 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA survey on FPGA-based accelerator for ML models
Dec 20, 2024This paper thoroughly surveys machine learning (ML) algorithms acceleration in hardware accelerators, focusing on Field-Programmable Gate Arrays (FPGAs). It reviews 287 out of 1138 papers from the past six years, sourced from four top FPGA conferences. Such selection underscores the increasing integration of ML and FPGA technologies and their mutual importance in technological advancement. Research clearly emphasises inference acceleration (81\%) compared to training acceleration (13\%). Additionally, the findings reveals that CNN dominates current FPGA acceleration research while emerging models like GNN show obvious growth trends. The categorization of the FPGA research papers reveals a wide range of topics, demonstrating the growing relevance of ML in FPGA research. This comprehensive analysis provides valuable insights into the current trends and future directions of FPGA research in the context of ML applications.
End-to-End Annotator Bias Approximation on Crowdsourced Single-Label Sentiment Analysis
Nov 03, 2021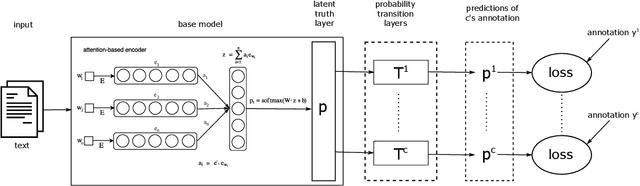
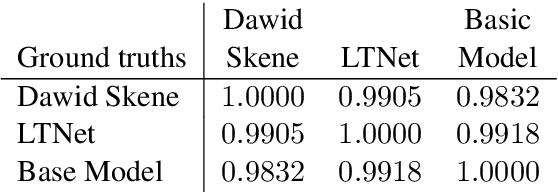
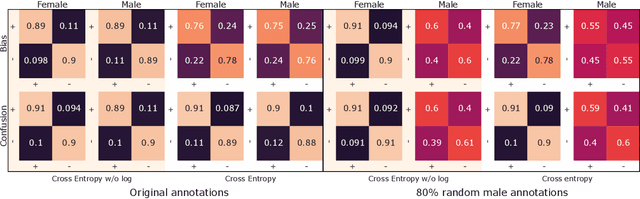
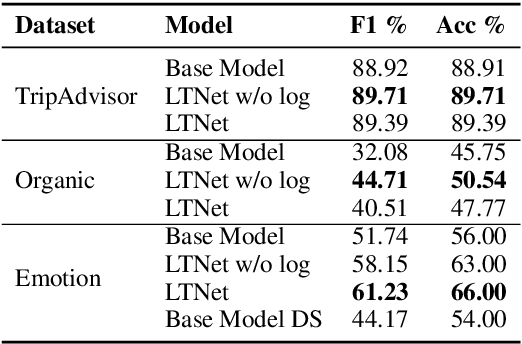
Sentiment analysis is often a crowdsourcing task prone to subjective labels given by many annotators. It is not yet fully understood how the annotation bias of each annotator can be modeled correctly with state-of-the-art methods. However, resolving annotator bias precisely and reliably is the key to understand annotators' labeling behavior and to successfully resolve corresponding individual misconceptions and wrongdoings regarding the annotation task. Our contribution is an explanation and improvement for precise neural end-to-end bias modeling and ground truth estimation, which reduces an undesired mismatch in that regard of the existing state-of-the-art. Classification experiments show that it has potential to improve accuracy in cases where each sample is annotated only by one single annotator. We provide the whole source code publicly and release an own domain-specific sentiment dataset containing 10,000 sentences discussing organic food products. These are crawled from social media and are singly labeled by 10 non-expert annotators.
* 10 pages, 2 figures, 2 tables, full conference paper, peer-reviewed
Explainable Online Validation of Machine Learning Models for Practical Applications
Oct 30, 2020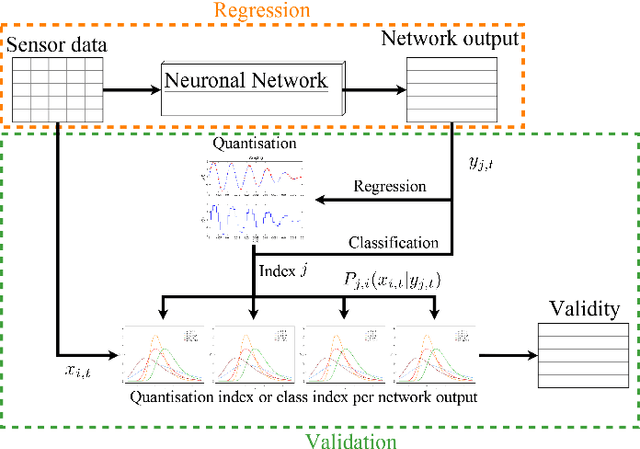
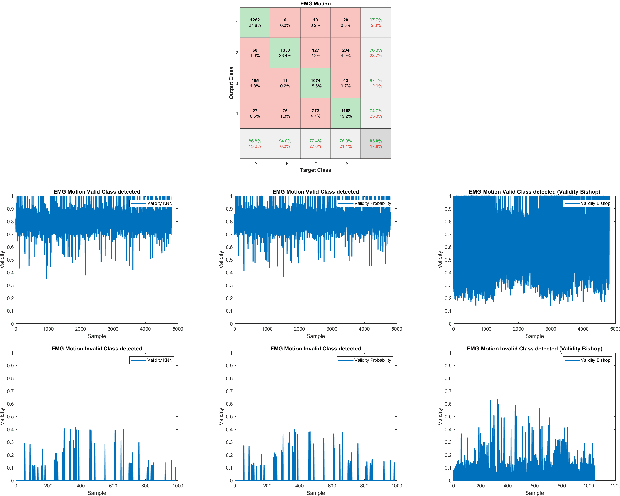
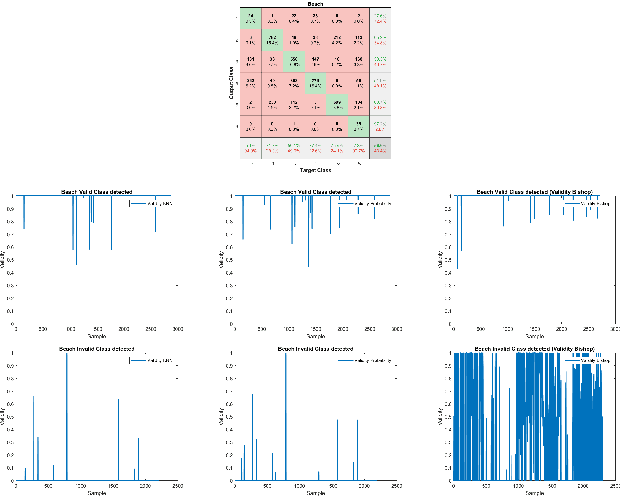
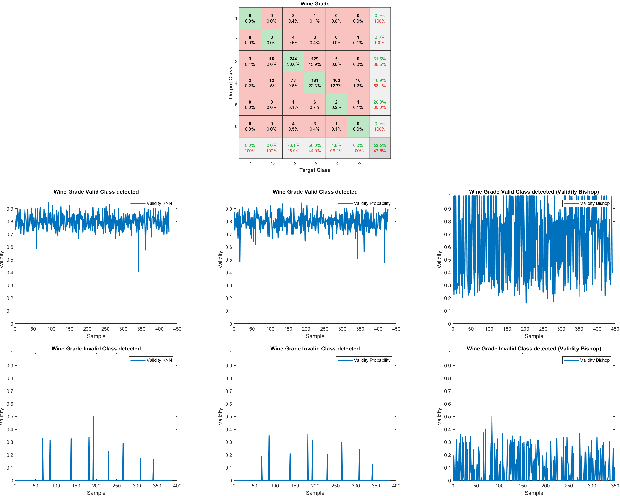
We present a reformulation of the regression and classification, which aims to validate the result of a machine learning algorithm. Our reformulation simplifies the original problem and validates the result of the machine learning algorithm using the training data. Since the validation of machine learning algorithms must always be explainable, we perform our experiments with the kNN algorithm as well as with an algorithm based on conditional probabilities, which is proposed in this work. For the evaluation of our approach, three publicly available data sets were used and three classification and two regression problems were evaluated. The presented algorithm based on conditional probabilities is also online capable and requires only a fraction of memory compared to the kNN algorithm.