 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGerman4All - A Dataset and Model for Readability-Controlled Paraphrasing in German
Aug 25, 2025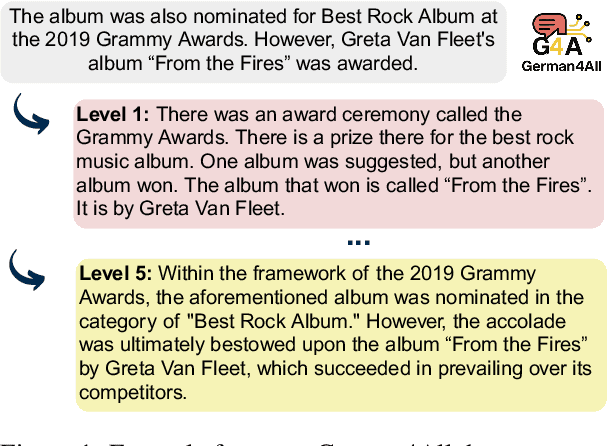

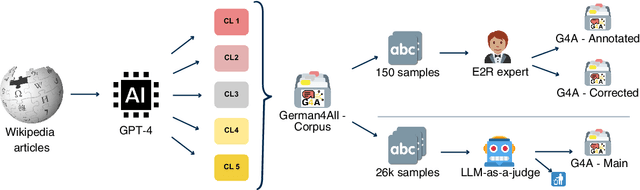
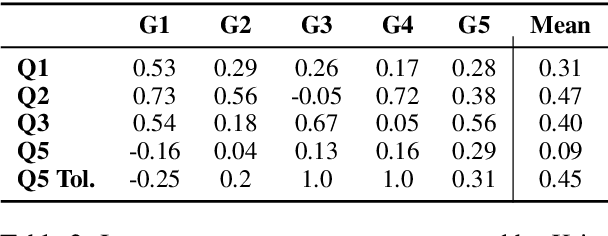
The ability to paraphrase texts across different complexity levels is essential for creating accessible texts that can be tailored toward diverse reader groups. Thus, we introduce German4All, the first large-scale German dataset of aligned readability-controlled, paragraph-level paraphrases. It spans five readability levels and comprises over 25,000 samples. The dataset is automatically synthesized using GPT-4 and rigorously evaluated through both human and LLM-based judgments. Using German4All, we train an open-source, readability-controlled paraphrasing model that achieves state-of-the-art performance in German text simplification, enabling more nuanced and reader-specific adaptations. We opensource both the dataset and the model to encourage further research on multi-level paraphrasing
DigiT4TAF -- Bridging Physical and Digital Worlds for Future Transportation Systems
Jul 03, 2025In the future, mobility will be strongly shaped by the increasing use of digitalization. Not only will individual road users be highly interconnected, but also the road and associated infrastructure. At that point, a Digital Twin becomes particularly appealing because, unlike a basic simulation, it offers a continuous, bilateral connection linking the real and virtual environments. This paper describes the digital reconstruction used to develop the Digital Twin of the Test Area Autonomous Driving-Baden-W\"urttemberg (TAF-BW), Germany. The TAF-BW offers a variety of different road sections, from high-traffic urban intersections and tunnels to multilane motorways. The test area is equipped with a comprehensive Vehicle-to-Everything (V2X) communication infrastructure and multiple intelligent intersections equipped with camera sensors to facilitate real-time traffic flow monitoring. The generation of authentic data as input for the Digital Twin was achieved by extracting object lists at the intersections. This process was facilitated by the combined utilization of camera images from the intelligent infrastructure and LiDAR sensors mounted on a test vehicle. Using a unified interface, recordings from real-world detections of traffic participants can be resimulated. Additionally, the simulation framework's design and the reconstruction process is discussed. The resulting framework is made publicly available for download and utilization at: https://digit4taf-bw.fzi.de The demonstration uses two case studies to illustrate the application of the digital twin and its interfaces: the analysis of traffic signal systems to optimize traffic flow and the simulation of security-related scenarios in the communications sector.
In or Out? Fixing ImageNet Out-of-Distribution Detection Evaluation
Jun 01, 2023



Out-of-distribution (OOD) detection is the problem of identifying inputs which are unrelated to the in-distribution task. The OOD detection performance when the in-distribution (ID) is ImageNet-1K is commonly being tested on a small range of test OOD datasets. We find that most of the currently used test OOD datasets, including datasets from the open set recognition (OSR) literature, have severe issues: In some cases more than 50$\%$ of the dataset contains objects belonging to one of the ID classes. These erroneous samples heavily distort the evaluation of OOD detectors. As a solution, we introduce with NINCO a novel test OOD dataset, each sample checked to be ID free, which with its fine-grained range of OOD classes allows for a detailed analysis of an OOD detector's strengths and failure modes, particularly when paired with a number of synthetic "OOD unit-tests". We provide detailed evaluations across a large set of architectures and OOD detection methods on NINCO and the unit-tests, revealing new insights about model weaknesses and the effects of pretraining on OOD detection performance. We provide code and data at https://github.com/j-cb/NINCO.
A modern look at the relationship between sharpness and generalization
Feb 14, 2023Sharpness of minima is a promising quantity that can correlate with generalization in deep networks and, when optimized during training, can improve generalization. However, standard sharpness is not invariant under reparametrizations of neural networks, and, to fix this, reparametrization-invariant sharpness definitions have been proposed, most prominently adaptive sharpness (Kwon et al., 2021). But does it really capture generalization in modern practical settings? We comprehensively explore this question in a detailed study of various definitions of adaptive sharpness in settings ranging from training from scratch on ImageNet and CIFAR-10 to fine-tuning CLIP on ImageNet and BERT on MNLI. We focus mostly on transformers for which little is known in terms of sharpness despite their widespread usage. Overall, we observe that sharpness does not correlate well with generalization but rather with some training parameters like the learning rate that can be positively or negatively correlated with generalization depending on the setup. Interestingly, in multiple cases, we observe a consistent negative correlation of sharpness with out-of-distribution error implying that sharper minima can generalize better. Finally, we illustrate on a simple model that the right sharpness measure is highly data-dependent, and that we do not understand well this aspect for realistic data distributions. The code of our experiments is available at https://github.com/tml-epfl/sharpness-vs-generalization.