 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Hate: Differentiating Uncivil and Intolerant Speech in Multimodal Content Moderation
Mar 24, 2026Current multimodal toxicity benchmarks typically use a single binary hatefulness label. This coarse approach conflates two fundamentally different characteristics of expression: tone and content. Drawing on communication science theory, we introduce a fine-grained annotation scheme that distinguishes two separable dimensions: incivility (rude or dismissive tone) and intolerance (content that attacks pluralism and targets groups or identities) and apply it to 2,030 memes from the Hateful Memes dataset. We evaluate different vision-language models under coarse-label training, transfer learning across label schemes and a joint learning approach that combines the coarse hatefulness label with our fine-grained annotations. Our results show that fine-grained annotations complement existing coarse labels and, when used jointly, improve overall model performance. Moreover, models trained with the fine-grained scheme exhibit more balanced moderation-relevant error profiles and are less prone to under-detection of harmful content than models trained on hatefulness labels alone (FNR-FPR, the difference between false negative and false positive rates: 0.74 to 0.42 for LLaVA-1.6-Mistral-7B; 0.54 to 0.28 for Qwen2.5-VL-7B). This work contributes to data-centric approaches in content moderation by improving the reliability and accuracy of moderation systems through enhanced data quality. Overall, combining both coarse and fine-grained labels provides a practical route to more reliable multimodal moderation.
From Judgement's Premises Towards Key Points
Dec 23, 2022
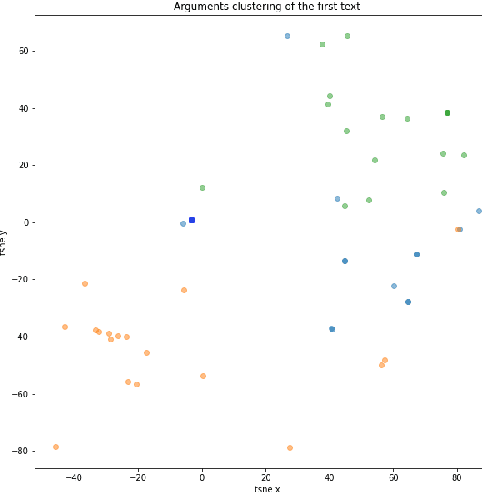

Key Point Analysis(KPA) is a relatively new task in NLP that combines summarization and classification by extracting argumentative key points (KPs) for a topic from a collection of texts and categorizing their closeness to the different arguments. In our work, we focus on the legal domain and develop methods that identify and extract KPs from premises derived from texts of judgments. The first method is an adaptation to an existing state-of-the-art method, and the two others are new methods that we developed from scratch. We present our methods and examples of their outputs, as well a comparison between them. The full evaluation of our results is done in the matching task -- match between the generated KPs to arguments (premises).
Structuring User-Generated Content on Social Media with Multimodal Aspect-Based Sentiment Analysis
Oct 27, 2022People post their opinions and experiences on social media, yielding rich databases of end users' sentiments. This paper shows to what extent machine learning can analyze and structure these databases. An automated data analysis pipeline is deployed to provide insights into user-generated content for researchers in other domains. First, the domain expert can select an image and a term of interest. Then, the pipeline uses image retrieval to find all images showing similar contents and applies aspect-based sentiment analysis to outline users' opinions about the selected term. As part of an interdisciplinary project between architecture and computer science researchers, an empirical study of Hamburg's Elbphilharmonie was conveyed on 300 thousand posts from the platform Flickr with the hashtag 'hamburg'. Image retrieval methods generated a subset of slightly more than 1.5 thousand images displaying the Elbphilharmonie. We found that these posts mainly convey a neutral or positive sentiment towards it. With this pipeline, we suggest a new big data analysis method that offers new insights into end-users opinions, e.g., for architecture domain experts.
Introducing an Abusive Language Classification Framework for Telegram to Investigate the German Hater Community
Sep 15, 2021
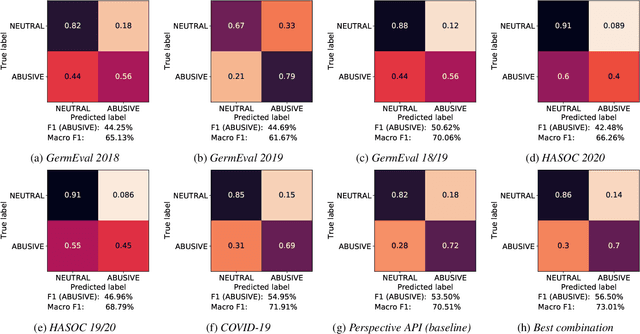


Since traditional social media platforms ban more and more actors that distribute hate speech or other forms of abusive language (deplatforming), these actors migrate to alternative platforms that do not moderate the users' content. One known platform that is relevant for the German hater community is Telegram, for which there have only been made limited research efforts so far. The goal of this study is to develop a broad framework that consists of (i) an abusive language classification model for German Telegram messages and (ii) a classification model for the hatefulness of Telegram channels. For the first part, we employ existing abusive language datasets containing posts from other platforms to build our classification models. For the channel classification model, we develop a method that combines channel specific content information coming from a topic model with a social graph to predict the hatefulness of channels. Furthermore, we complement these two approaches for hate speech detection with insightful results on the evolution of the hater community on Telegram in Germany. Moreover, we propose methods to the hate speech research community for scalable network analyses for social media platforms. As an additional output of the study, we release an annotated abusive language dataset containing 1,149 annotated Telegram messages.
Anchor-based Bilingual Word Embeddings for Low-Resource Languages
Oct 23, 2020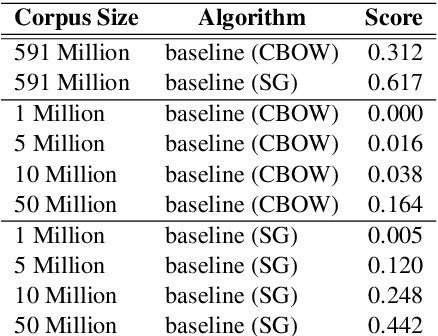
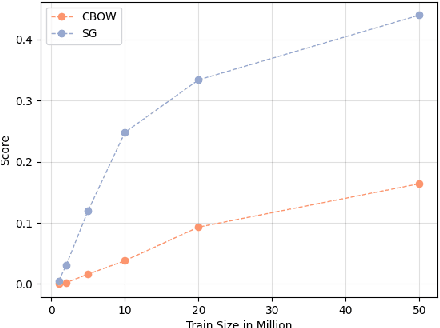
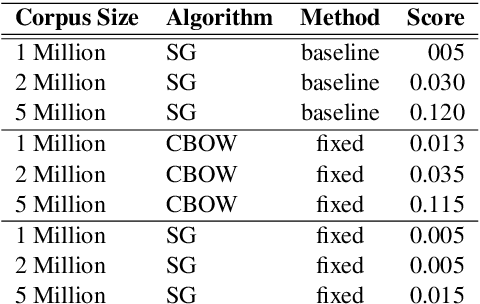
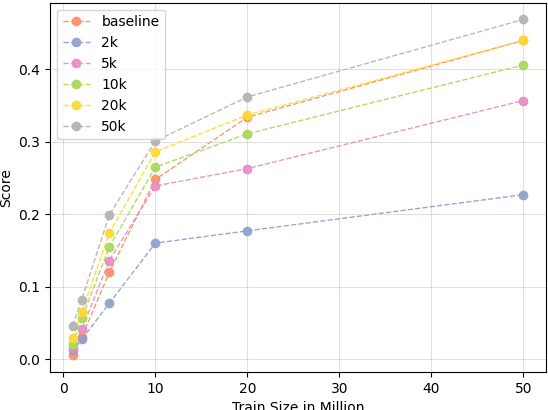
Bilingual word embeddings (BWEs) are useful for many cross-lingual applications, such as bilingual lexicon induction (BLI) and cross-lingual transfer learning. While recent methods have led to good quality BWEs for different language pairs using only weak bilingual signals, they still rely on an abundance of monolingual training data in both languages for their performance. This becomes a problem especially in the case of low resource languages where neither parallel bilingual corpora nor large monolingual training data are available. This paper proposes a new approach for building BWEs in which the vector space of the high resource source language is used as a starting point for training an embedding space for the low resource target language. By using the source vectors as anchors the vector spaces are automatically aligned. We evaluate the resulting BWEs on BLI and show the proposed method outperforms previous approaches in the low-resource setting by a large margin. We show strong results on the standard English-German test pair (using German to simulate low resource). We also show we can build useful BWEs for English-Hiligaynon, a true low-resource language, where previous approaches failed.