 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranuscore: A Reference-Free Measure of Granularity for Text Analysis and Question Answering
May 26, 2026Natural language conveys information at varying levels of granularity, from fine-grained references to broad descriptions. While granularity is fundamental to human communication, existing measures mostly capture surface detail or sentence specificity. We introduce Granuscore, a reference-free measure of granularity that leverages structural properties of a hierarchical embedding space. Granuscore reliably recovers hierarchical orderings on the Granola-EQ dataset and captures expected differences in granularity across discourse contexts. Across domains, we further show that Granuscore explains non-linear variation in sentence specificity beyond sentence length. Finally, we apply Granuscore to four question-answering benchmarks and analyze how granularity differs for questions, gold answers, and model outputs across response outcomes. The analysis reveals consistent differences in model behavior and provides a principled lens for characterizing the difficulty of QA datasets. Together, the results position Granuscore as a scalable, broadly applicable tool for analyzing granularity in text.
German4All - A Dataset and Model for Readability-Controlled Paraphrasing in German
Aug 25, 2025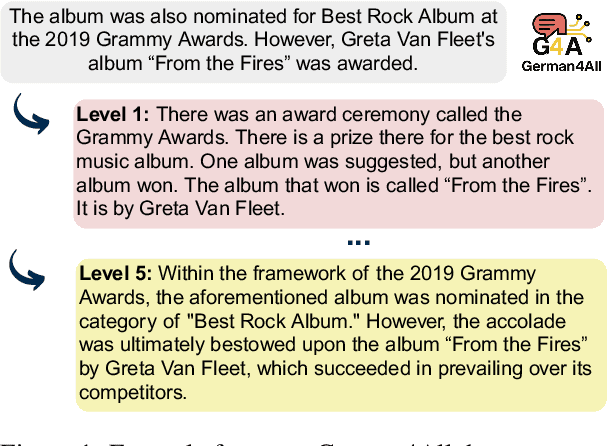

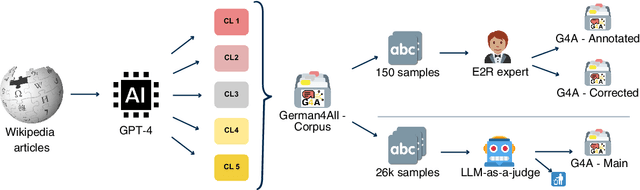
The ability to paraphrase texts across different complexity levels is essential for creating accessible texts that can be tailored toward diverse reader groups. Thus, we introduce German4All, the first large-scale German dataset of aligned readability-controlled, paragraph-level paraphrases. It spans five readability levels and comprises over 25,000 samples. The dataset is automatically synthesized using GPT-4 and rigorously evaluated through both human and LLM-based judgments. Using German4All, we train an open-source, readability-controlled paraphrasing model that achieves state-of-the-art performance in German text simplification, enabling more nuanced and reader-specific adaptations. We opensource both the dataset and the model to encourage further research on multi-level paraphrasing
Simplifications are Absolutists: How Simplified Language Reduces Word Sense Awareness in LLM-Generated Definitions
Jul 16, 2025Large Language Models (LLMs) can provide accurate word definitions and explanations for any context. However, the scope of the definition changes for different target groups, like children or language learners. This is especially relevant for homonyms, words with multiple meanings, where oversimplification might risk information loss by omitting key senses, potentially misleading users who trust LLM outputs. We investigate how simplification impacts homonym definition quality across three target groups: Normal, Simple, and ELI5. Using two novel evaluation datasets spanning multiple languages, we test DeepSeek v3, Llama 4 Maverick, Qwen3-30B A3B, GPT-4o mini, and Llama 3.1 8B via LLM-as-Judge and human annotations. Our results show that simplification drastically degrades definition completeness by neglecting polysemy, increasing the risk of misunderstanding. Fine-tuning Llama 3.1 8B with Direct Preference Optimization substantially improves homonym response quality across all prompt types. These findings highlight the need to balance simplicity and completeness in educational NLP to ensure reliable, context-aware definitions for all learners.
Images Speak Volumes: User-Centric Assessment of Image Generation for Accessible Communication
Oct 04, 2024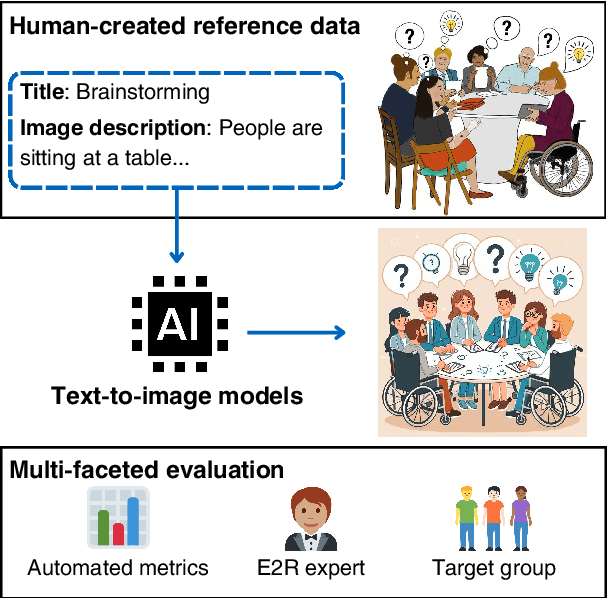
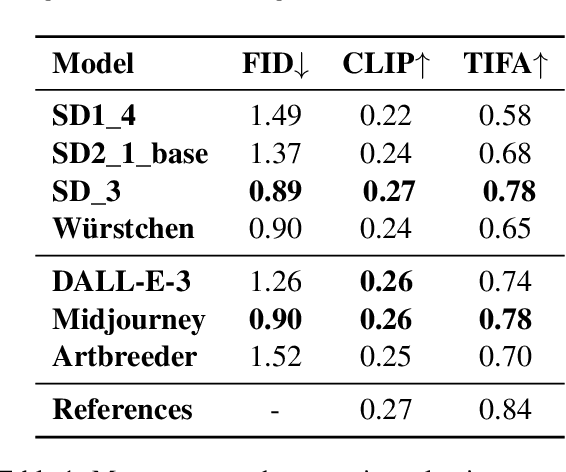

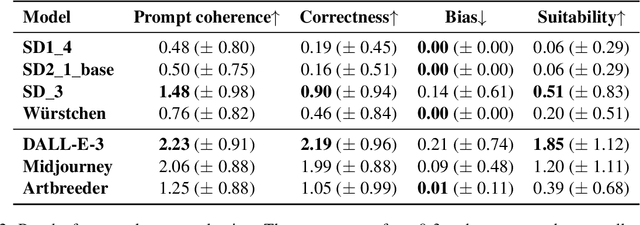
Explanatory images play a pivotal role in accessible and easy-to-read (E2R) texts. However, the images available in online databases are not tailored toward the respective texts, and the creation of customized images is expensive. In this large-scale study, we investigated whether text-to-image generation models can close this gap by providing customizable images quickly and easily. We benchmarked seven, four open- and three closed-source, image generation models and provide an extensive evaluation of the resulting images. In addition, we performed a user study with people from the E2R target group to examine whether the images met their requirements. We find that some of the models show remarkable performance, but none of the models are ready to be used at a larger scale without human supervision. Our research is an important step toward facilitating the creation of accessible information for E2R creators and tailoring accessible images to the target group's needs.
Simpler becomes Harder: Do LLMs Exhibit a Coherent Behavior on Simplified Corpora?
Apr 10, 2024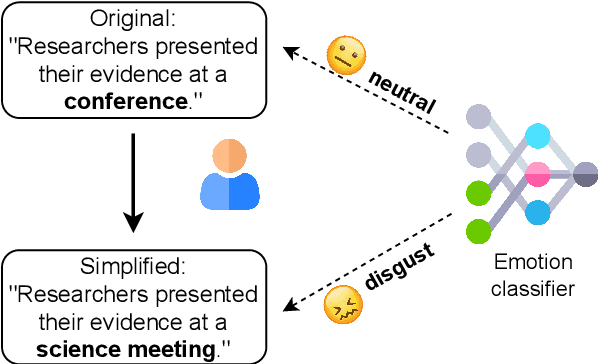
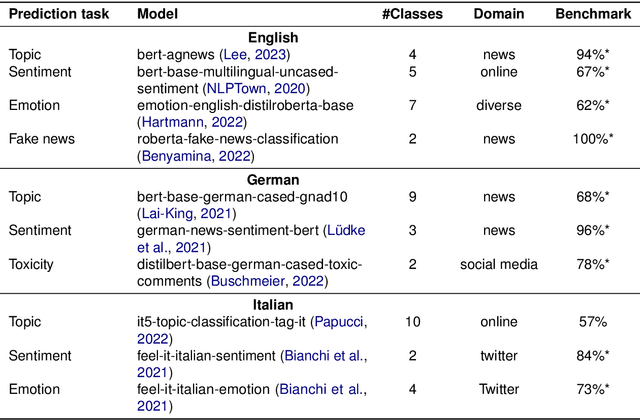

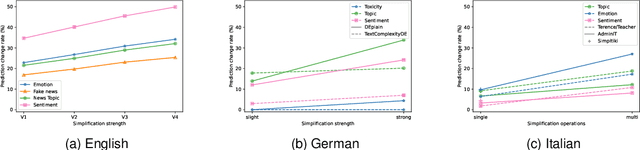
Text simplification seeks to improve readability while retaining the original content and meaning. Our study investigates whether pre-trained classifiers also maintain such coherence by comparing their predictions on both original and simplified inputs. We conduct experiments using 11 pre-trained models, including BERT and OpenAI's GPT 3.5, across six datasets spanning three languages. Additionally, we conduct a detailed analysis of the correlation between prediction change rates and simplification types/strengths. Our findings reveal alarming inconsistencies across all languages and models. If not promptly addressed, simplified inputs can be easily exploited to craft zero-iteration model-agnostic adversarial attacks with success rates of up to 50%
This is not correct! Negation-aware Evaluation of Language Generation Systems
Jul 26, 2023Large language models underestimate the impact of negations on how much they change the meaning of a sentence. Therefore, learned evaluation metrics based on these models are insensitive to negations. In this paper, we propose NegBLEURT, a negation-aware version of the BLEURT evaluation metric. For that, we designed a rule-based sentence negation tool and used it to create the CANNOT negation evaluation dataset. Based on this dataset, we fine-tuned a sentence transformer and an evaluation metric to improve their negation sensitivity. Evaluating these models on existing benchmarks shows that our fine-tuned models outperform existing metrics on the negated sentences by far while preserving their base models' performances on other perturbations.
Language Models for German Text Simplification: Overcoming Parallel Data Scarcity through Style-specific Pre-training
May 22, 2023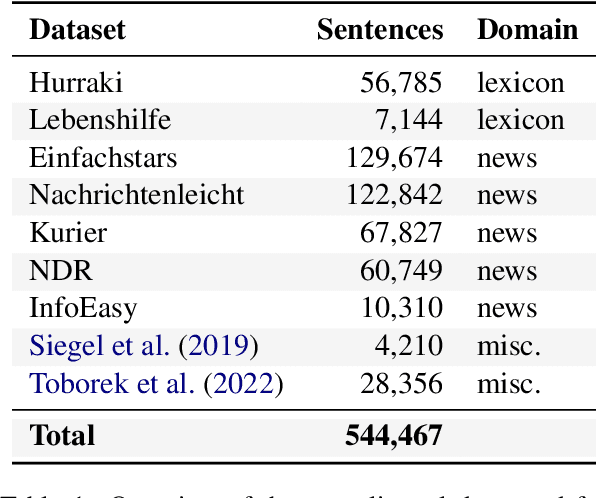
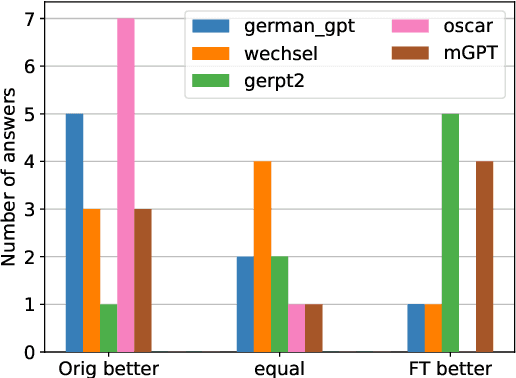
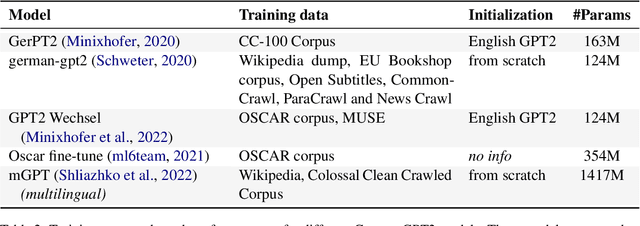
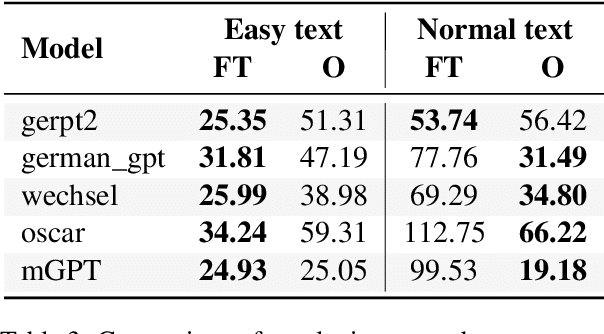
Automatic text simplification systems help to reduce textual information barriers on the internet. However, for languages other than English, only few parallel data to train these systems exists. We propose a two-step approach to overcome this data scarcity issue. First, we fine-tuned language models on a corpus of German Easy Language, a specific style of German. Then, we used these models as decoders in a sequence-to-sequence simplification task. We show that the language models adapt to the style characteristics of Easy Language and output more accessible texts. Moreover, with the style-specific pre-training, we reduced the number of trainable parameters in text simplification models. Hence, less parallel data is sufficient for training. Our results indicate that pre-training on unaligned data can reduce the required parallel data while improving the performance on downstream tasks.
Structuring User-Generated Content on Social Media with Multimodal Aspect-Based Sentiment Analysis
Oct 27, 2022People post their opinions and experiences on social media, yielding rich databases of end users' sentiments. This paper shows to what extent machine learning can analyze and structure these databases. An automated data analysis pipeline is deployed to provide insights into user-generated content for researchers in other domains. First, the domain expert can select an image and a term of interest. Then, the pipeline uses image retrieval to find all images showing similar contents and applies aspect-based sentiment analysis to outline users' opinions about the selected term. As part of an interdisciplinary project between architecture and computer science researchers, an empirical study of Hamburg's Elbphilharmonie was conveyed on 300 thousand posts from the platform Flickr with the hashtag 'hamburg'. Image retrieval methods generated a subset of slightly more than 1.5 thousand images displaying the Elbphilharmonie. We found that these posts mainly convey a neutral or positive sentiment towards it. With this pipeline, we suggest a new big data analysis method that offers new insights into end-users opinions, e.g., for architecture domain experts.
An Analysis of Programming Course Evaluations Before and After the Introduction of an Autograder
Oct 28, 2021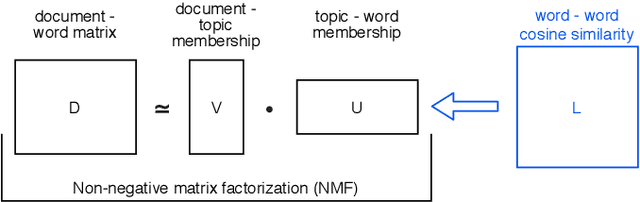
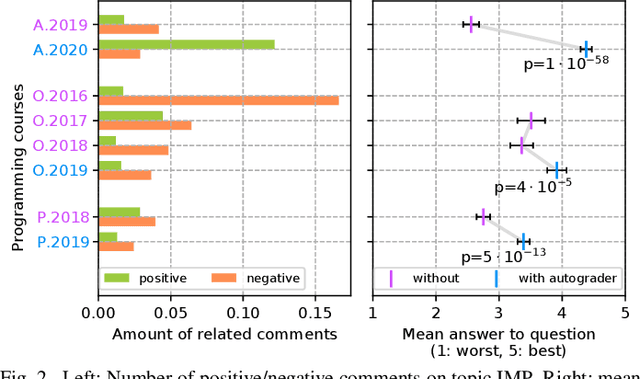
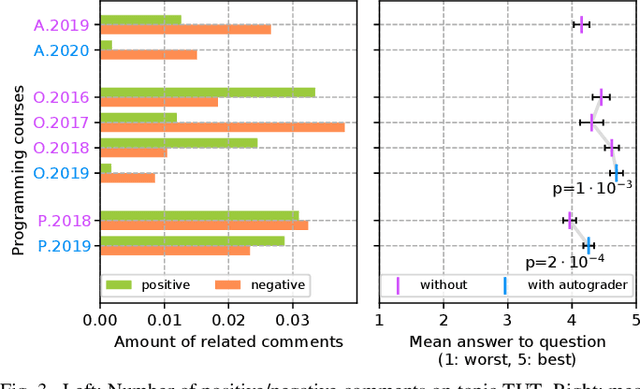
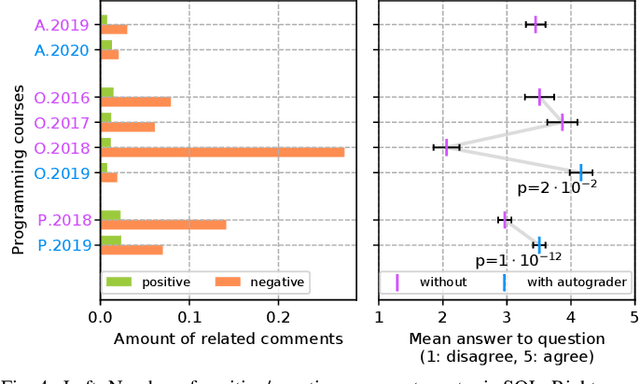
Commonly, introductory programming courses in higher education institutions have hundreds of participating students eager to learn to program. The manual effort for reviewing the submitted source code and for providing feedback can no longer be managed. Manually reviewing the submitted homework can be subjective and unfair, particularly if many tutors are responsible for grading. Different autograders can help in this situation; however, there is a lack of knowledge about how autograders can impact students' overall perception of programming classes and teaching. This is relevant for course organizers and institutions to keep their programming courses attractive while coping with increasing students. This paper studies the answers to the standardized university evaluation questionnaires of multiple large-scale foundational computer science courses which recently introduced autograding. The differences before and after this intervention are analyzed. By incorporating additional observations, we hypothesize how the autograder might have contributed to the significant changes in the data, such as, improved interactions between tutors and students, improved overall course quality, improved learning success, increased time spent, and reduced difficulty. This qualitative study aims to provide hypotheses for future research to define and conduct quantitative surveys and data analysis. The autograder technology can be validated as a teaching method to improve student satisfaction with programming courses.
* Accepted full paper article on IEEE ITHET 2021