 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditInspector: A Benchmark for Evaluation of Text-Guided Image Edits
Jun 11, 2025Text-guided image editing, fueled by recent advancements in generative AI, is becoming increasingly widespread. This trend highlights the need for a comprehensive framework to verify text-guided edits and assess their quality. To address this need, we introduce EditInspector, a novel benchmark for evaluation of text-guided image edits, based on human annotations collected using an extensive template for edit verification. We leverage EditInspector to evaluate the performance of state-of-the-art (SoTA) vision and language models in assessing edits across various dimensions, including accuracy, artifact detection, visual quality, seamless integration with the image scene, adherence to common sense, and the ability to describe edit-induced changes. Our findings indicate that current models struggle to evaluate edits comprehensively and frequently hallucinate when describing the changes. To address these challenges, we propose two novel methods that outperform SoTA models in both artifact detection and difference caption generation.
ParallelPARC: A Scalable Pipeline for Generating Natural-Language Analogies
Mar 02, 2024


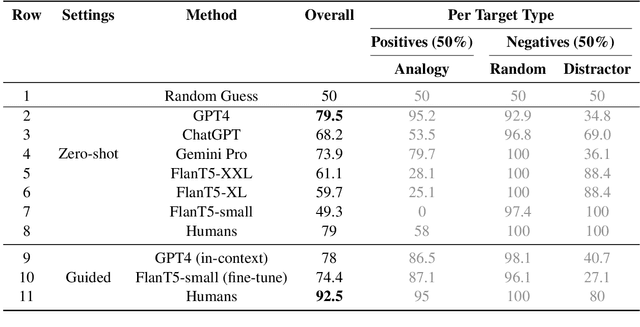
Analogy-making is central to human cognition, allowing us to adapt to novel situations -- an ability that current AI systems still lack. Most analogy datasets today focus on simple analogies (e.g., word analogies); datasets including complex types of analogies are typically manually curated and very small. We believe that this holds back progress in computational analogy. In this work, we design a data generation pipeline, ParallelPARC (Parallel Paragraph Creator) leveraging state-of-the-art Large Language Models (LLMs) to create complex, paragraph-based analogies, as well as distractors, both simple and challenging. We demonstrate our pipeline and create ProPara-Logy, a dataset of analogies between scientific processes. We publish a gold-set, validated by humans, and a silver-set, generated automatically. We test LLMs' and humans' analogy recognition in binary and multiple-choice settings, and found that humans outperform the best models (~13% gap) after a light supervision. We demonstrate that our silver-set is useful for training models. Lastly, we show challenging distractors confuse LLMs, but not humans. We hope our pipeline will encourage research in this emerging field.
IRFL: Image Recognition of Figurative Language
Mar 27, 2023
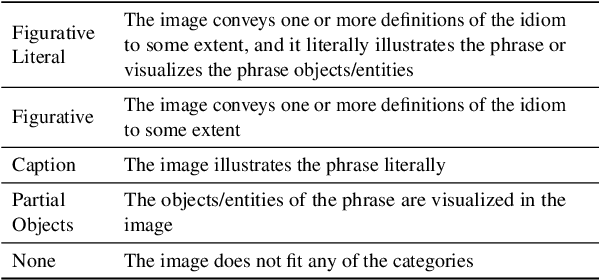


Figures of speech such as metaphors, similes, and idioms allow language to be expressive, invoke emotion, and communicate abstract ideas that might otherwise be difficult to visualize. These figurative forms are often conveyed through multiple modes, such as text and images, and frequently appear in advertising, news, social media, etc. Understanding multimodal figurative language is an essential component of human communication, and it plays a significant role in our daily interactions. While humans can intuitively understand multimodal figurative language, this poses a challenging task for machines that requires the cognitive ability to map between domains, abstraction, commonsense, and profound language and cultural knowledge. In this work, we propose the Image Recognition of Figurative Language dataset to examine vision and language models' understanding of figurative language. We leverage human annotation and an automatic pipeline we created to generate a multimodal dataset and introduce two novel tasks as a benchmark for multimodal figurative understanding. We experiment with several baseline models and find that all perform substantially worse than humans. We hope our dataset and benchmark will drive the development of models that will better understand figurative language.
VASR: Visual Analogies of Situation Recognition
Dec 08, 2022



A core process in human cognition is analogical mapping: the ability to identify a similar relational structure between different situations. We introduce a novel task, Visual Analogies of Situation Recognition, adapting the classical word-analogy task into the visual domain. Given a triplet of images, the task is to select an image candidate B' that completes the analogy (A to A' is like B to what?). Unlike previous work on visual analogy that focused on simple image transformations, we tackle complex analogies requiring understanding of scenes. We leverage situation recognition annotations and the CLIP model to generate a large set of 500k candidate analogies. Crowdsourced annotations for a sample of the data indicate that humans agree with the dataset label ~80% of the time (chance level 25%). Furthermore, we use human annotations to create a gold-standard dataset of 3,820 validated analogies. Our experiments demonstrate that state-of-the-art models do well when distractors are chosen randomly (~86%), but struggle with carefully chosen distractors (~53%, compared to 90% human accuracy). We hope our dataset will encourage the development of new analogy-making models. Website: https://vasr-dataset.github.io/
WinoGAViL: Gamified Association Benchmark to Challenge Vision-and-Language Models
Jul 25, 2022



While vision-and-language models perform well on tasks such as visual question answering, they struggle when it comes to basic human commonsense reasoning skills. In this work, we introduce WinoGAViL: an online game to collect vision-and-language associations, (e.g., werewolves to a full moon), used as a dynamic benchmark to evaluate state-of-the-art models. Inspired by the popular card game Codenames, a spymaster gives a textual cue related to several visual candidates, and another player has to identify them. Human players are rewarded for creating associations that are challenging for a rival AI model but still solvable by other human players. We use the game to collect 3.5K instances, finding that they are intuitive for humans (>90% Jaccard index) but challenging for state-of-the-art AI models, where the best model (ViLT) achieves a score of 52%, succeeding mostly where the cue is visually salient. Our analysis as well as the feedback we collect from players indicate that the collected associations require diverse reasoning skills, including general knowledge, common sense, abstraction, and more. We release the dataset, the code and the interactive game, aiming to allow future data collection that can be used to develop models with better association abilities.