 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Hate: Differentiating Uncivil and Intolerant Speech in Multimodal Content Moderation
Mar 24, 2026Current multimodal toxicity benchmarks typically use a single binary hatefulness label. This coarse approach conflates two fundamentally different characteristics of expression: tone and content. Drawing on communication science theory, we introduce a fine-grained annotation scheme that distinguishes two separable dimensions: incivility (rude or dismissive tone) and intolerance (content that attacks pluralism and targets groups or identities) and apply it to 2,030 memes from the Hateful Memes dataset. We evaluate different vision-language models under coarse-label training, transfer learning across label schemes and a joint learning approach that combines the coarse hatefulness label with our fine-grained annotations. Our results show that fine-grained annotations complement existing coarse labels and, when used jointly, improve overall model performance. Moreover, models trained with the fine-grained scheme exhibit more balanced moderation-relevant error profiles and are less prone to under-detection of harmful content than models trained on hatefulness labels alone (FNR-FPR, the difference between false negative and false positive rates: 0.74 to 0.42 for LLaVA-1.6-Mistral-7B; 0.54 to 0.28 for Qwen2.5-VL-7B). This work contributes to data-centric approaches in content moderation by improving the reliability and accuracy of moderation systems through enhanced data quality. Overall, combining both coarse and fine-grained labels provides a practical route to more reliable multimodal moderation.
Framework of Thoughts: A Foundation Framework for Dynamic and Optimized Reasoning based on Chains, Trees, and Graphs
Feb 18, 2026Prompting schemes such as Chain of Thought, Tree of Thoughts, and Graph of Thoughts can significantly enhance the reasoning capabilities of large language models. However, most existing schemes require users to define static, problem-specific reasoning structures that lack adaptability to dynamic or unseen problem types. Additionally, these schemes are often under-optimized in terms of hyperparameters, prompts, runtime, and prompting cost. To address these limitations, we introduce Framework of Thoughts (FoT)--a general-purpose foundation framework for building and optimizing dynamic reasoning schemes. FoT comes with built-in features for hyperparameter tuning, prompt optimization, parallel execution, and intelligent caching, unlocking the latent performance potential of reasoning schemes. We demonstrate FoT's capabilities by implementing three popular schemes--Tree of Thoughts, Graph of Thoughts, and ProbTree--within FoT. We empirically show that FoT enables significantly faster execution, reduces costs, and achieves better task scores through optimization. We release our codebase to facilitate the development of future dynamic and efficient reasoning schemes.
Agent2Agent Threats in Safety-Critical LLM Assistants: A Human-Centric Taxonomy
Feb 05, 2026The integration of Large Language Model (LLM)-based conversational agents into vehicles creates novel security challenges at the intersection of agentic AI, automotive safety, and inter-agent communication. As these intelligent assistants coordinate with external services via protocols such as Google's Agent-to-Agent (A2A), they establish attack surfaces where manipulations can propagate through natural language payloads, potentially causing severe consequences ranging from driver distraction to unauthorized vehicle control. Existing AI security frameworks, while foundational, lack the rigorous "separation of concerns" standard in safety-critical systems engineering by co-mingling the concepts of what is being protected (assets) with how it is attacked (attack paths). This paper addresses this methodological gap by proposing a threat modeling framework called AgentHeLLM (Agent Hazard Exploration for LLM Assistants) that formally separates asset identification from attack path analysis. We introduce a human-centric asset taxonomy derived from harm-oriented "victim modeling" and inspired by the Universal Declaration of Human Rights, and a formal graph-based model that distinguishes poison paths (malicious data propagation) from trigger paths (activation actions). We demonstrate the framework's practical applicability through an open-source attack path suggestion tool AgentHeLLM Attack Path Generator that automates multi-stage threat discovery using a bi-level search strategy.
Depth-Recurrent Attention Mixtures: Giving Latent Reasoning the Attention it Deserves
Jan 29, 2026Depth-recurrence facilitates latent reasoning by sharing parameters across depths. However, prior work lacks combined FLOP-, parameter-, and memory-matched baselines, underutilizes depth-recurrence due to partially fixed layer stacks, and ignores the bottleneck of constant hidden-sizes that restricts many-step latent reasoning. To address this, we introduce a modular framework of depth-recurrent attention mixtures (Dreamer), combining sequence attention, depth attention, and sparse expert attention. It alleviates the hidden-size bottleneck through attention along depth, decouples scaling dimensions, and allows depth-recurrent models to scale efficiently and effectively. Across language reasoning benchmarks, our models require 2 to 8x fewer training tokens for the same accuracy as FLOP-, parameter-, and memory-matched SOTA, and outperform ca. 2x larger SOTA models with the same training tokens. We further present insights into knowledge usage across depths, e.g., showing 2 to 11x larger expert selection diversity than SOTA MoEs.
It Depends: Resolving Referential Ambiguity in Minimal Contexts with Commonsense Knowledge
Sep 19, 2025Ambiguous words or underspecified references require interlocutors to resolve them, often by relying on shared context and commonsense knowledge. Therefore, we systematically investigate whether Large Language Models (LLMs) can leverage commonsense to resolve referential ambiguity in multi-turn conversations and analyze their behavior when ambiguity persists. Further, we study how requests for simplified language affect this capacity. Using a novel multilingual evaluation dataset, we test DeepSeek v3, GPT-4o, Qwen3-32B, GPT-4o-mini, and Llama-3.1-8B via LLM-as-Judge and human annotations. Our findings indicate that current LLMs struggle to resolve ambiguity effectively: they tend to commit to a single interpretation or cover all possible references, rather than hedging or seeking clarification. This limitation becomes more pronounced under simplification prompts, which drastically reduce the use of commonsense reasoning and diverse response strategies. Fine-tuning Llama-3.1-8B with Direct Preference Optimization substantially improves ambiguity resolution across all request types. These results underscore the need for advanced fine-tuning to improve LLMs' handling of ambiguity and to ensure robust performance across diverse communication styles.
German4All - A Dataset and Model for Readability-Controlled Paraphrasing in German
Aug 25, 2025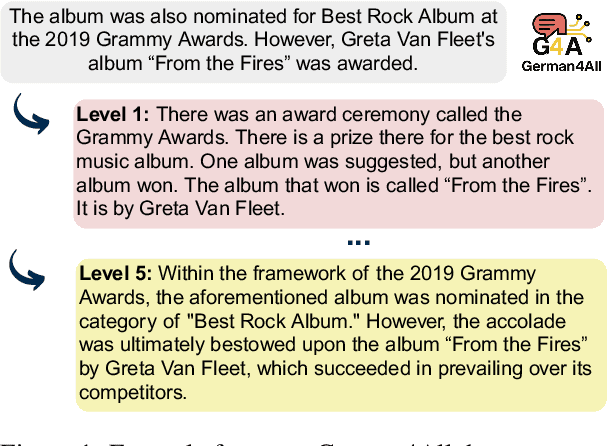

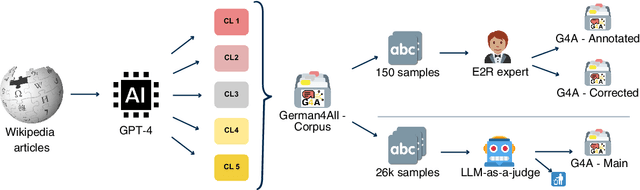
The ability to paraphrase texts across different complexity levels is essential for creating accessible texts that can be tailored toward diverse reader groups. Thus, we introduce German4All, the first large-scale German dataset of aligned readability-controlled, paragraph-level paraphrases. It spans five readability levels and comprises over 25,000 samples. The dataset is automatically synthesized using GPT-4 and rigorously evaluated through both human and LLM-based judgments. Using German4All, we train an open-source, readability-controlled paraphrasing model that achieves state-of-the-art performance in German text simplification, enabling more nuanced and reader-specific adaptations. We opensource both the dataset and the model to encourage further research on multi-level paraphrasing
Simplifications are Absolutists: How Simplified Language Reduces Word Sense Awareness in LLM-Generated Definitions
Jul 16, 2025Large Language Models (LLMs) can provide accurate word definitions and explanations for any context. However, the scope of the definition changes for different target groups, like children or language learners. This is especially relevant for homonyms, words with multiple meanings, where oversimplification might risk information loss by omitting key senses, potentially misleading users who trust LLM outputs. We investigate how simplification impacts homonym definition quality across three target groups: Normal, Simple, and ELI5. Using two novel evaluation datasets spanning multiple languages, we test DeepSeek v3, Llama 4 Maverick, Qwen3-30B A3B, GPT-4o mini, and Llama 3.1 8B via LLM-as-Judge and human annotations. Our results show that simplification drastically degrades definition completeness by neglecting polysemy, increasing the risk of misunderstanding. Fine-tuning Llama 3.1 8B with Direct Preference Optimization substantially improves homonym response quality across all prompt types. These findings highlight the need to balance simplicity and completeness in educational NLP to ensure reliable, context-aware definitions for all learners.
From Knowledge to Noise: CTIM-Rover and the Pitfalls of Episodic Memory in Software Engineering Agents
May 29, 2025We introduce CTIM-Rover, an AI agent for Software Engineering (SE) built on top of AutoCodeRover (Zhang et al., 2024) that extends agentic reasoning frameworks with an episodic memory, more specifically, a general and repository-level Cross-Task-Instance Memory (CTIM). While existing open-source SE agents mostly rely on ReAct (Yao et al., 2023b), Reflexion (Shinn et al., 2023), or Code-Act (Wang et al., 2024), all of these reasoning and planning frameworks inefficiently discard their long-term memory after a single task instance. As repository-level understanding is pivotal for identifying all locations requiring a patch for fixing a bug, we hypothesize that SE is particularly well positioned to benefit from CTIM. For this, we build on the Experiential Learning (EL) approach ExpeL (Zhao et al., 2024), proposing a Mixture-Of-Experts (MoEs) inspired approach to create both a general-purpose and repository-level CTIM. We find that CTIM-Rover does not outperform AutoCodeRover in any configuration and thus conclude that neither ExpeL nor DoT-Bank (Lingam et al., 2024) scale to real-world SE problems. Our analysis indicates noise introduced by distracting CTIM items or exemplar trajectories as the likely source of the performance degradation.
To Bias or Not to Bias: Detecting bias in News with bias-detector
May 19, 2025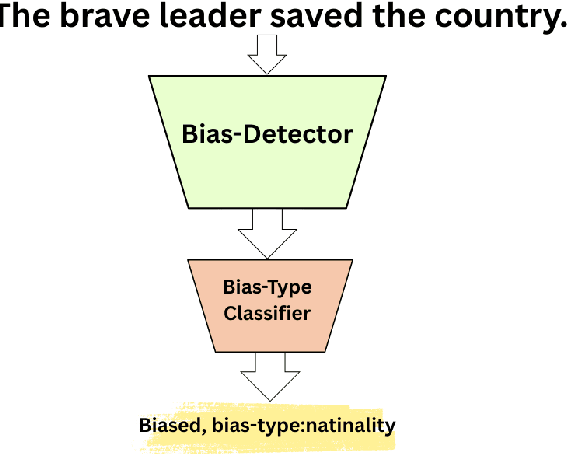



Media bias detection is a critical task in ensuring fair and balanced information dissemination, yet it remains challenging due to the subjectivity of bias and the scarcity of high-quality annotated data. In this work, we perform sentence-level bias classification by fine-tuning a RoBERTa-based model on the expert-annotated BABE dataset. Using McNemar's test and the 5x2 cross-validation paired t-test, we show statistically significant improvements in performance when comparing our model to a domain-adaptively pre-trained DA-RoBERTa baseline. Furthermore, attention-based analysis shows that our model avoids common pitfalls like oversensitivity to politically charged terms and instead attends more meaningfully to contextually relevant tokens. For a comprehensive examination of media bias, we present a pipeline that combines our model with an already-existing bias-type classifier. Our method exhibits good generalization and interpretability, despite being constrained by sentence-level analysis and dataset size because of a lack of larger and more advanced bias corpora. We talk about context-aware modeling, bias neutralization, and advanced bias type classification as potential future directions. Our findings contribute to building more robust, explainable, and socially responsible NLP systems for media bias detection.
Adapter-based Approaches to Knowledge-enhanced Language Models -- A Survey
Nov 25, 2024



Knowledge-enhanced language models (KELMs) have emerged as promising tools to bridge the gap between large-scale language models and domain-specific knowledge. KELMs can achieve higher factual accuracy and mitigate hallucinations by leveraging knowledge graphs (KGs). They are frequently combined with adapter modules to reduce the computational load and risk of catastrophic forgetting. In this paper, we conduct a systematic literature review (SLR) on adapter-based approaches to KELMs. We provide a structured overview of existing methodologies in the field through quantitative and qualitative analysis and explore the strengths and potential shortcomings of individual approaches. We show that general knowledge and domain-specific approaches have been frequently explored along with various adapter architectures and downstream tasks. We particularly focused on the popular biomedical domain, where we provided an insightful performance comparison of existing KELMs. We outline the main trends and propose promising future directions.
* 12 pages, 4 figures. Published at KEOD24 via SciTePress