 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs versus the Halting Problem: Revisiting Program Termination Prediction
Jan 26, 2026Determining whether a program terminates is a central problem in computer science. Turing's foundational result established the Halting Problem as undecidable, showing that no algorithm can universally determine termination for all programs and inputs. Consequently, automatic verification tools approximate termination, sometimes failing to prove or disprove; these tools rely on problem-specific architectures and abstractions, and are usually tied to particular programming languages. Recent success and progress in large language models (LLMs) raises the following question: can LLMs reliably predict program termination? In this work, we evaluate LLMs on a diverse set of C programs from the Termination category of the International Competition on Software Verification (SV-Comp) 2025. Our results suggest that LLMs perform remarkably well at predicting program termination, where GPT-5 and Claude Sonnet-4.5 would rank just behind the top-ranked tool (using test-time-scaling), and Code World Model (CWM) would place just behind the second-ranked tool. While LLMs are effective at predicting program termination, they often fail to provide a valid witness as a proof. Moreover, LLMs performance drops as program length increases. We hope these insights motivate further research into program termination and the broader potential of LLMs for reasoning about undecidable problems.
Towards Reliable Proof Generation with LLMs: A Neuro-Symbolic Approach
May 20, 2025Large language models (LLMs) struggle with formal domains that require rigorous logical deduction and symbolic reasoning, such as mathematical proof generation. We propose a neuro-symbolic approach that combines LLMs' generative strengths with structured components to overcome this challenge. As a proof-of-concept, we focus on geometry problems. Our approach is two-fold: (1) we retrieve analogous problems and use their proofs to guide the LLM, and (2) a formal verifier evaluates the generated proofs and provides feedback, helping the model fix incorrect proofs. We demonstrate that our method significantly improves proof accuracy for OpenAI's o1 model (58%-70% improvement); both analogous problems and the verifier's feedback contribute to these gains. More broadly, shifting to LLMs that generate provably correct conclusions could dramatically improve their reliability, accuracy and consistency, unlocking complex tasks and critical real-world applications that require trustworthiness.
Visual Editing with LLM-based Tool Chaining: An Efficient Distillation Approach for Real-Time Applications
Oct 03, 2024We present a practical distillation approach to fine-tune LLMs for invoking tools in real-time applications. We focus on visual editing tasks; specifically, we modify images and videos by interpreting user stylistic requests, specified in natural language ("golden hour"), using an LLM to select the appropriate tools and their parameters to achieve the desired visual effect. We found that proprietary LLMs such as GPT-3.5-Turbo show potential in this task, but their high cost and latency make them unsuitable for real-time applications. In our approach, we fine-tune a (smaller) student LLM with guidance from a (larger) teacher LLM and behavioral signals. We introduce offline metrics to evaluate student LLMs. Both online and offline experiments show that our student models manage to match the performance of our teacher model (GPT-3.5-Turbo), significantly reducing costs and latency. Lastly, we show that fine-tuning was improved by 25% in low-data regimes using augmentation.
ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies
Mar 02, 2024


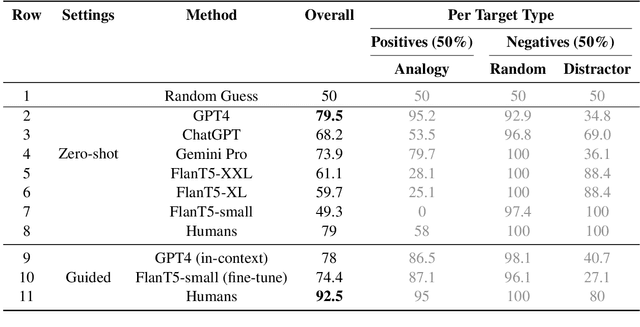
Analogy-making is central to human cognition, allowing us to adapt to novel situations -- an ability that current AI systems still lack. Most analogy datasets today focus on simple analogies (e.g., word analogies); datasets including complex types of analogies are typically manually curated and very small. We believe that this holds back progress in computational analogy. In this work, we design a data generation pipeline, ParallelPARC (Parallel Paragraph Creator) leveraging state-of-the-art Large Language Models (LLMs) to create complex, paragraph-based analogies, as well as distractors, both simple and challenging. We demonstrate our pipeline and create ProPara-Logy, a dataset of analogies between scientific processes. We publish a gold-set, validated by humans, and a silver-set, generated automatically. We test LLMs' and humans' analogy recognition in binary and multiple-choice settings, and found that humans outperform the best models (~13% gap) after a light supervision. We demonstrate that our silver-set is useful for training models. Lastly, we show challenging distractors confuse LLMs, but not humans. We hope our pipeline will encourage research in this emerging field.
From Judgement's Premises Towards Key Points
Dec 23, 2022Key Point Analysis(KPA) is a relatively new task in NLP that combines summarization and classification by extracting argumentative key points (KPs) for a topic from a collection of texts and categorizing their closeness to the different arguments. In our work, we focus on the legal domain and develop methods that identify and extract KPs from premises derived from texts of judgments. The first method is an adaptation to an existing state-of-the-art method, and the two others are new methods that we developed from scratch. We present our methods and examples of their outputs, as well a comparison between them. The full evaluation of our results is done in the matching task -- match between the generated KPs to arguments (premises).
Breakpoint Transformers for Modeling and Tracking Intermediate Beliefs
Nov 15, 2022



Can we teach natural language understanding models to track their beliefs through intermediate points in text? We propose a representation learning framework called breakpoint modeling that allows for learning of this type. Given any text encoder and data marked with intermediate states (breakpoints) along with corresponding textual queries viewed as true/false propositions (i.e., the candidate beliefs of a model, consisting of information changing through time) our approach trains models in an efficient and end-to-end fashion to build intermediate representations that facilitate teaching and direct querying of beliefs at arbitrary points alongside solving other end tasks. To show the benefit of our approach, we experiment with a diverse set of NLU tasks including relational reasoning on CLUTRR and narrative understanding on bAbI. Using novel belief prediction tasks for both tasks, we show the benefit of our main breakpoint transformer, based on T5, over conventional representation learning approaches in terms of processing efficiency, prediction accuracy and prediction consistency, all with minimal to no effect on corresponding QA end tasks. To show the feasibility of incorporating our belief tracker into more complex reasoning pipelines, we also obtain SOTA performance on the three-tiered reasoning challenge for the TRIP benchmark (around 23-32% absolute improvement on Tasks 2-3).