 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Trainable Feature Extractor Module for Deep Neural Networks and Scanpath Classification
Mar 19, 2024Scanpath classification is an area in eye tracking research with possible applications in medicine, manufacturing as well as training systems for students in various domains. In this paper we propose a trainable feature extraction module for deep neural networks. The purpose of this module is to transform a scanpath into a feature vector which is directly useable for the deep neural network architecture. Based on the backpropagated error of the deep neural network, the feature extraction module adapts its parameters to improve the classification performance. Therefore, our feature extraction module is jointly trainable with the deep neural network. The motivation to this feature extraction module is based on classical histogram-based approaches which usually compute distributions over a scanpath. We evaluated our module on three public datasets and compared it to the state of the art approaches.
Normalized Validity Scores for DNNs in Regression based Eye Feature Extraction
Mar 18, 2024We propose an improvement to the landmark validity loss. Landmark detection is widely used in head pose estimation, eyelid shape extraction, as well as pupil and iris segmentation. There are numerous additional applications where landmark detection is used to estimate the shape of complex objects. One part of this process is the accurate and fine-grained detection of the shape. The other part is the validity or inaccuracy per landmark, which can be used to detect unreliable areas, where the shape possibly does not fit, and to improve the accuracy of the entire shape extraction by excluding inaccurate landmarks. We propose a normalization in the loss formulation, which improves the accuracy of the entire approach due to the numerical balance of the normalized inaccuracy. In addition, we propose a margin for the inaccuracy to reduce the impact of gradients, which are produced by negligible errors close to the ground truth.
An Initialization Schema for Neuronal Networks on Tabular Data
Nov 07, 2023



Nowadays, many modern applications require heterogeneous tabular data, which is still a challenging task in terms of regression and classification. Many approaches have been proposed to adapt neural networks for this task, but still, boosting and bagging of decision trees are the best-performing methods for this task. In this paper, we show that a binomial initialized neural network can be used effectively on tabular data. The proposed approach shows a simple but effective approach for initializing the first hidden layer in neural networks. We also show that this initializing schema can be used to jointly train ensembles by adding gradient masking to batch entries and using the binomial initialization for the last layer in a neural network. For this purpose, we modified the hinge binary loss and the soft max loss to make them applicable for joint ensemble training. We evaluate our approach on multiple public datasets and showcase the improved performance compared to other neural network-based approaches. In addition, we discuss the limitations and possible further research of our approach for improving the applicability of neural networks to tabular data. Link: https://es-cloud.cs.uni-tuebingen.de/d/8e2ab8c3fdd444e1a135/?p=%2FInitializationNeuronalNetworksTabularData&mode=list
Resource saving taxonomy classification with k-mer distributions and machine learning
Mar 10, 2023Modern high throughput sequencing technologies like metagenomic sequencing generate millions of sequences which have to be classified based on their taxonomic rank. Modern approaches either apply local alignment and comparison to existing data sets like MMseqs2 or use deep neural networks as it is done in DeepMicrobes and BERTax. Alignment-based approaches are costly in terms of runtime, especially since databases get larger and larger. For the deep learning-based approaches, specialized hardware is necessary for a computation, which consumes large amounts of energy. In this paper, we propose to use $k$-mer distributions obtained from DNA as features to classify its taxonomic origin using machine learning approaches like the subspace $k$-nearest neighbors algorithm, neural networks or bagged decision trees. In addition, we propose a feature space data set balancing approach, which allows reducing the data set for training and improves the performance of the classifiers. By comparing performance, time, and memory consumption of our approach to those of state-of-the-art algorithms (BERTax and MMseqs2) using several datasets, we show that our approach improves the classification on the genus level and achieves comparable results for the superkingdom and phylum level. Link: https://es-cloud.cs.uni-tuebingen.de/d/8e2ab8c3fdd444e1a135/?p=%2FTaxonomyClassification&mode=list
One step closer to EEG based eye tracking
Mar 03, 2023


In this paper, we present two approaches and algorithms that adapt areas of interest We present a new deep neural network (DNN) that can be used to directly determine gaze position using EEG data. EEG-based eye tracking is a new and difficult research topic in the field of eye tracking, but it provides an alternative to image-based eye tracking with an input data set comparable to conventional image processing. The presented DNN exploits spatial dependencies of the EEG signal and uses convolutions similar to spatial filtering, which is used for preprocessing EEG signals. By this, we improve the direct gaze determination from the EEG signal compared to the state of the art by 3.5 cm MAE (Mean absolute error), but unfortunately still do not achieve a directly applicable system, since the inaccuracy is still significantly higher compared to image-based eye trackers. Link: https://es-cloud.cs.uni-tuebingen.de/d/8e2ab8c3fdd444e1a135/?p=%2FEEGGaze&mode=list
Multiperspective Teaching of Unknown Objects via Shared-gaze-based Multimodal Human-Robot Interaction
Mar 01, 2023



For successful deployment of robots in multifaceted situations, an understanding of the robot for its environment is indispensable. With advancing performance of state-of-the-art object detectors, the capability of robots to detect objects within their interaction domain is also enhancing. However, it binds the robot to a few trained classes and prevents it from adapting to unfamiliar surroundings beyond predefined scenarios. In such scenarios, humans could assist robots amidst the overwhelming number of interaction entities and impart the requisite expertise by acting as teachers. We propose a novel pipeline that effectively harnesses human gaze and augmented reality in a human-robot collaboration context to teach a robot novel objects in its surrounding environment. By intertwining gaze (to guide the robot's attention to an object of interest) with augmented reality (to convey the respective class information) we enable the robot to quickly acquire a significant amount of automatically labeled training data on its own. Training in a transfer learning fashion, we demonstrate the robot's capability to detect recently learned objects and evaluate the influence of different machine learning models and learning procedures as well as the amount of training data involved. Our multimodal approach proves to be an efficient and natural way to teach the robot novel objects based on a few instances and allows it to detect classes for which no training dataset is available. In addition, we make our dataset publicly available to the research community, which consists of RGB and depth data, intrinsic and extrinsic camera parameters, along with regions of interest.
Technical Report: Combining knowledge from Transfer Learning during training and Wide Resnets
Jun 20, 2022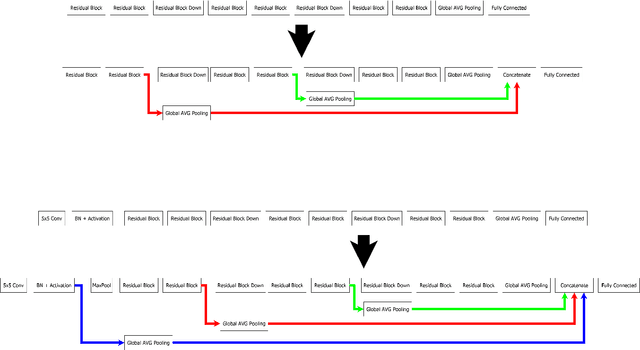


In this report, we combine the idea of Wide ResNets and transfer learning to optimize the architecture of deep neural networks. The first improvement of the architecture is the use of all layers as information source for the last layer. This idea comes from transfer learning, which uses networks pre-trained on other data and extracts different levels of the network as input for the new task. The second improvement is the use of deeper layers instead of deeper sequences of blocks. This idea comes from Wide ResNets. Using both optimizations, both high data augmentation and standard data augmentation can produce better results for different models. Link: https://github.com/wolfgangfuhl/PublicationStuff/tree/master/TechnicalReport1/Supp
Where and What: Driver Attention-based Object Detection
Apr 26, 2022

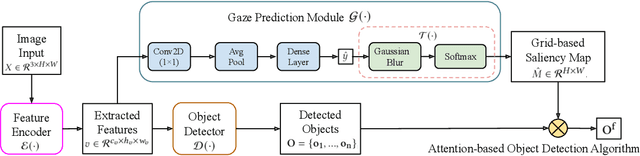

Human drivers use their attentional mechanisms to focus on critical objects and make decisions while driving. As human attention can be revealed from gaze data, capturing and analyzing gaze information has emerged in recent years to benefit autonomous driving technology. Previous works in this context have primarily aimed at predicting "where" human drivers look at and lack knowledge of "what" objects drivers focus on. Our work bridges the gap between pixel-level and object-level attention prediction. Specifically, we propose to integrate an attention prediction module into a pretrained object detection framework and predict the attention in a grid-based style. Furthermore, critical objects are recognized based on predicted attended-to areas. We evaluate our proposed method on two driver attention datasets, BDD-A and DR(eye)VE. Our framework achieves competitive state-of-the-art performance in the attention prediction on both pixel-level and object-level but is far more efficient (75.3 GFLOPs less) in computation.
* 22 pages
Gaze-based Object Detection in the Wild
Mar 29, 2022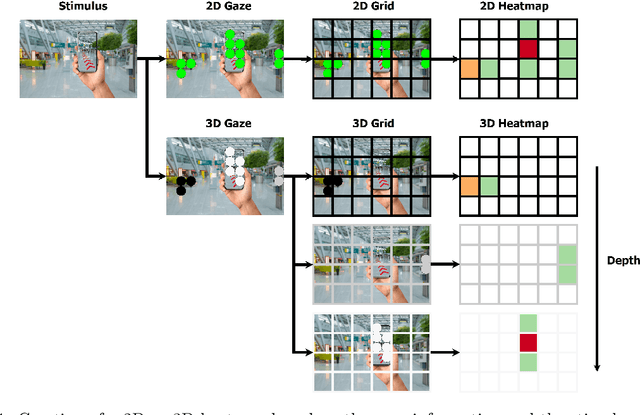
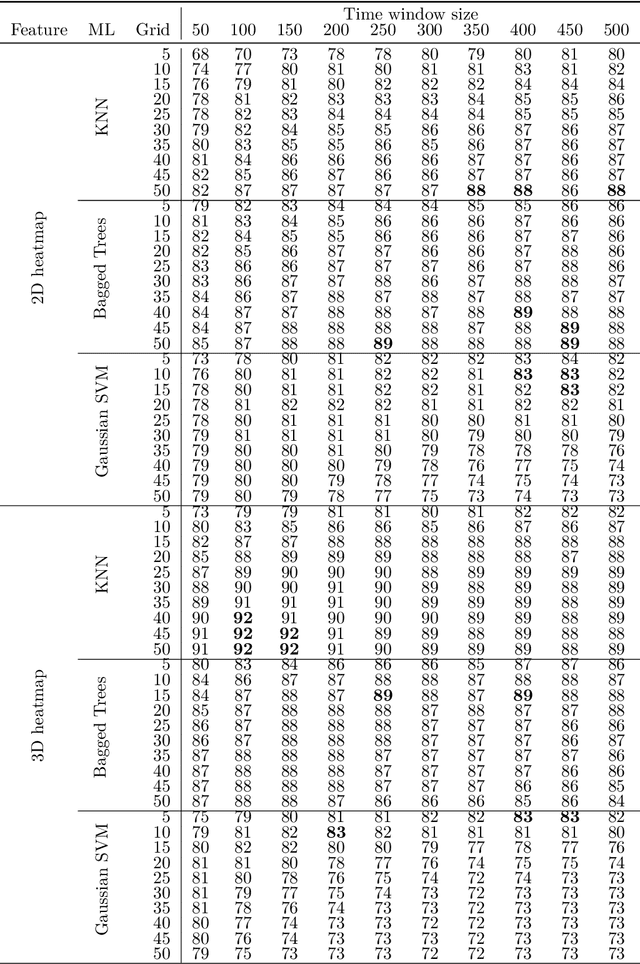
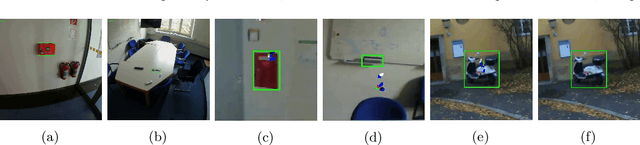
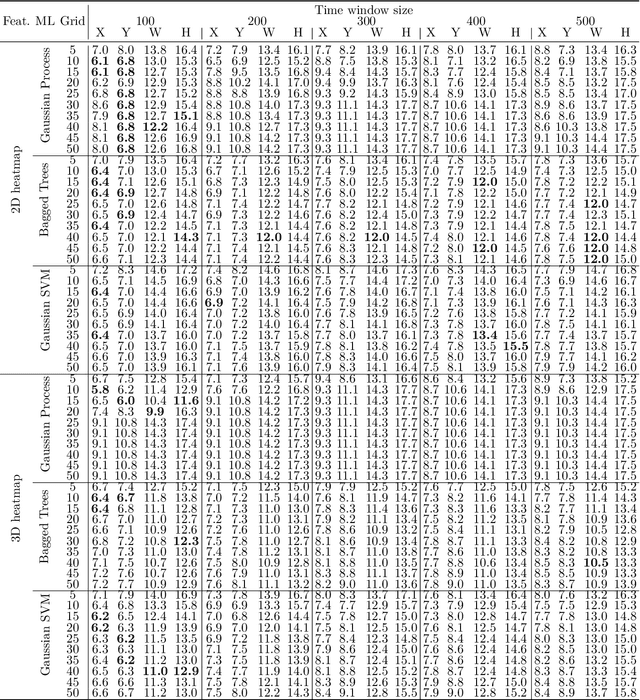
In human-robot collaboration, one challenging task is to teach a robot new yet unknown objects. Thereby, gaze can contain valuable information. We investigate if it is possible to detect objects (object or no object) from gaze data and determine their bounding box parameters. For this purpose, we explore different sizes of temporal windows, which serve as a basis for the computation of heatmaps, i.e., the spatial distribution of the gaze data. Additionally, we analyze different grid sizes of these heatmaps, and various machine learning techniques are applied. To generate the data, we conducted a small study with five subjects who could move freely and thus, turn towards arbitrary objects. This way, we chose a scenario for our data collection that is as realistic as possible. Since the subjects move while facing objects, the heatmaps also contain gaze data trajectories, complicating the detection and parameter regression.
GroupGazer: A Tool to Compute the Gaze per Participant in Groups with integrated Calibration to Map the Gaze Online to a Screen or Beamer Projection
Jan 19, 2022

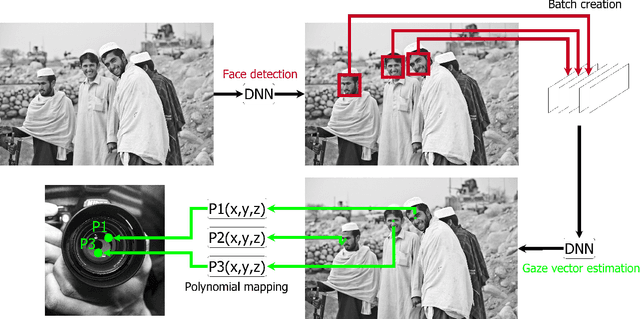

In this paper we present GroupGaze. It is a tool that can be used to calculate the gaze direction and the gaze position of whole groups. GroupGazer calculates the gaze direction of every single person in the image and allows to map these gaze vectors to a projection like a projector. In addition to the person-specific gaze direction, the person affiliation of each gaze vector is stored based on the position in the image. Also, it is possible to save the group attention after a calibration. The software is free to use and requires a simple webcam as well as an NVIDIA GPU and the operating system Windows or Linux.