 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Annotator Bias Approximation on Crowdsourced Single-Label Sentiment Analysis
Nov 03, 2021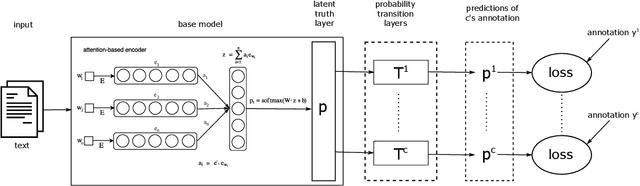
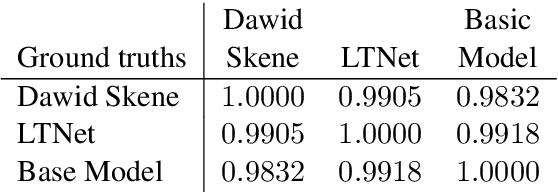
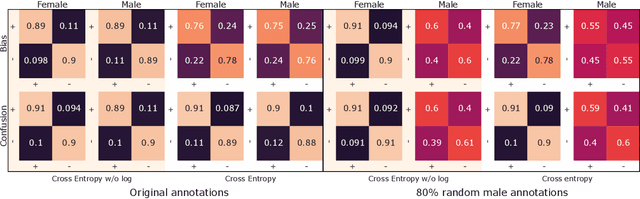
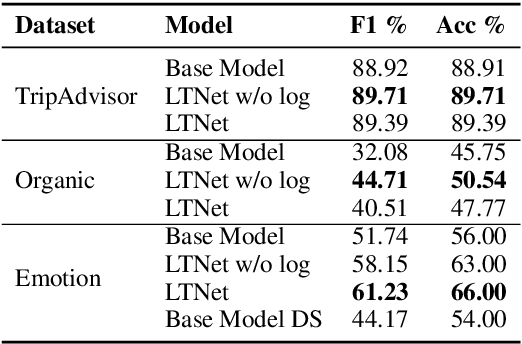
Sentiment analysis is often a crowdsourcing task prone to subjective labels given by many annotators. It is not yet fully understood how the annotation bias of each annotator can be modeled correctly with state-of-the-art methods. However, resolving annotator bias precisely and reliably is the key to understand annotators' labeling behavior and to successfully resolve corresponding individual misconceptions and wrongdoings regarding the annotation task. Our contribution is an explanation and improvement for precise neural end-to-end bias modeling and ground truth estimation, which reduces an undesired mismatch in that regard of the existing state-of-the-art. Classification experiments show that it has potential to improve accuracy in cases where each sample is annotated only by one single annotator. We provide the whole source code publicly and release an own domain-specific sentiment dataset containing 10,000 sentences discussing organic food products. These are crawled from social media and are singly labeled by 10 non-expert annotators.
* 10 pages, 2 figures, 2 tables, full conference paper, peer-reviewed
Introducing an Abusive Language Classification Framework for Telegram to Investigate the German Hater Community
Sep 15, 2021
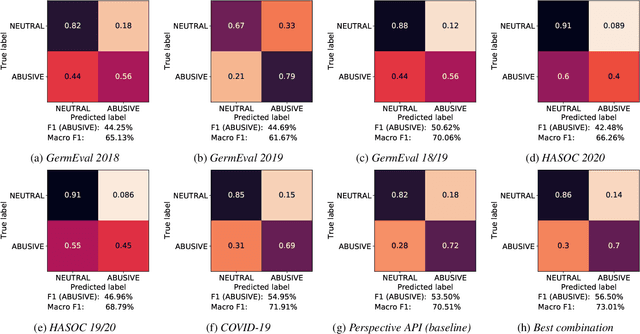


Since traditional social media platforms ban more and more actors that distribute hate speech or other forms of abusive language (deplatforming), these actors migrate to alternative platforms that do not moderate the users' content. One known platform that is relevant for the German hater community is Telegram, for which there have only been made limited research efforts so far. The goal of this study is to develop a broad framework that consists of (i) an abusive language classification model for German Telegram messages and (ii) a classification model for the hatefulness of Telegram channels. For the first part, we employ existing abusive language datasets containing posts from other platforms to build our classification models. For the channel classification model, we develop a method that combines channel specific content information coming from a topic model with a social graph to predict the hatefulness of channels. Furthermore, we complement these two approaches for hate speech detection with insightful results on the evolution of the hater community on Telegram in Germany. Moreover, we propose methods to the hate speech research community for scalable network analyses for social media platforms. As an additional output of the study, we release an annotated abusive language dataset containing 1,149 annotated Telegram messages.