely on an abundance of monolingual training data in both languages for their performance. This becomes a problem especially in the case of low resource languages where neither parallel bilingual corpora nor large monolingual training data are available. This paper proposes a new approach for building BWEs in which the vector space of the high resource source language is used as a starting point for training an embedding space for the low resource target language. By using the source vectors as anchors the vector spaces are automatically aligned. We evaluate the resulting BWEs on BLI and show the proposed method outperforms previous approaches in the low-resource setting by a large margin. We show strong results on the standard English-German test pair (using German to simulate low resource). We also show we can build useful BWEs for English-Hiligaynon, a true low-resource language, where previous approaches failed.