 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Annotator Bias Approximation on Crowdsourced Single-Label Sentiment Analysis
Nov 03, 2021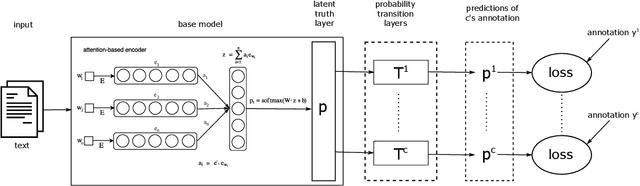
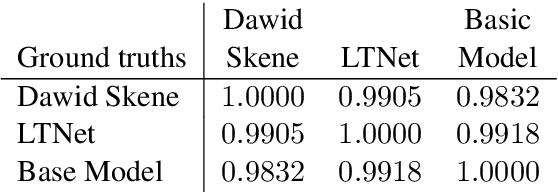
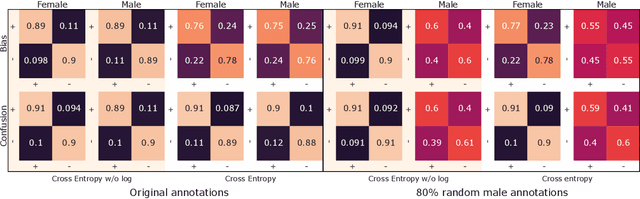
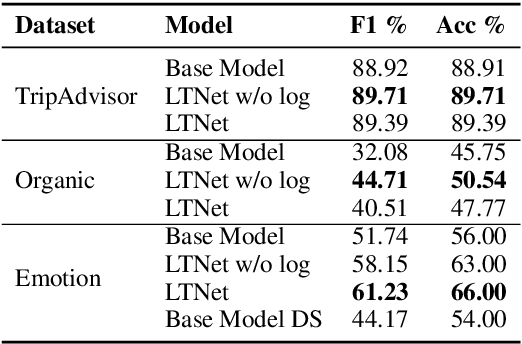
Sentiment analysis is often a crowdsourcing task prone to subjective labels given by many annotators. It is not yet fully understood how the annotation bias of each annotator can be modeled correctly with state-of-the-art methods. However, resolving annotator bias precisely and reliably is the key to understand annotators' labeling behavior and to successfully resolve corresponding individual misconceptions and wrongdoings regarding the annotation task. Our contribution is an explanation and improvement for precise neural end-to-end bias modeling and ground truth estimation, which reduces an undesired mismatch in that regard of the existing state-of-the-art. Classification experiments show that it has potential to improve accuracy in cases where each sample is annotated only by one single annotator. We provide the whole source code publicly and release an own domain-specific sentiment dataset containing 10,000 sentences discussing organic food products. These are crawled from social media and are singly labeled by 10 non-expert annotators.
* 10 pages, 2 figures, 2 tables, full conference paper, peer-reviewed